🌈AI小鹿物语:拒绝涨价&2026年平民本地AI算力硬件避坑指南:从百元矿渣到Mac
最近这几个月,不管是写代码、查资料还是写总结,大家应该都已经离不开AI了。但每个月交着几十刀的订阅费,还要忍受时不时的网络抽风和“该话题违反政策”的提示,心里总有点不爽。作为一个资深垃圾佬,我们的宗旨是:能白嫖的绝不花钱,能自己跑的绝不上云!
随着开源大模型(如 Qwen、Llama 3、DeepSeek)越来越强,“本地部署AI” 已经不再是大型机房的专利。今天,我就来给大家盘点一下目前市面上主流的“平民AI算力硬件平台”,并附上手把手的搭建指南,教你怎么用最少的钱,把一个最聪明的AI养在自己家里!
一、 选型核心定律:跑AI,到底吃什么配置?
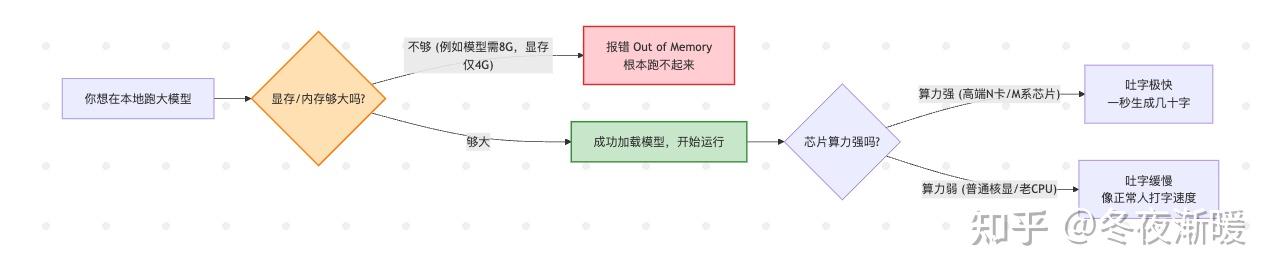
很多同学一上来就问:“我这颗 i9 处理器能不能跑AI?” 打住!跑AI(特别是跑大语言模型 LLM),核心只看一个指标:显存容量(VRAM),或者叫 运行内存。
大模型需要把整个模型权重加载到显存里才能运行。
- 7B 模型(如 Qwen 7B,相当于普通本科生):通常需要 8GB 左右显存。
- 32B 模型(相当于资深专家):通常需要 24GB 左右显存。
- 算力(芯片速度) 只决定了AI回复你时“吐字”的速度,而 显存 决定了你能不能把它跑起来。明白了这个道理,我们来看看目前主流的三大硬件流派:
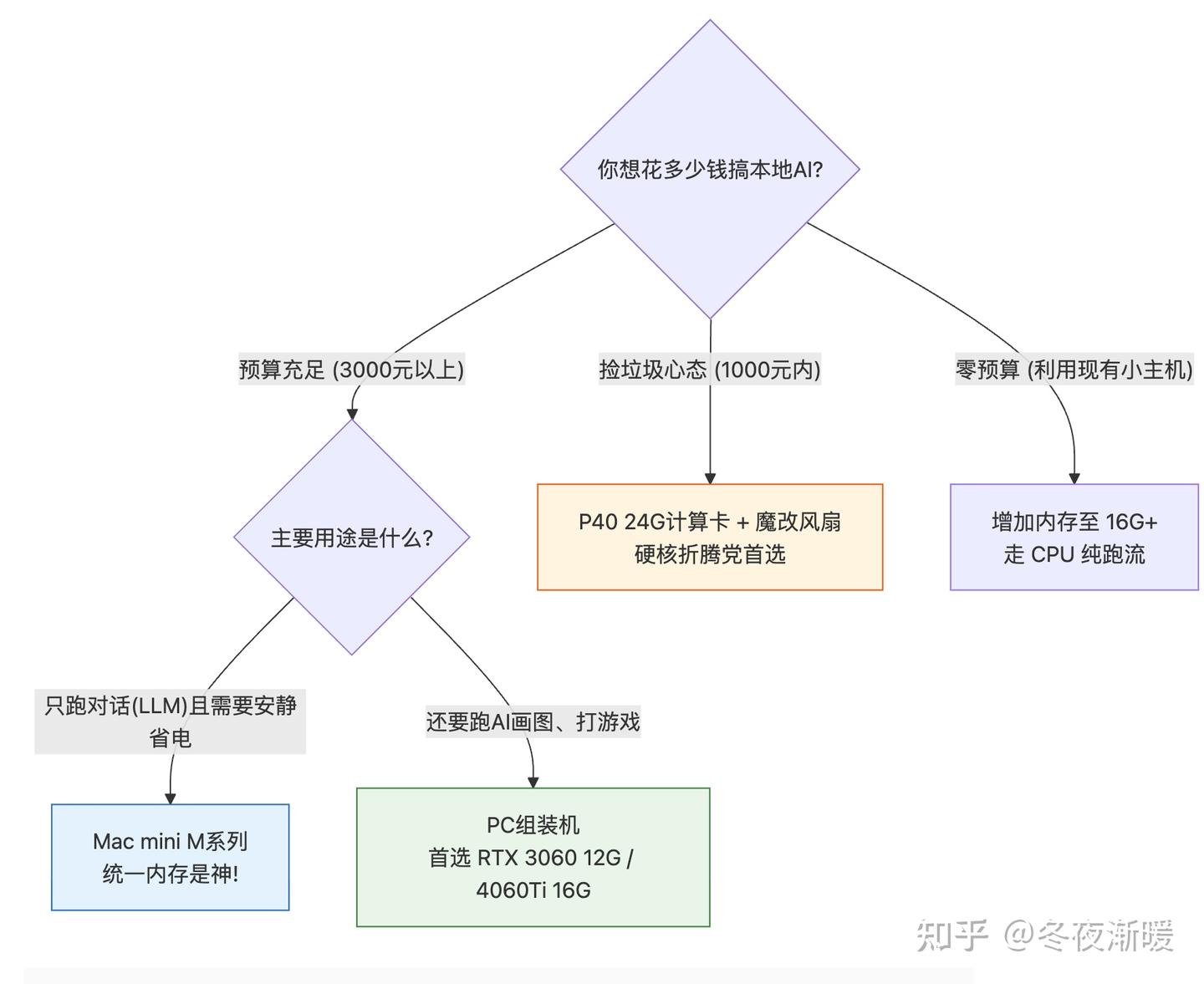
二、 三大硬件流派盘点(按土豪到垃圾佬排序)
流派 1:物理外挂——Apple Silicon (Mac 统一内存流)
这是目前非专业矿老板之外,最香、最降维打击 的本地AI方案。 - 原理:苹果的 M 系列芯片(M1/M2/M3/M4)采用的是“统一内存”架构。你的内存就是显存!一台 64GB 内存的 Mac Studio,相当于拥有 64G 显存,这在 PC 阵营要买两块极其昂贵的 RTX 4090 才能凑齐!
- 推荐机型:Mac mini M4 (至少 16G 内存版) / Mac Studio
- 优势:功耗极低(几十瓦)、极其安静、内存当显存用,简直是跑大模型的物理外挂。
- 劣势:机器本身价格不便宜,且不能扩展。

流派 2:正规军——Nvidia RTX 显卡流 (PC/服务器)
AI 圈有句名言:“买卡只认 N 卡(CUDA)”。AMD 和 Intel 的显卡虽然在努力,但目前的生态和兼容性依然能让新手折腾到吐血。
- 甜点级神卡:RTX 3060 12GB 版 或 RTX 4060 Ti 16GB 版。它们算力一般,但给的显存大!二手 3060 12G 只要一千多,足够跑起大部分 7B/8B 的高质量模型。
- 垃圾佬极限神卡:Tesla P40 24GB。这是一张服务器计算卡,闲鱼只要 400 块左右!24G 显存简直逆天!但它没有风扇(需要自己魔改暴力扇),且算力古老,适合重度折腾玩家。
- 优势:生态完美,速度最快,不仅仅能跑对话模型(LLM),跑画图模型(Stable Diffusion)也是最强的。

流派 3:硬扛流——核显 / 纯 CPU 流 (NAS/小主机)
很多朋友家里只有 N100 小主机或者普通的群晖 NAS,能跑吗?能跑,但得有耐心。
- 原理:利用普通的 DDR4/DDR5 内存条来加载模型,让 CPU 直接硬算。
- 现状:如果你有 16G 内存的普通小主机,跑个极其轻量级的 Qwen 1.5B 或者 4B 模型是没问题的,吐字速度大概在每秒 5-10 个字(相当于人打字的速度)。
- 优势:零成本,利用现有闲置设备。
- 劣势:速度慢,一旦跑大一点的模型直接卡死。

▼ 一图看懂你应该选哪个流派:
三、 软件篇:如何优雅地把AI跑起来?
硬件搞定了,软件怎么搞?以前跑本地大模型需要配一堆复杂的 Python 环境,现在只需要两个神器:Ollama + Open WebUI。
整个系统的架构如下:
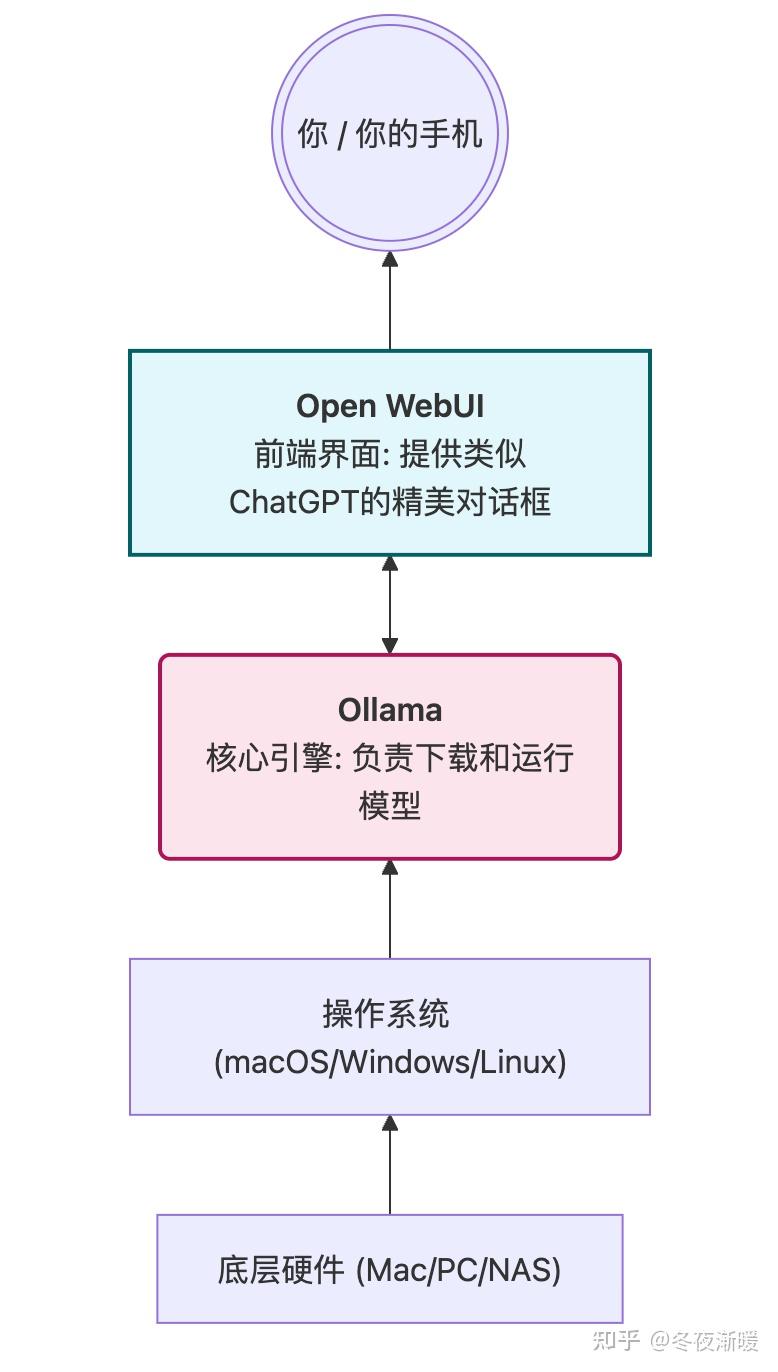
第一步:安装引擎大管家 Ollama
Ollama 就像是 AI 界的 Docker,它把复杂的模型封装成了一个个简单的包。
- Mac/Windows:直接去 Ollama官网 下载安装包,安装即可。
- Linux/NAS终端:一行命令搞定
curl -fsSL https://ollama.com/install.sh | sh 安装好后,打开终端,输入 ollama run qwen2.5:7b(通义千问7B模型),也可以手动进行选择,系统会自动下载并运行。稍等片刻,你就可以在黑框框里跟AI聊天了!
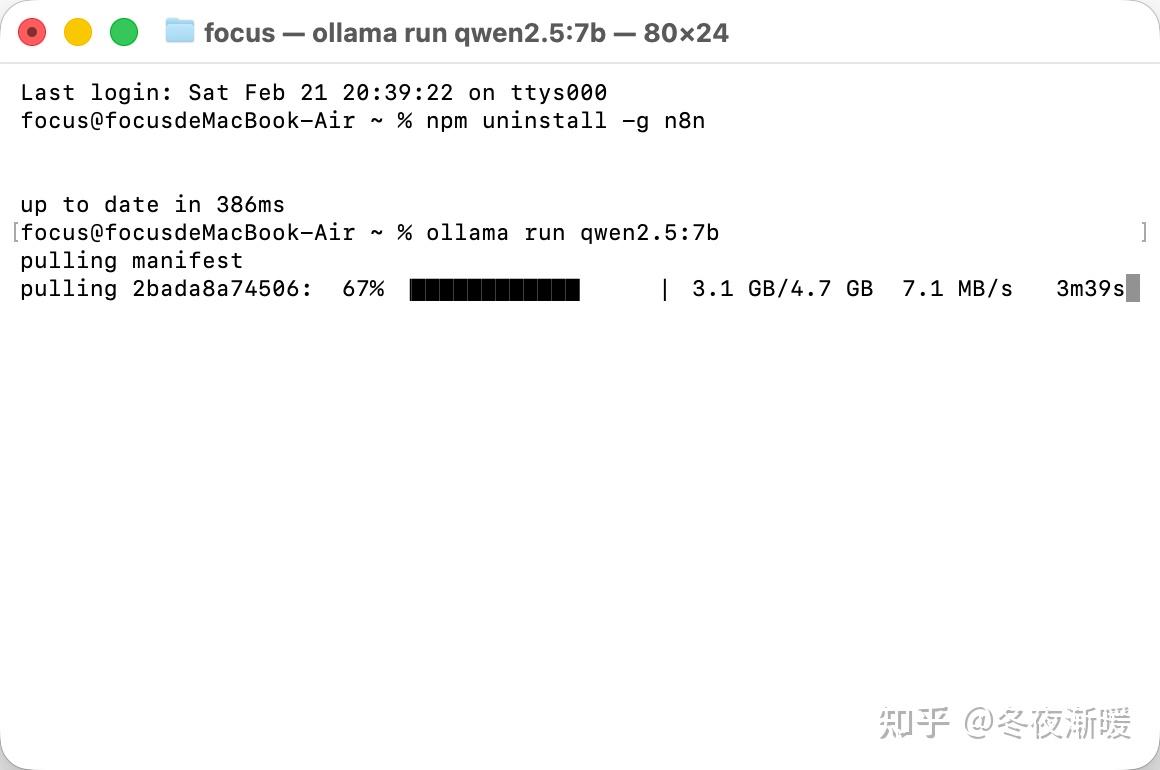
Ollama在终端里自动拉取大模型权重文件
第二步:安装前端界面 Open WebUI
一直对着黑框框敲字太反人类了。

我们需要一个像 ChatGPT 一样的漂亮网页。Open WebUI 是目前最强大的开源套件。
最简单的部署方式依然是 Docker。在你的电脑或 NAS 终端里运行:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main

跑完之后,在浏览器输入 http://你的IP:3000,注册一个本地管理员账号,你就会看到一个极其熟悉、精美的对话界面。
在右上角选择你刚才用 Ollama 下载的模型,开始畅聊吧!
四、 进阶玩法:把本地AI接入你的赛博管家 (n8n)
如果你看了我上一篇关于 n8n 自动化神器 的教程,现在就是“合体”的时候了!
- 在 n8n 的流程中,添加
Basic LLM Chain或AI Agent节点。 - 模型提供商(Model Provider)选择
Ollama。 - 填入你本地 Ollama 的 IP 地址(通常是
http://你的IP:11434)和模型名称。
效果:你的 n8n 自动化流程(比如总结邮件、分类微信消息),将彻底摆脱对外部付费 API 的依赖,完全由你家里的这台机器全天候免费处理!
【总结与购买建议】
本地 AI 算力平民化,是科技圈送给折腾党最好的礼物。
- 如果你是土豪/不想折腾代码:无脑冲 Mac mini (16G起步,推荐24G/32G),安静省电体验好。
- 如果你是实用主义者/游戏党:配一台主机,买张 RTX 3060 12GB,性价比无敌。
- 如果你是终极垃圾佬:翻出你吃灰的NAS,加满内存条,用纯CPU跑个小模型,体验一下从无到有的快乐!
你的家里现在有几张显卡?打算拿哪台设备来做你的“私人赛博大脑”?评论区聊聊看!