以手机的算力能运行本地大模型吗?
可以是可以,但手机本地部署只能跑小模型(建议9B以下),且体验一般(主要是发热和耗电),作用有限(现阶段只能玩玩)。
以 iPhone 17 Pro(A19 Pro芯片 + 12GB运存)为例:
通过 PocketPal AI 软件在手机上本地部署大模型,其中:
PocketPal AI 国内 App Store 即可直接搜索下载;
AI大模型可通过LM Studio下载,下载后是 .GGUF 格式,可在 PocketPal AI 软件中直接本地添加。
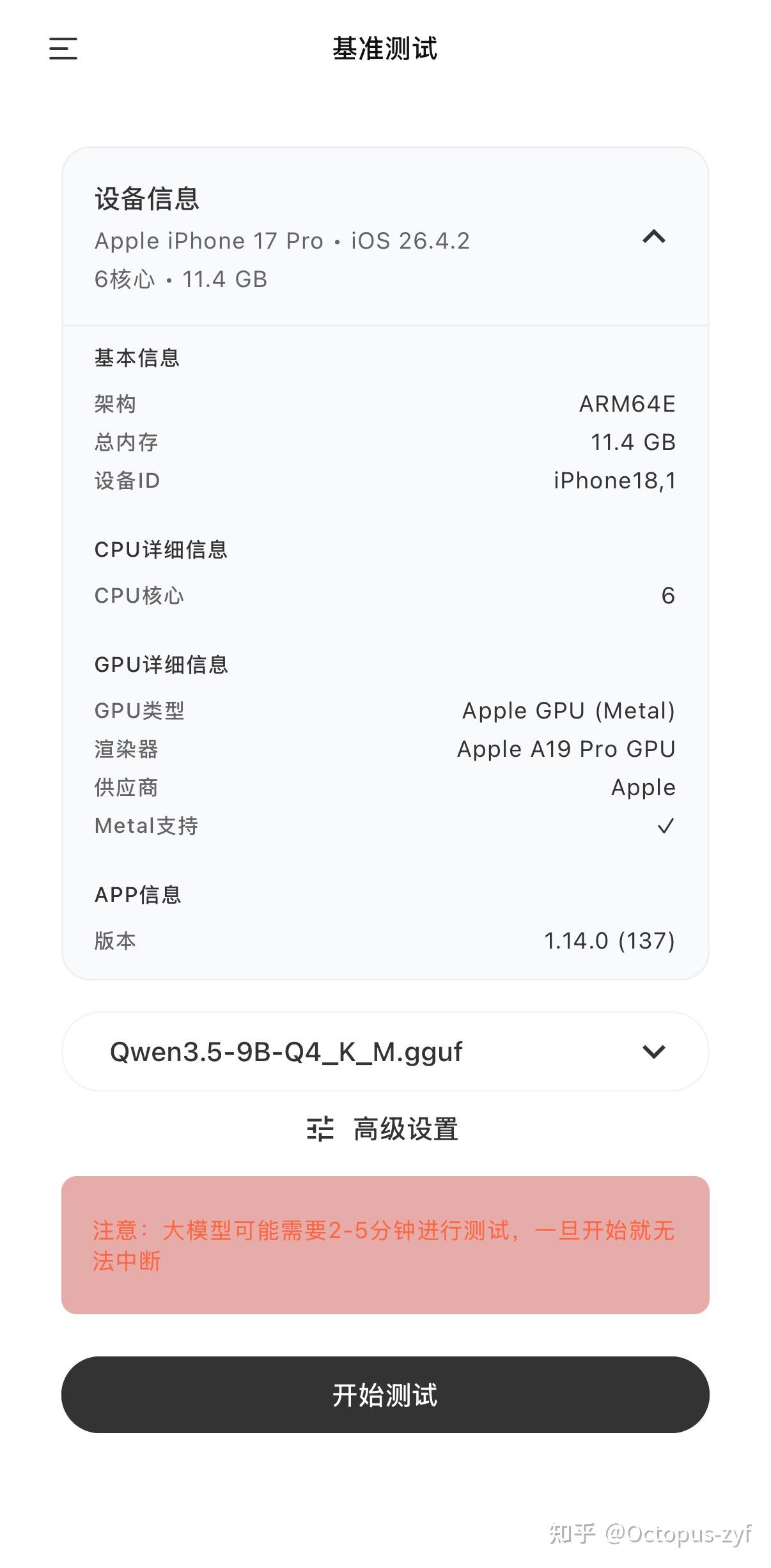
通过 PocketPal Ai 软件自带的基准测试功能进行测试,
设置中选择CPU线程和GPU层数拉满(CPU线程6,GPU层数99),
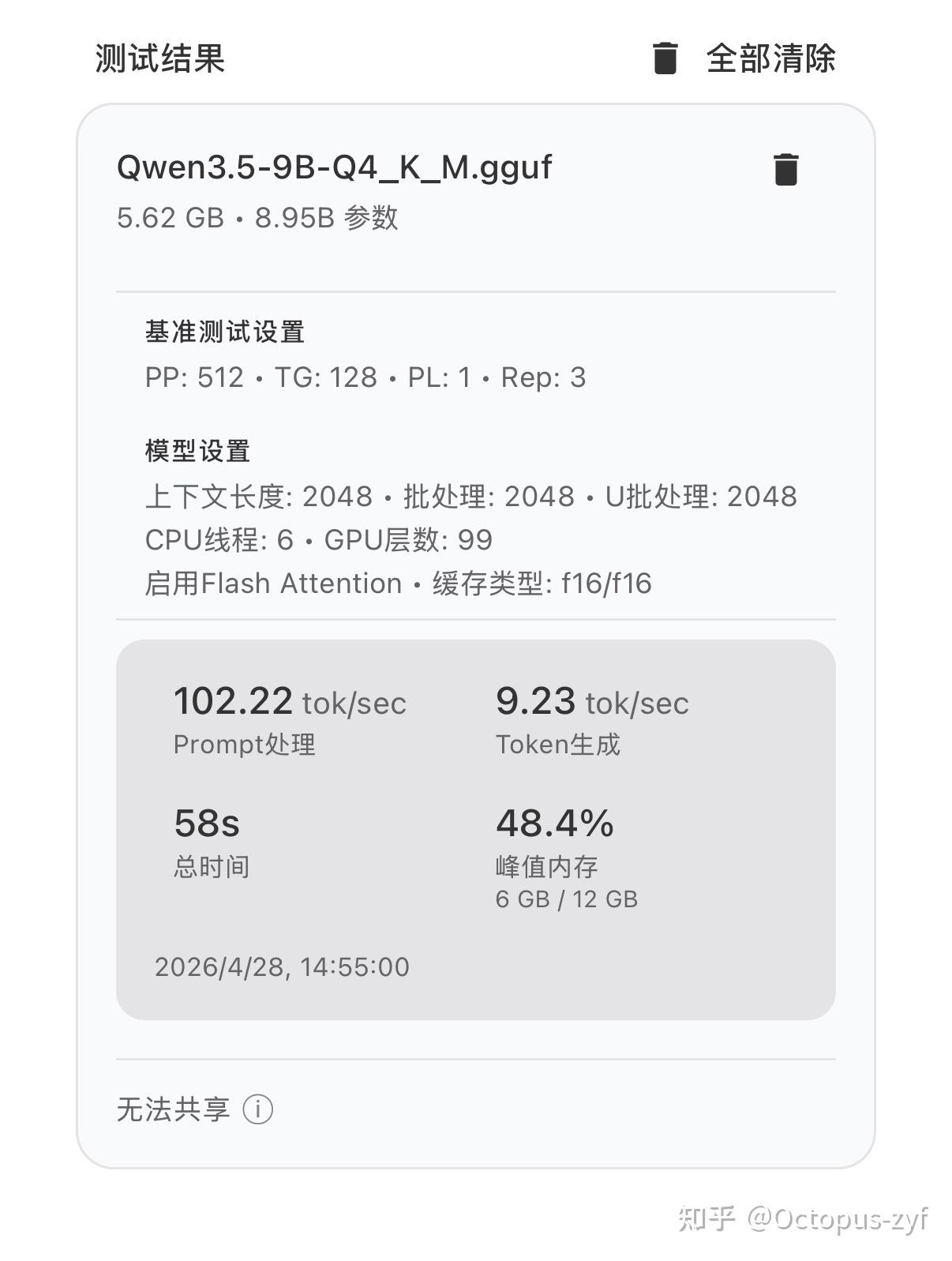
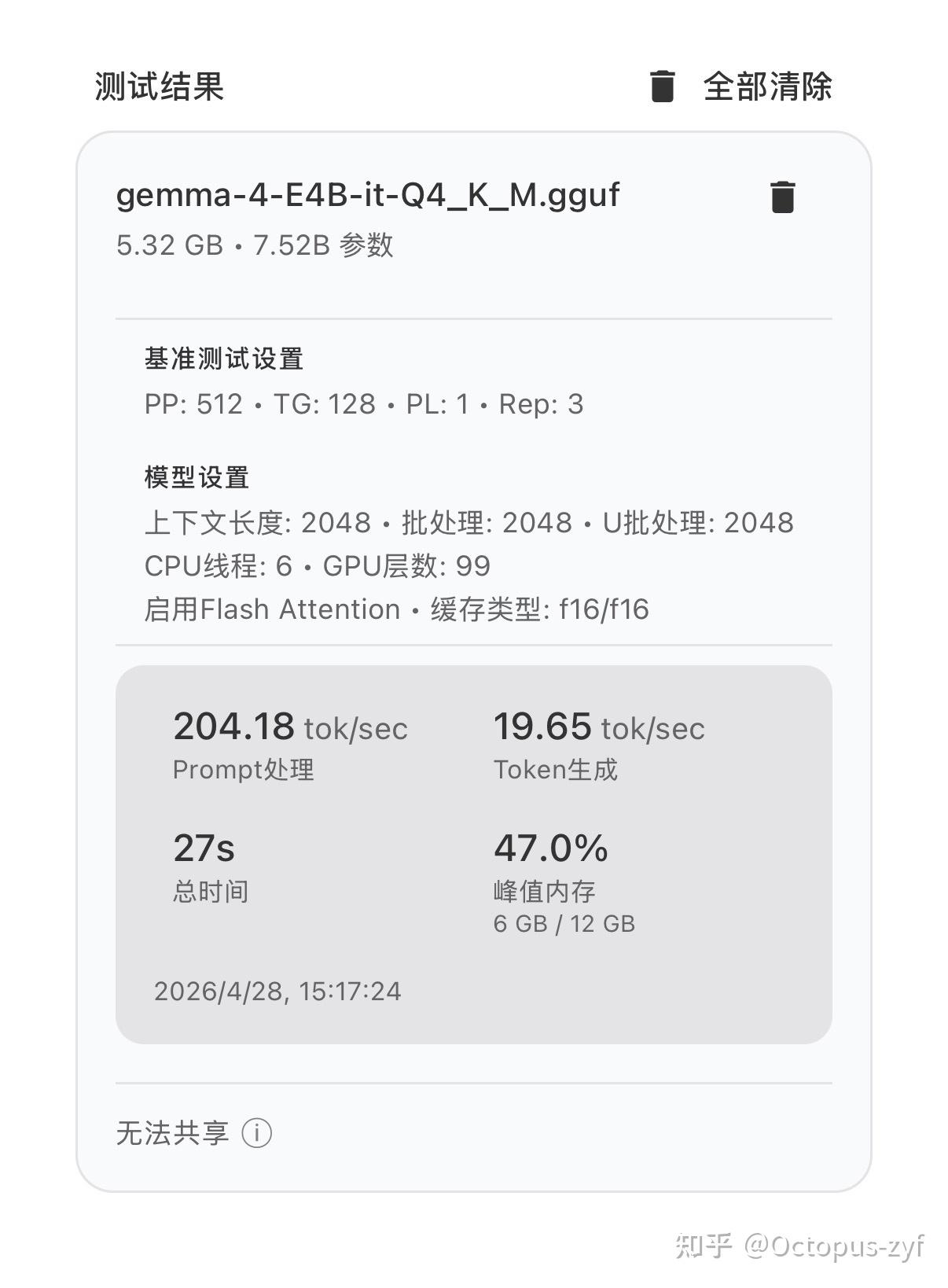
测试的模型选择了 Qwen 3.5-9B-Q4_K_M,以及 Gemma 4-E4B-it-Q4_K_M,这两款都是近期发布,体量比较小,性能表现比较好,适合本地部署的小参数模型。
其中:
Qwen 3.5-9B-Q4_K_M ,输出速度约 10 tok/sec,占用运存约 6GB
Gemma 4-E4B-it-Q4_K_M,输出速度约 20 tok/sec,占用运存约 6GB
在具体测试问题方面,测试了数学题和逻辑推理题,以鸡兔同笼和农夫过河问题为例,具体如下图所示:


输出结果自然是没问题的,现在简单的逻辑推理和数学题目基本上难不倒大模型,即使是小参数的大模型(Qwen3.5、Gemma4)都能有非常不错的表现。
从实际体验来看,如果真的想要体验手机本地部署大模型的,个人是比较推荐:Gemma 4-E4B-Q4_K_M 这款模型的,主要是 Gemma 4-E4B 比较新,模型不大,输出速度快,性能表现好。
虽然 iPhone 17 Pro 有12GB运存,Gemma 4-E4B-Q4_K_M只占用了6GB内存,理论上可以支持更大参数的模型,但跑 Qwen3.5-9B-Q4_K_M 的输出速度只有不到 10 tok/sec ,更大参数的模型跑起来只会更吃力。
此外,更高模型精度个人觉得性价比也不高,因为占用资源更多,手机耗电会更快,发热会更明显,很影响使用体验。
当然,上述测试仅基于 iPhone 17 Pro 的使用体验,本地大模型确实能跑,但体验绝对说不上好。
泼个冷水说,要说手机本地部署大模型的话,现阶段只能说是玩玩,实用性不大。倒不是说模型性能很差,而是更理想的手机本地模型的状态应该是底层系统层面和软件层面的打通,是嵌入底层的AI助手。
单纯就AI日常应用而言,手机上我觉得还是直接用豆包、DeepSeek、千问app更实用。