如何查看我的电脑,能跑什么AI模型?
电脑能跑什么模型,其实就看:显存和内存大小,其他硬件参数,基本不影响能不能跑。下面就先说下,如何查看自己电脑的硬件参数。
第一步、查看自己电脑的显存和内存大小
不同系统不一样,分别说下win电脑和苹果电脑
Windows电脑:
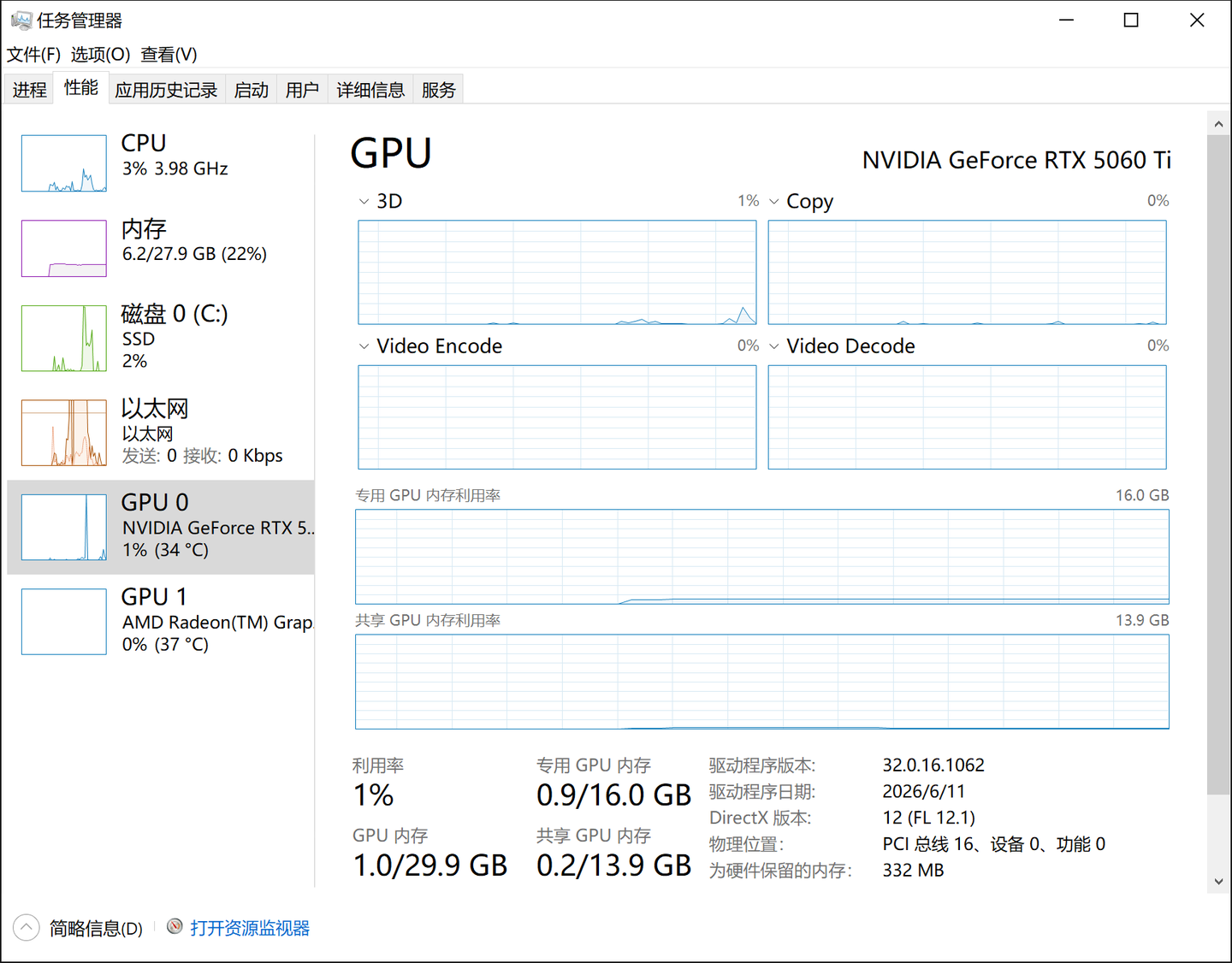
- 查显卡型号和显存
如果是独立显卡,鼠标在底部点击右键,打开任务管理器,切到”性能”标签页,左侧选GPU,下面”专用GPU内存”就是显存大小。
- 查内存大小
同样在任务管理器”性能”标签页,左侧选”内存”,就能看到总内存容量。
Mac电脑:
点屏幕左上角苹果图标,选”关于本机”,芯片型号和内存大小直接显示。

这里要说一下:苹果(M系列芯片)是统一内存架构,CPU和GPU共享同一块内存,没有独立显存这个概念,电脑总内存基本就等于”可用显存”。所以一台32GB内存的MacBook,就相当于右32G显存,不过统一内存带宽不如显卡,所以输出速度比显卡要慢一些。
第二步,查看对应能跑的模型档位
| 显存档位 | 典型显卡 | 模型档位(Q4量化) | 参考模型 |
|---|---|---|---|
| 无独显,16GB内存 | 核显电脑/老电脑 | 0.8B、2B | Qwen3.5-0.8B、Gemma4-E2B |
| 8GB | RTX 4060、5060 | 9B能跑、35B能跑 | Qwen3.5-9B、Gemma4-E4B |
| 16GB | RTX 5060 Ti 16G、5070Ti 16G | 35B能跑、9B舒服跑、12B舒服跑 | Qwen3.5-9B、Gemma4-12B、Qwen3.6-35B |
| 24GB | RTX 4090、RTX 5090D V2 | 27B舒服、31B舒服、35B舒服 | Qwen3.6-27B、Gemma4-31B |
| 32GB | RTX 5090 | 27B舒服、31b舒服、35B舒服 | Qwen3.6-26B、Qwen3.6-35B-A3B |
| 48GB~128GB | 专业卡/多卡/统一内存 | 还是27B和35B,断档,没有合适的通用模型。 | Qwen3.6-27B和35B |
| 500GB或以上 | 多卡+专业卡 | 800B、1T | GLM5.2、Kimi2.7、DeepSeek V4 |
说明:
1、表里的”B”是Billion的缩写,10亿的意思,9B就是90亿参数。参数越多模型越聪明,但也越吃硬件。
2、千问Qwen3.6-35B-A3B模型,是MoE模型,虽然有350亿参数,但每次仅激活30亿参数,所以显存需求看着吓人(约21GB),但实际上,8GB显存+32GB以上内存也能跑起来,只是输出速度会慢一些,16G显卡同理,也可以跑。
3、没有独立显卡,只靠内存的电脑,16GB内存最高,能部署到Gemma4-12B模型,但内存基本就要爆了,几乎没有上下文空间,属于能部署不能用。所以想输出快,就选小一点的模型,比如Gemma4-E2B或Qwen3.5-0.8B等,选大一点的模型输出就慢,需要点耐心,且上下文不够。
4、64G或128G统一内存设备,比如苹果Mac,英伟达DGX或RTX Spark ,AMD395等,虽然内存(显存)很大,可以轻松部署上Qwen3.6-27B级别的模型,但很难说是能用着舒服,因为输出速度对比显卡要慢很多。学习探索可以,实际干活养龙虾不太行。
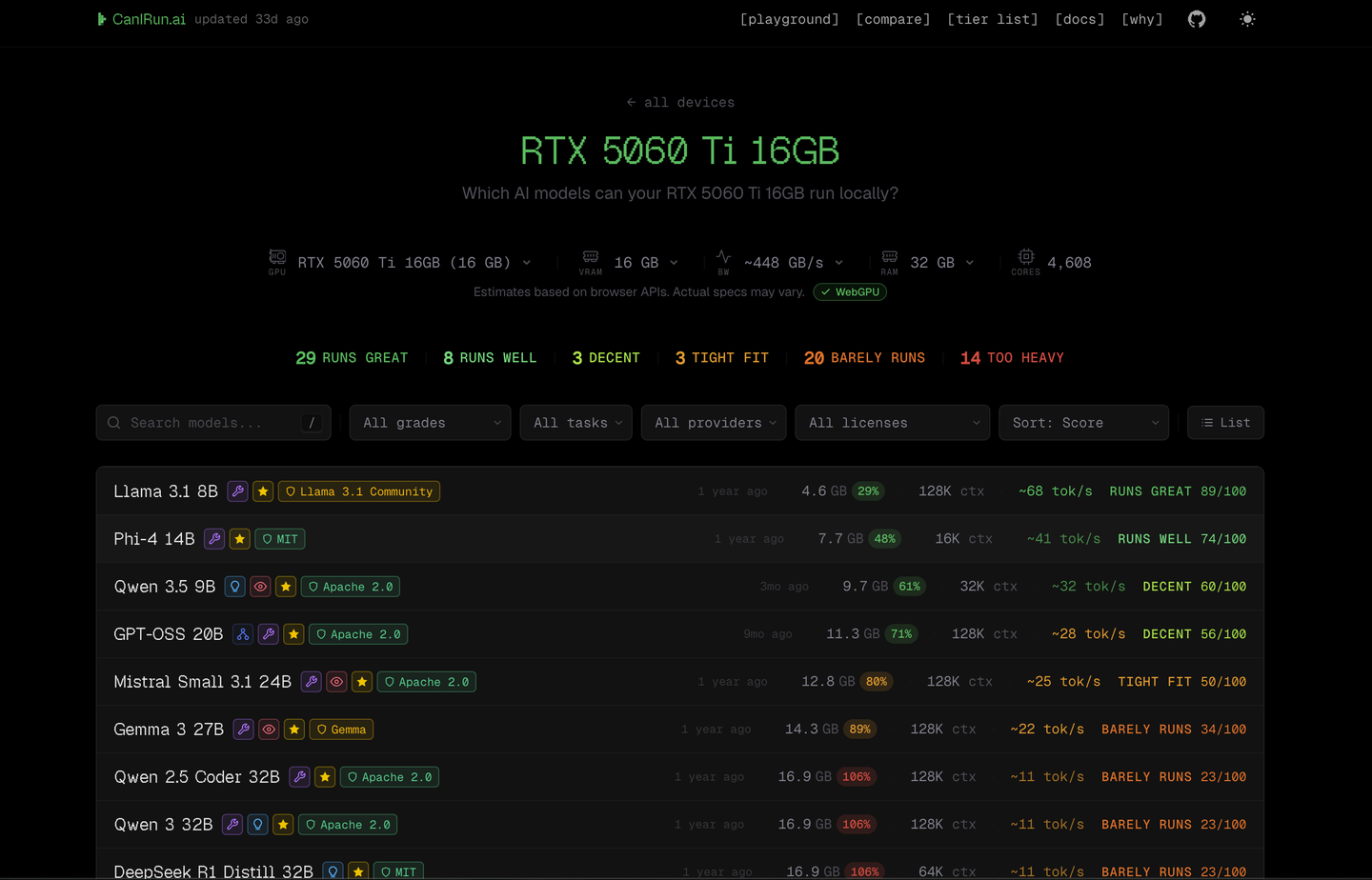
5、另外其实有个网站,caniran.ai可以查看不同显卡,能跑什么模型,和Token输出速度是多少,不过网站数据偏老,很多过时的模型也在其中,看着乱糟糟的,且数据也不是很准,所以仅作为参考吧。
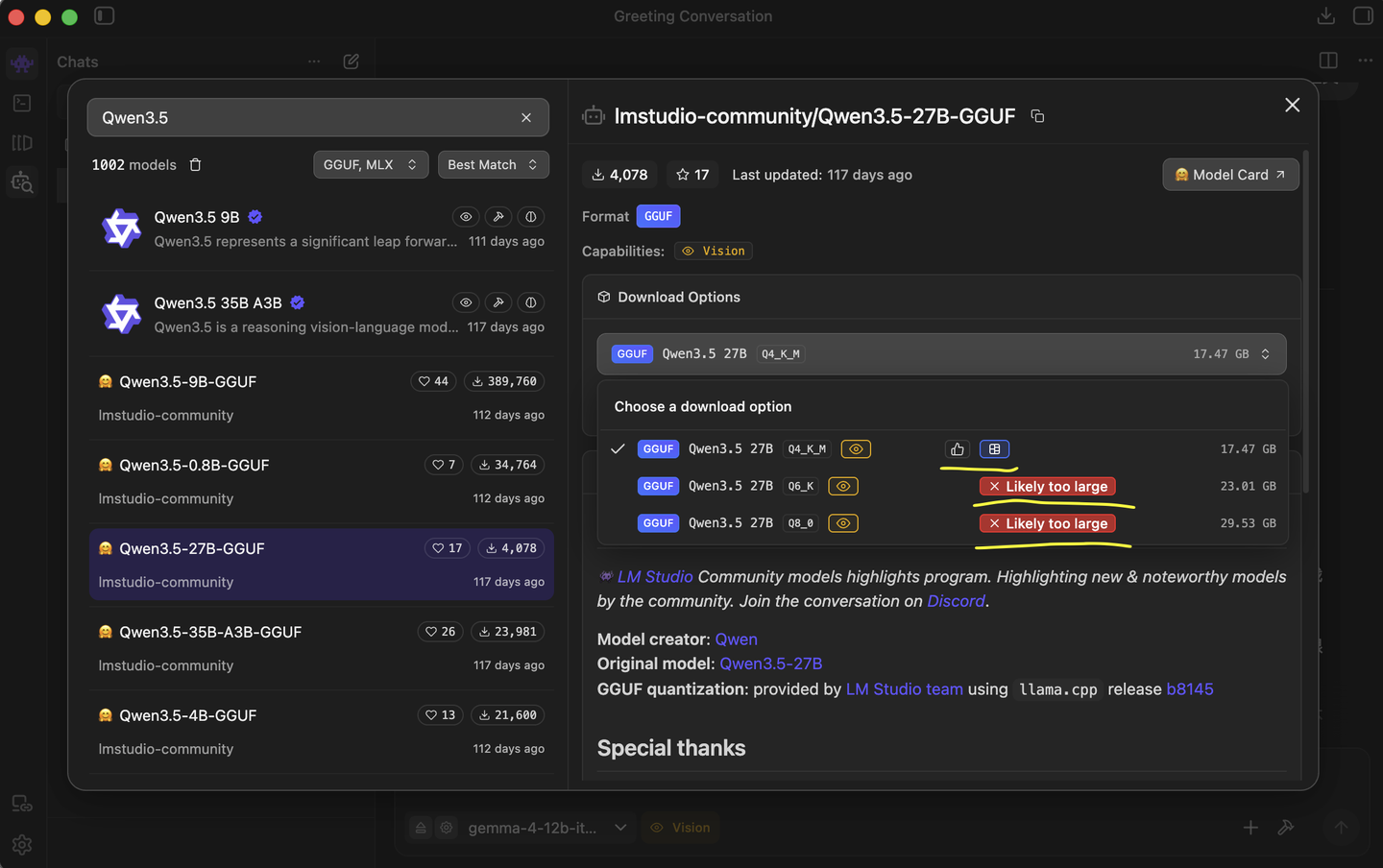
6、更直接的办法是,直接用部署软件试一下:
比如LM Studio,搜索模型时,会直接提示当前硬件是否适配,下载前,就能看到这个模型,大概要占多少显存,你的硬件够用,会有点赞手势,如果不够用,就会红框提示模型太大了。
其他提醒:
显存”够用”和”舒服够用”是两回事:如果显存刚好等于模型大小,一旦开长对话、上下文变长,很容易直接报错或卡死。所以不能卡着线跑,得留一点余量。
别只看显存,内存也要够装:内存要大于模型文件本身的大小,否则系统容易崩。内存大小最好大于或等于显存。
以上,希望对你有帮助。
如果想了解更多AI大模型本地部署,可以关注AI专栏,里面有各种模型的部署方法和教程。
AI大模型本地部署有问题评论区见。