大显存正是称王的理由:RTX PRO 6000 Blackwell 模型能力以一敌四 5090,还省电费
现在魔改5090落实没有?
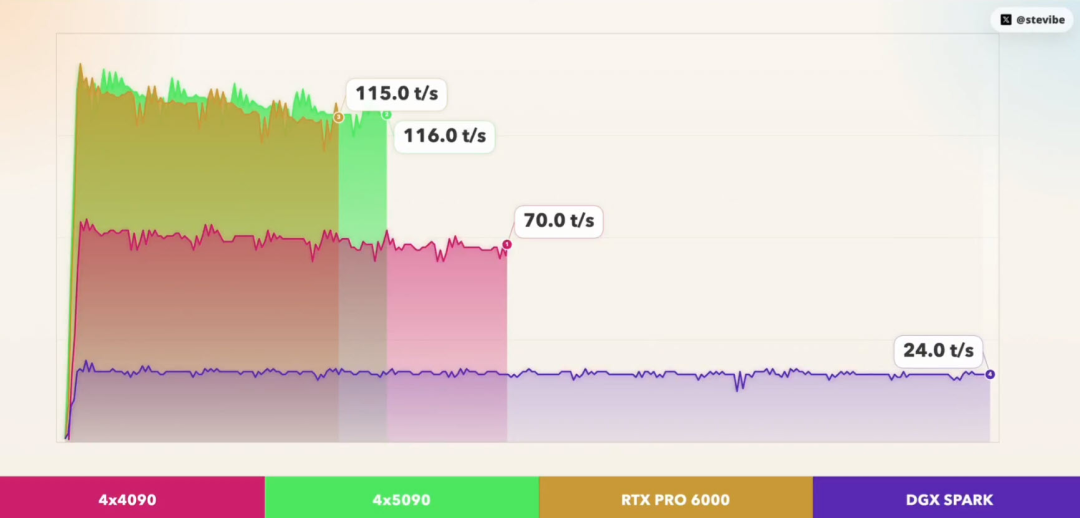
测试数据显示,在处理 MiniMax M2.7 模型时,单块 RTX PRO 6000 的生成速度达到了118.74 tok/s。作为对比,由四块 RTX 5090 组成的“电老虎”集群速度为120.54 tok/s。两者速度几乎持平,但背后的代价却天差地别。
4x RTX 4090 (96GB): 71.52 tok/s, TTFT 1045ms
4x RTX 5090 (128GB): 120.54 tok/s, TTFT 725ms
1x RTX PRO 6000 (96GB): 118.74 tok/s, TTFT 765ms
DGX Spark (128GB): 24.41 tok/s, TTFT 741ms
此外,针对轻量级办公和个人开发者,英伟达的DGX Spark迷你 AIPC 也表现亮眼,以仅240W的整机功耗提供了平稳的推理体验,成为了插座即用的Pre-fill利器。
4x4090 → 1,800W peak (450W × 4)
4x5090 → 2,300W peak (575W × 4)
RTX PRO 6000 → 600W peak
DGX Spark → 240W peak (whole system)
在功耗方面,四块 RTX 5090 的峰值功耗高达惊人的2300W,对家用供电和散热系统提出了地狱级要求。而单块 RTX PRO 6000 峰值仅为600W,仅需四分之一的电量就完成了同样的任务。更扎心的是价格:四块 5090 总价约1.4 万美元,而 PRO 6000 售价约为9500 美元,专业卡在此时竟显现出了极高的性价比。
Avg RTX 4090 Retail Price - $3000 US (Per GPU)
Avg RTX 5090 Retail Price - $3500 US (Per GPU)
Avg RTX PRO 6000 Retail Price - $9500 US (Per GPU)
Avg DGX Spark AI PC Retail Price - $4699 US

该播主的实验证明,多卡配置在运行超大模型时常受限于显卡间的通信延迟,而 Blackwell 架构专业卡通过极高的显存带宽和单卡大容量显存完美规避了这一瓶颈。
之前一直有传闻出 RTX 5090 被作坊等等弄去做魔改,但是目前来看,我只看到 5090 改成了涡轮版本,预期中的显存扩容魔改并没有到来。有可能这次英伟达抓的很死,或者在硬件上的显存控制器做了物理限制,这样看来,未来 RTX 50 系民间升级显存的机会有点渺茫啊。
往期阅读:什么叫内存也上刀法?英特尔新建 HUDIMM 标准,位宽砍半节省成本拉低 DDR5 门槛