
告别Token焦虑2026用ATOM本地跑OpenClaw是什么体验?
2026年,现在AI圈到处都是Agent。从OpenClaw到Hermes Agent,看着确实热闹,但玩多了就会发现:各种热门AI应用,正在引发Token焦虑,最近连豆包这类曾经的免费大户都开始收费了,云端调用那点账单积少成多,确实挺让人肉疼。关键是,有些私有数据、代码逻辑往外传,总觉得像是在裸奔这时候,你就特别想在手边有个能完全掌控的“私有算力中枢”。
算力的单位不再是“机架”,而是“桌面”
以前想跑千亿参数的模型,你得搞几张英伟达A100或H100专业显卡,就算是有钱买,还不定买得着,但那风扇转起来跟直升机起飞一样。但现在,风向变了。
我们手里这台技嘉AI TOP ATOM,说实话刚拿到手的时候,有点不敢相信。就这么一只巴掌大的深灰色金属盒子,里面塞了一颗英伟达GB10超级芯片,居然能提供128GB的统一内存。

AI TOP ATOM正面进气格栅有着神经网络般延展的纹路,感觉随时准备迸发出强劲算力。转到后面看接口,我们知道这玩意儿不是什么Mini PC,它就是个缩微版的超算:10Gbps的网口是标配,毕竟万兆内网才是跑数据的基石;最夸张的是居然还留了ConnectX-7的端口,支持多机级联,最高通过ConnectX-7可以建立4台AI TOP ATOM算力阵列,这可是正儿八经的“超算”配置。

背面排气格栅风格与正面相同,在其下部是IO接口。从左到右,AI TOP ATOM分为电源键、USB、HDMI与LAN接口,数量虽不多但各个功能都很顶。供电接口直接采用USB Type-C接口,实虽然它配了一个240W的大功率适配器,但那只是为了给峰值性能留足冗余。实际测试中,运行主流中型模型时,整机能效表现极佳。日常使用约60W,而在AI推演生成实际功耗约160W,它并不像那些动辄600W的独显电老虎,这种高密度能效比,才是它能安稳待在开发者桌面上的底气。剩下三个USB Type-C接口,最高支持USB3.2 Gen2×2,妥妥20Gbps速率,而且也支持DP视频输出。平时将它往实木桌上一放,接上一根HDMI线,旁边再搁杯咖啡,那种高性能密度的“桌面超算“质感一下就出来了。
平时AI TOP ATOM在桌上安安静静地待着,但在按下背后电源键的那一刻,它就是一个能随时本地端侧推演整个世界的AI神经中枢。
Blackwell核心解析:GB10的代差压制

以前我们用独立显卡玩AI,哪怕是使用英伟达RTX 5090这种旗舰,32GB显存也就到头了。可跑AI最怕的就是看到Out of Memory,只要模型上下文稍微长一点,系统就开始卡顿。
但英伟达GB10超级芯片完全是降维打击。它不是那种插在主板PCIe槽上的传统显卡,而是英伟达把数据中心那套Blackwell架构,直接浓缩进了一颗3nm工艺的SoC里。

这颗芯片通过2.5D封装,并排塞入两颗大核心,一颗是集成了20核ARM v9.2架构的CPU,这是英伟达跟联发科深度定制的,另一颗就是纯正的Blackwell GPU。它们之间通过超低功耗的NVLINK C2C互相打通,这就实现了CPU和GPU之间没有隔阂。
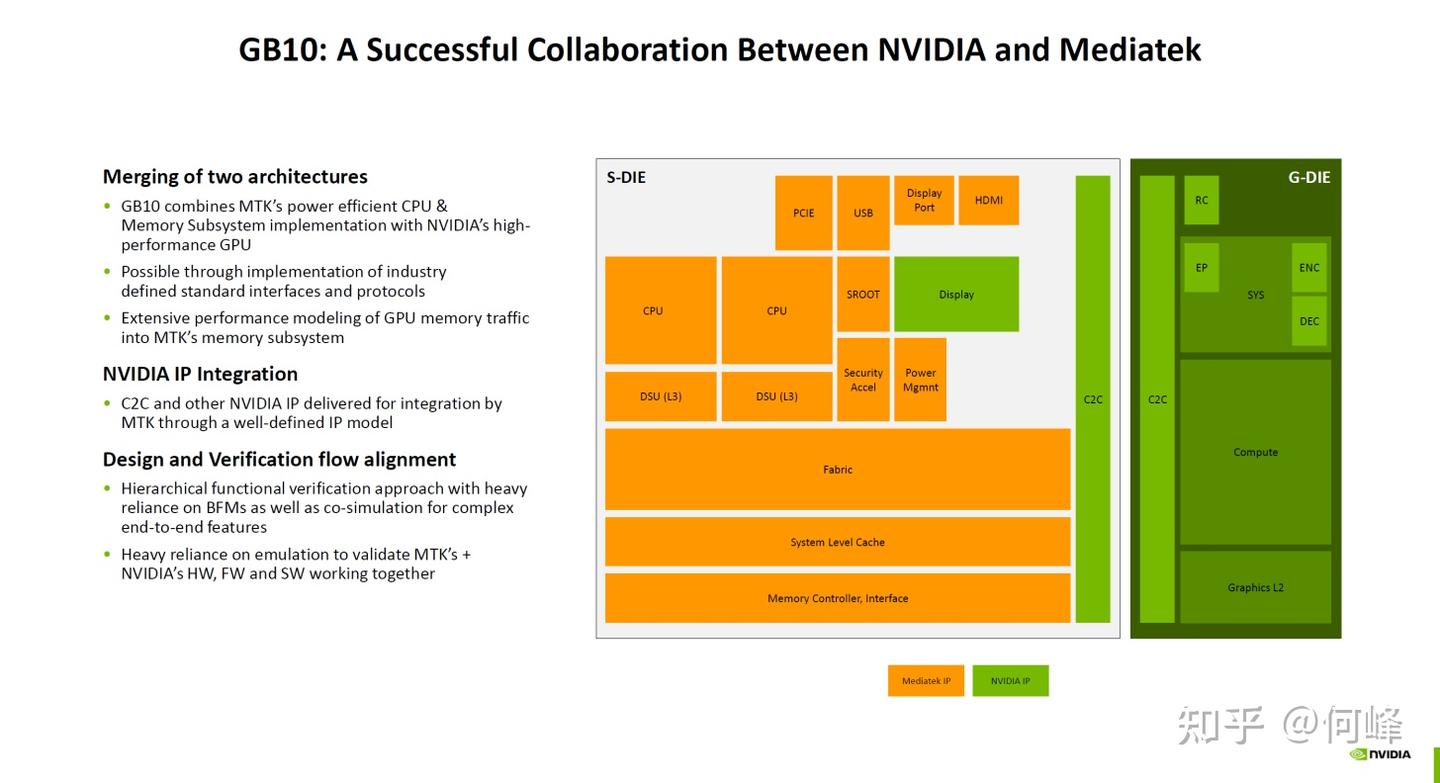
最重要的是具备128GB LPDDR5X统一内存。此种内存速度高达9400MT/s,带宽直接拉到了301GB/s。以前想都不敢想的巨型模型,比如Llama 3 400B的量化版,以前得靠几块RTX 4090显卡拼着一起跑,现在一台采用GB10的AI TOP ATOM就能轻松装载运行。而且它原生支持FP4精度,AI算力直接堆到了恐怖的1000TOPS。虽然TDP才140W,但在处理Agent推理时那种瞬间响应速度,确实让以前那些动辄400W-600W的独显电老虎显得有些笨重。

甚至如果觉得128GB统一内存还不够,它背后的ConnectX-7接口还能让你把多台机器级联起来扩展算力。这种把数据中心超级芯片塞进迷你机箱的做法,确实很“2026”。
三种调教模式,总有一种适合你
硬件堆料再狠,最后还是得看怎么用。这台AI TOP ATOM最有意思的地方在于,它给了不同层级的用户三条完全不同的“入坑”路径。
趋境AIMA:零门槛的保姆级在线部署
虽然技嘉AI TOP ATOM作为小强无敌,但如果买回来还得先折腾半天驱动、配环境、写Python,那对很多AI入门玩家或者小型团队来说太心累了。技嘉这次与趋境科技深度合作,直接将AIMA智能管控平台揉进了AI TOP ATOM,这并不是GB10超级芯片自带的公版功能。
说白了,AIMA就是个“保姆级”的AI助手。它最大的特点是零依赖、离线可用。我们将AI TOP ATOM连上电,进入AIMA非常直观的Web管理界面。不需要盯着黑框框敲代码,直接在网页里就能看监控、调模型、管日志。它预装部署了多种模型,可以直接调用即可,而且自带在线AI助手功能,接管了从硬件到模型推理之间的所有中间层,自动识别硬件、智能匹配配置。以前你要折腾几天的模型部署,现在用AIMA基本上几分钟就能搞定从硬件检测到大模型本地部署就绪的全过程。
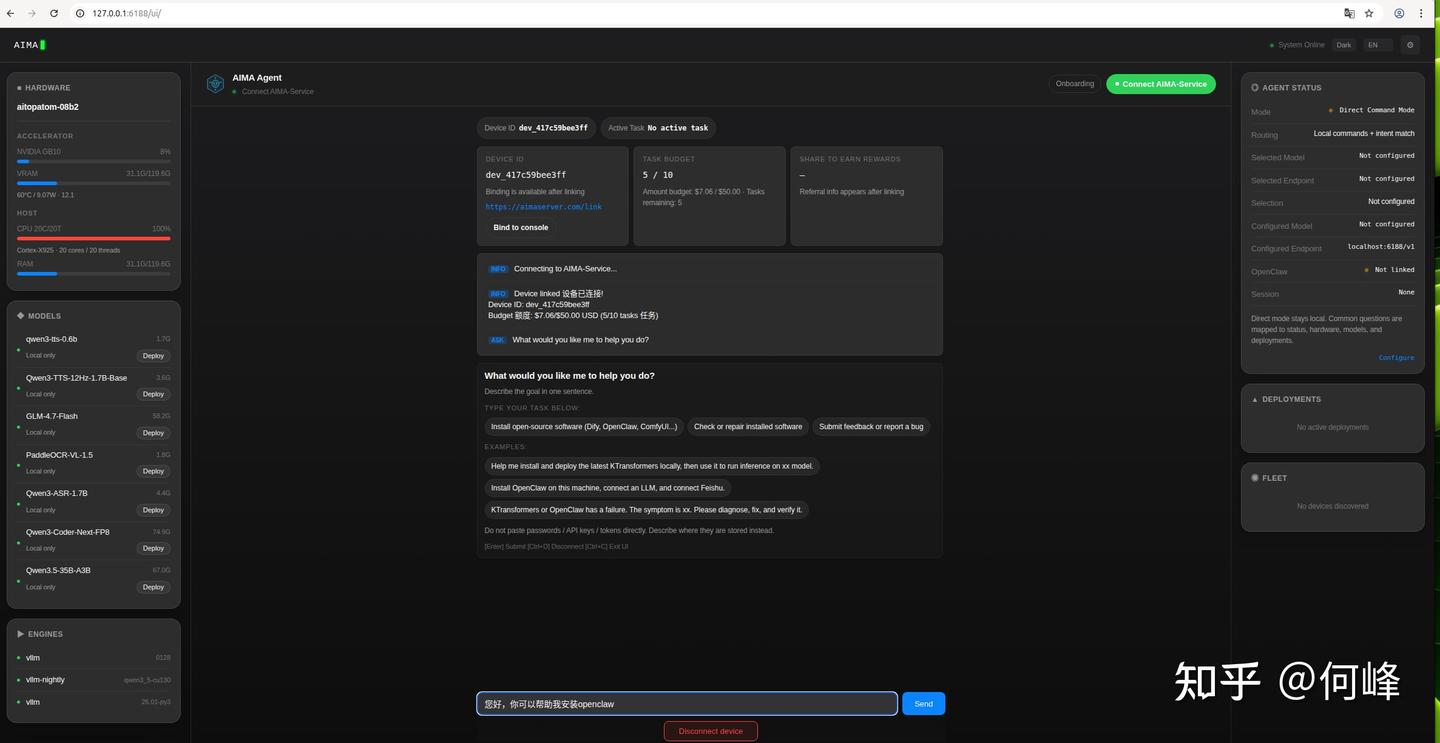
AIMA还甚至自带了MCP工具接口,想让你的Agent 联网或者是调用本地文件,点点鼠标就行。这种开箱即用的体验,让这台小盒子不再只是个需要我们们专研各种配置的硬件,而是一个真正易于使用的AI生产力终端。
英伟达Sync协同:专业开发者的网络终端管理
第二种方式,是采用英伟达官方的网络设置和访问管理程序Sync,它借助SSH加密协议让你使用Windows和Mac设备把技嘉AI TOP ATOM当作网络终端来管理。
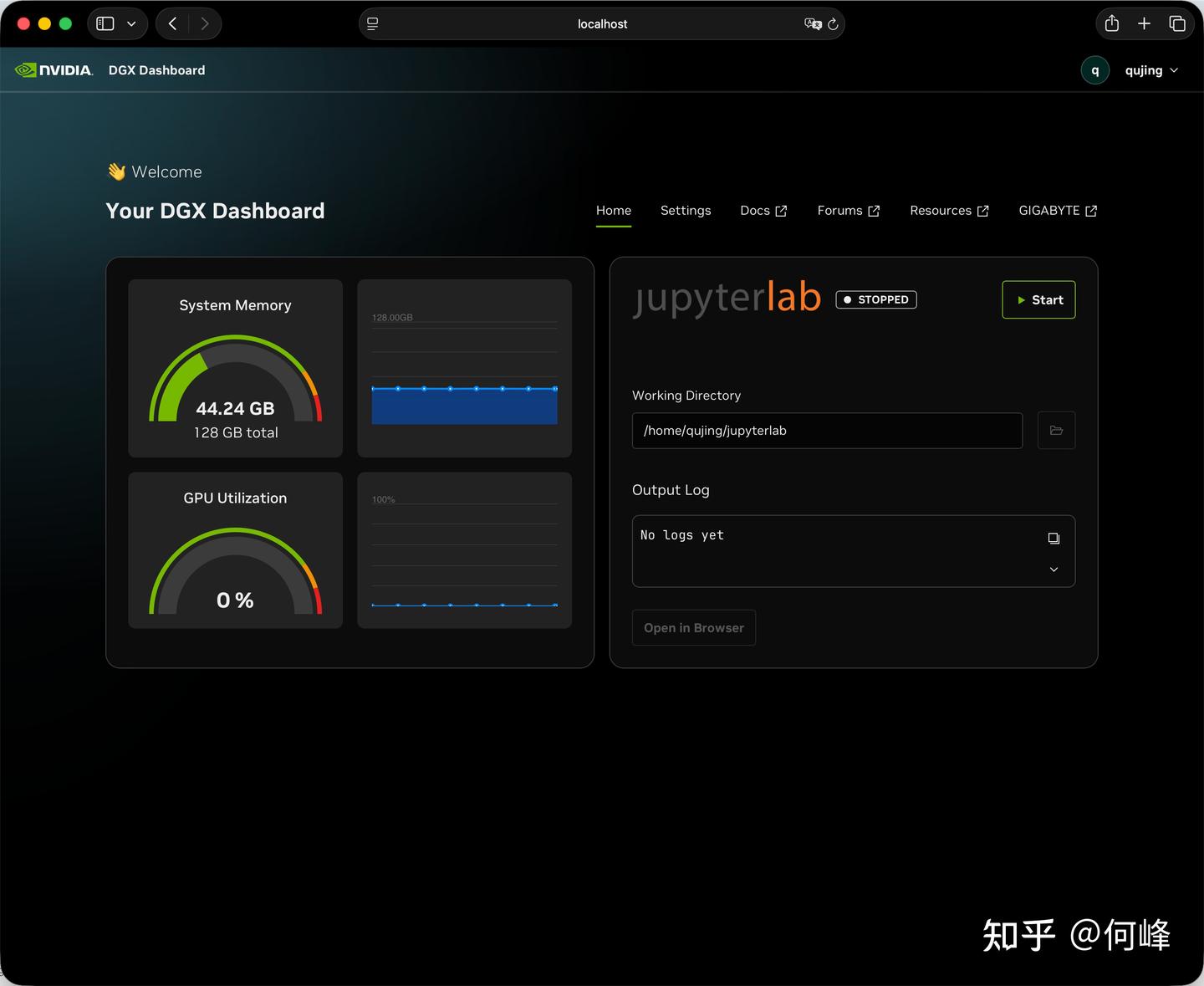
顺带的,它还集成系统监控,JupyterLab,并可选VS Code。这些捷径对相对专业的开发者比较友好,要知道,JupyterLab是数据科学和AI工程常用的工具,利用技嘉AI TOP ATOM将AI成为你代码流的一部分。
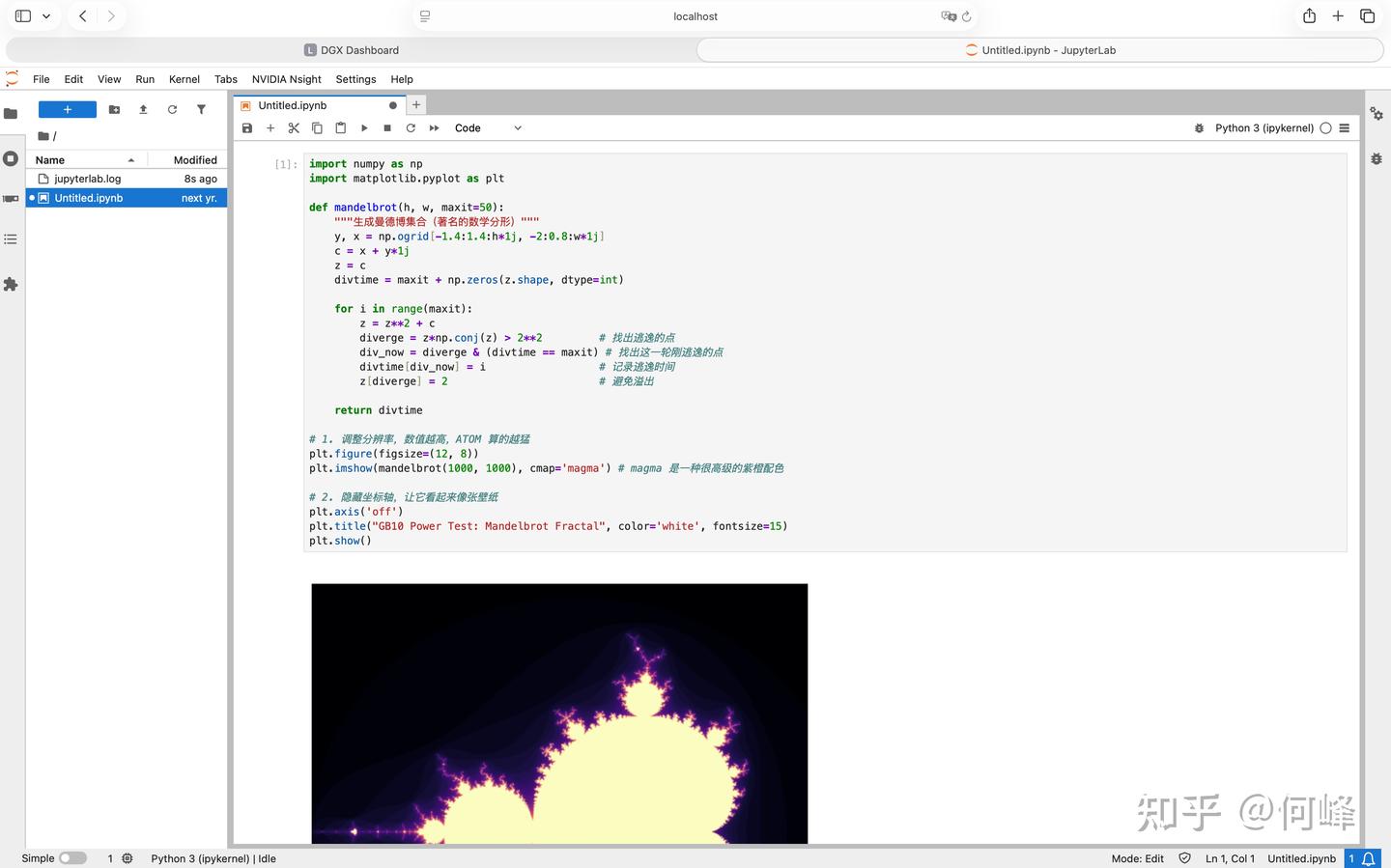
Sync还可选装的VS Code,加上Cline插件后,就可以利用本地大模型能力帮你编程。嗯,我们的习惯是在AI助手对话框里发出需求,“帮我们写个贪食蛇游戏”,然后看着我们不了解的代码块自动出现……
完整本地系统:极致掌控的Ubuntu开发环境
第三种方式,掌控力更强,若你希望对AI TOP ATOM进行软件硬件的全面掌控,直接将它接上显示器和键鼠,可以对它做更细微的调教,毕竟它是一台运行完整Ubuntu,对开发者友好的强大系统。
牛刀小试:这才是AI用户的黄金工位
终究,硬件拿到手是要用起来的。为了看看这台技嘉AI TOP ATOM到底有多深不可测,我们直接在跑了一些大家都能上手的尝试。
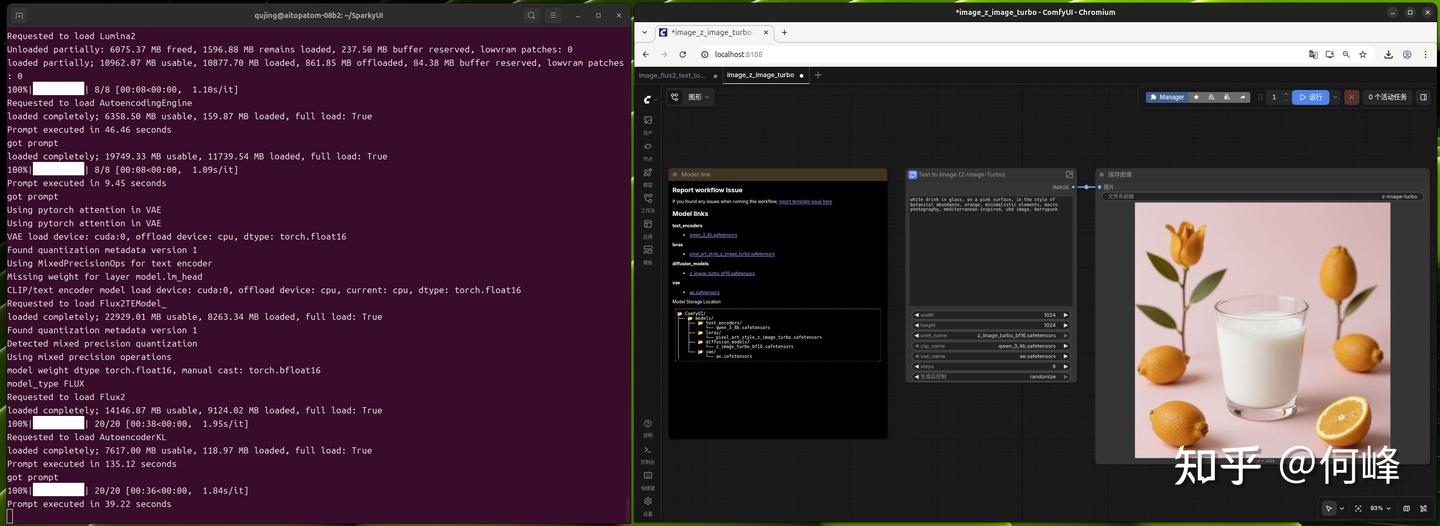
直接下结论,采用技嘉AI TOP ATOM玩AIGC,属于生产力第一梯队。模型全驻留,零加载延迟,稳定性都是上佳。拿常见的Z-Image-Turbo,采样速度1.09s/it,8 步总耗时9.45秒。而FLUX.2,采样速度达到1.84 s/it,20步总耗时39.22秒。相信在未来两年内,FLUX.3 或更重的视频模型发布,AI TOP ATOM的128GB统一内存依然能让AIGC玩家保持在首发即流畅的状态。
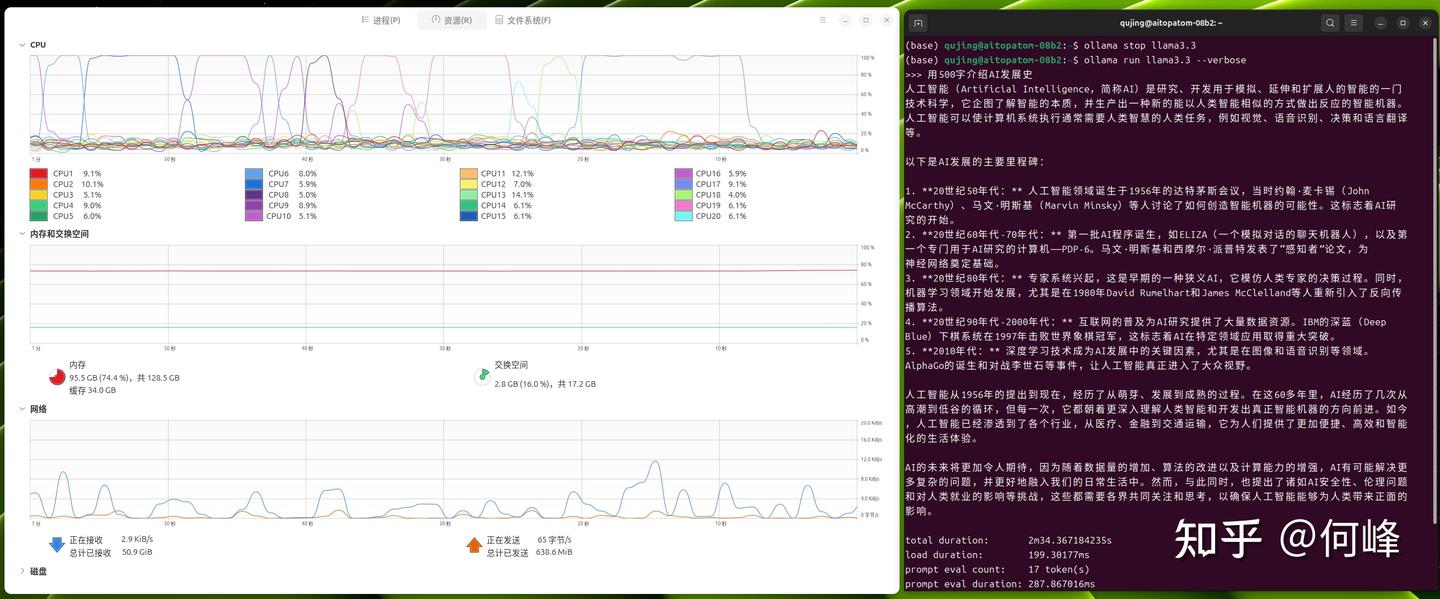
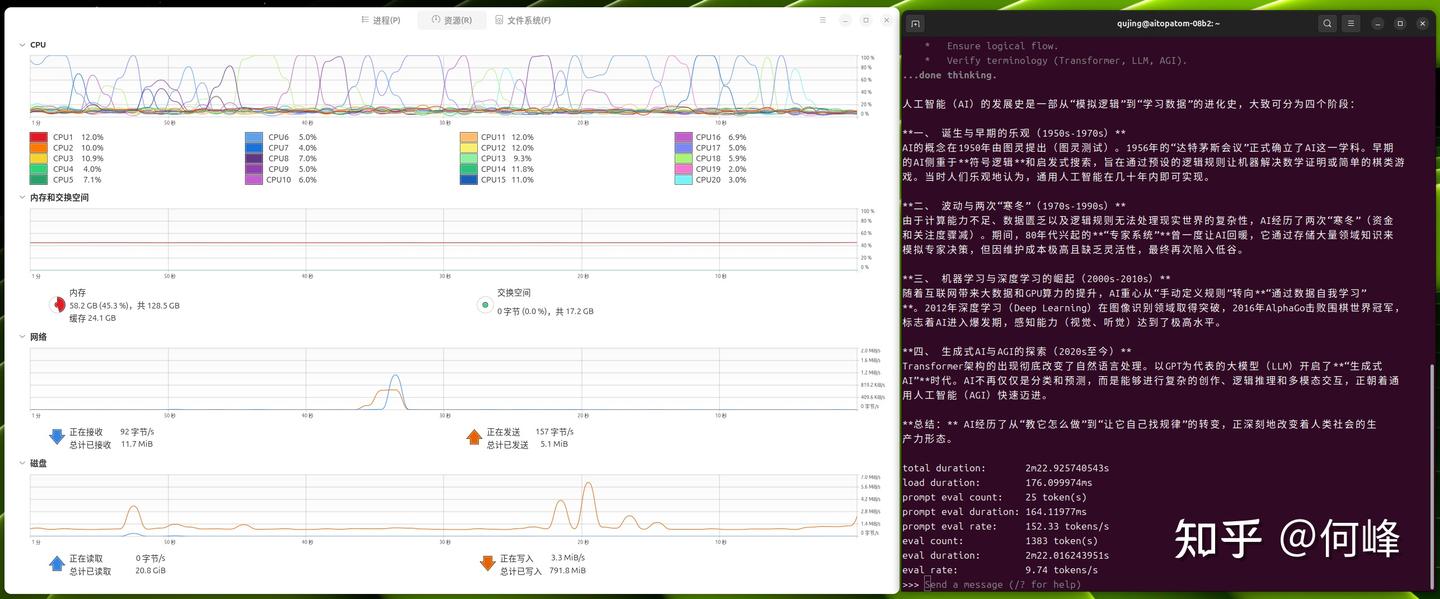
使用AI TOP ATOM玩本地大模型,也是让人惊奇,Qwen 3.6:35b达到50.62 tokens/s,体验上已经和云端最快的API没区别,没有任何等待感,写100行代码只需要十几秒钟;Gemma 4:31b达到9.74 tokens/s,Gemma系列模型处理复杂逻辑时依然非常从容;Llama 3.3:70B则可以塞入AI TOP ATOM运行,让不可能变成可能,让我们偷偷在家里运行以往只有数据中心才能跑的顶级开源大模型。
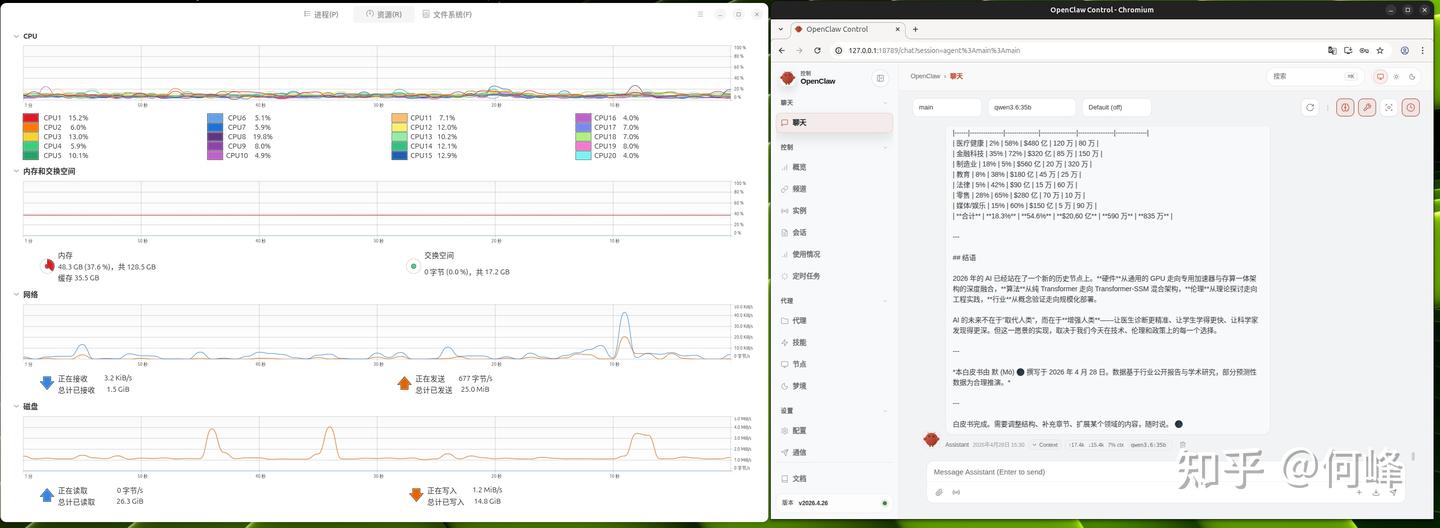
体验当然未能缺少我们开头提到的Agent,以OpenClaw为例,采用本地Qwen 3.6:35b模型,要求它写一篇5000字以上的深度技术白皮书,这台机器跑出的17.4k输入和15.4k输出的上下文规模,这意味着能够连续5分钟保持50+ Token/s的高速输出完成一篇白皮书,这台AI TOP ATOM采用Qwen 3.6 35B-A3B模型,上下文可以达到通常的模型上限256K,意味着你可以把一整本技术手册甚至半个代码库塞给它,它不回半途失忆而胡言乱语,而且可以实现达到惊人的4000TPS以上Prefill性能,当我们把海量文档丢进去时,同时可以实现解码速度30TPS以上,这已经完全远远超过我们人类的阅读速度,它几乎是“瞬间”接受即理解。这不仅仅是快,而是意味着拥有128GB统一内存的AI TOP ATOM初步达到了“智能体本地化”的基础线——一个能实时思考、快速反思、且不产生额外Token费用的私人大脑。
2026的AI世界入场券
AI TOP ATOM好不好?当然好用好玩,但是也有不尽人意的地方,首先是内置硬盘容量不能自行扩充,只能选购1TB和4TB两种容量,建议利用Type C外挂硬盘或者自带10G网口连接NAS建立本地数据集,以弥补内置存储空间不足的遗憾。其次是三万块的价格确实有门槛,但算一笔账:一张32GB显存的RTX 5090也要这个数,却跑不了256k上下文,也吞不下35B的完整模型。但是,对于被Token费用逼疯、被显存容量卡死的AIGC创作者和Agent开发者而言,AI TOP ATOM 不是奢侈品,而是2026年最硬核的生产力工具。
按照AI TOP ATOM的性能来看,每天可以处理1100份256k长文档,云端API每天话费需要500元以上,只需50天多,AI TOP ATOM省下的API费就足够买回这台机器,而且没有网络延迟,没有API丢包,数据不出户。
拥有技嘉AI TOP ATOM,就是拥有了2026年最顶尖的桌面数字生产力,加上网络链接,多机扩展、大模型训练,给你的回报率会远超一张游戏卡。