
极客湾详细介绍了RTX Spark内部架构细节
极客湾详细介绍了 RTX Spark 内部细节,非常值得一看,总结如下。
RTX Spark 采用的芯片实际上就是 DGX Spark 配备的 GB10 超级芯片,针对笔记本和mini主机做了功耗优化。
这颗芯片实际上由两颗芯片组成,采用台积电 N3 制程。
CPU 由联发科深度定制,采用 Arm 架构,10 颗 Cortex-X925 超大核(2MB L2 Cache),10 颗 Cortex-A725 中核(512KB L2 Cache),CPU 与 GPU 采用 NVLink-C2C 互联。
极客湾指出 X925 超大核与联发科天玑 9400 在外观上有一些区别,可能针对 PC 做了后端设计上的优化。
极客湾详细描述了 CPU 的缓存结构,20 核分为两组 Cluster:其中一组 5+5 核心的 Cluster 共享 16MB 的 L3 缓存,另一组 Cluster 则有 8MB 的共享 L3 缓存,总计 24MB 的 L3 缓存。此外,片上还集成了 16MB 的 SLC系统级缓存。

GPU 采用 Blackwell 架构,有 48 组 SM,6144 个CUDA,接近桌面版 RTX 5070,比RTX 5070 移动版还要更大一些,GPU 片上集成了专用的 24MB L2 缓存。
很多人以为 RTX Spark 对标高通 Snapdragon X 系列,主打轻薄本,极客湾解释了这个误区,RTX Spark 定位是超高性能 SoC,参考对象是 Apple M-Pro/M-Max、AMD Ryzen AI Max 395 系列。
这些 SoC 最大的优势实际上是搭配了大容量的统一内存,比较对于AI模型来说,内存容量非常重要。
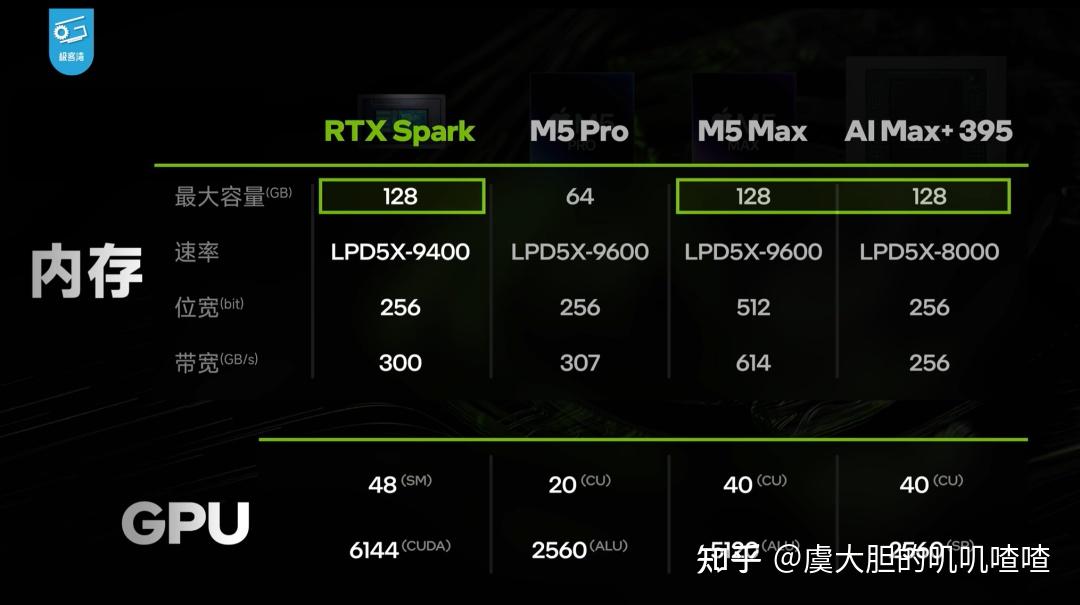
RTX Spark 最高可配置 128GB LPDDR5X-9000 的统一内存,256 位宽、带宽达 300GB/s,比 AMD AI Max 395 的 8000MHz 频率带宽稍高一些。
极客湾比较了RTX Spark、Apple M-Pro/M-Max、AMD Ryzen AI Max 395 内存相关情况,这三款芯片最大可配置128GB内存,但带宽上有差异。
- • RTX Spark:256 位宽、300GB/s
- • Apple M-Pro:307GB/s
- • Apple M-Max:位宽 512 位、带宽614GB/s
- • AMD AI Max 395:256GB/s
内存带宽方面,Apple还是有优势。但从算力上看,RTX Spark 是毫无疑问的王者,加上第 5 代 Tensor,在吞吐量方面优势比较明显。
极客湾表示相比高通 Snapdragon X 系列,RTX Spark 在 Windows 上的生态成熟的多,CUDA、TensorRT 在AI方面领先了很多,游戏方面,光线追踪、DLSS特性也是遥遥领先。

简单的来说,RTX Spark 对 Windows on Arm 生态的推动有巨大的作用。

要说 RTX Spark 缺点,极客湾认为还是 Windows 软件兼容性。
首先对于非原生 Arm Windows 软件 Prism 模拟层的会损失10%~30%的性能。
其次Windows x86平台的软件在Mac上有大规模的迁移,源于Mac生态的强悍。但对Arm支持还是不够,比如Windows 还有不少32 位软件的存在,开发Windows应用同时支持x86、Arm目前动力并不足。
所以软件兼容性是 Arm CPU 在 Windows 平台不得不面对的问题。
RTX Spark 显然瞄准 MacBook Pro 的高端定位,英伟达对 RTX Spark 平台笔记本有严格的硬件规范,比如必须符合 NVIDIA G-Sync 标准,屏幕刷新率至少 120H。

显然定位就是生产力工具,不是一般的轻薄笔记本。
相关文章: