如何看待英伟达新推出的显卡RTX 5090 D v2 24GB?
这几天,科技圈的焦点完全被同一件事占据——英伟达CEO黄仁勋随特朗普访华期间,中方出手禁掉了RTX 5090D v2。老黄前脚刚走,禁令后脚落地,这消息一出,AI圈直接炸了。

你说奇怪不奇怪——一张游戏显卡被禁,玩家们还没急,反倒是AI圈哭声一片。为什么?因为这张卡的“真实身份”,远比你以为的复杂得多。今天我们就来把这水彻底搅浑——哦不,是讲明白——带你看透这场禁令背后,关于灰色算力、国产窗口和CUDA生态的暗战。
一、老黄前脚落地,禁令后脚跟上
先简单复盘一下时间线。
5月中旬,特朗普率团访华,黄仁勋临时加入代表团。外界当时普遍预测,这次行程有望推动H200等AI芯片的对华销售松绑。结果呢?AI芯片H200不仅没拿到采购许可,连5090D v2这张游戏卡都被中方主动拦下了。
据中国板卡业者证实,海关已通知相关物流公司,RTX 5090D v2不会获发进口通行证,所有相关货物均无法进入中国市场。与此前历次由美国发起的芯片出口限制不同,此次禁令由中方主动发起,令NVIDIA方面完全措手不及。

业内普遍分析认为,此次禁售与AI算力管制并无直接关联——因为5090D v2的AI算力早已被英伟达主动锁定。此举更像是释放明确信号:不再接受美国带有差别对待性质的降格产品,同时坚定推动国产芯片替代。
翻译成人话就是:“你们拿这种反复阉割的东西来敷衍我们,我们不伺候了。”
二、一张被扒了两层皮的显卡
那么,5090D v2到底“降格”到了什么程度,能让中方忍无可忍?
来,我带你扒一扒这张卡的“血泪史”。
最初,RTX 5090标准版因为美国出口管制,根本进不来。于是英伟达推出了5090D,做了第一轮“特供”——只锁算力,保留完整规格。
结果好景不长。2025年8月,初代RTX 5090D也被美国列入禁运清单。英伟达不得不紧急推出二次降级的特供版本,官方建议零售价维持16499元不变。
这第二刀砍得更狠——显存容量从32GB大幅削减至24GB(砍了25%),显存位宽从512-bit降至384-bit,带宽减少25%。实测游戏性能虽与旧版基本持平,但AI生产力性能下滑10%~25%。
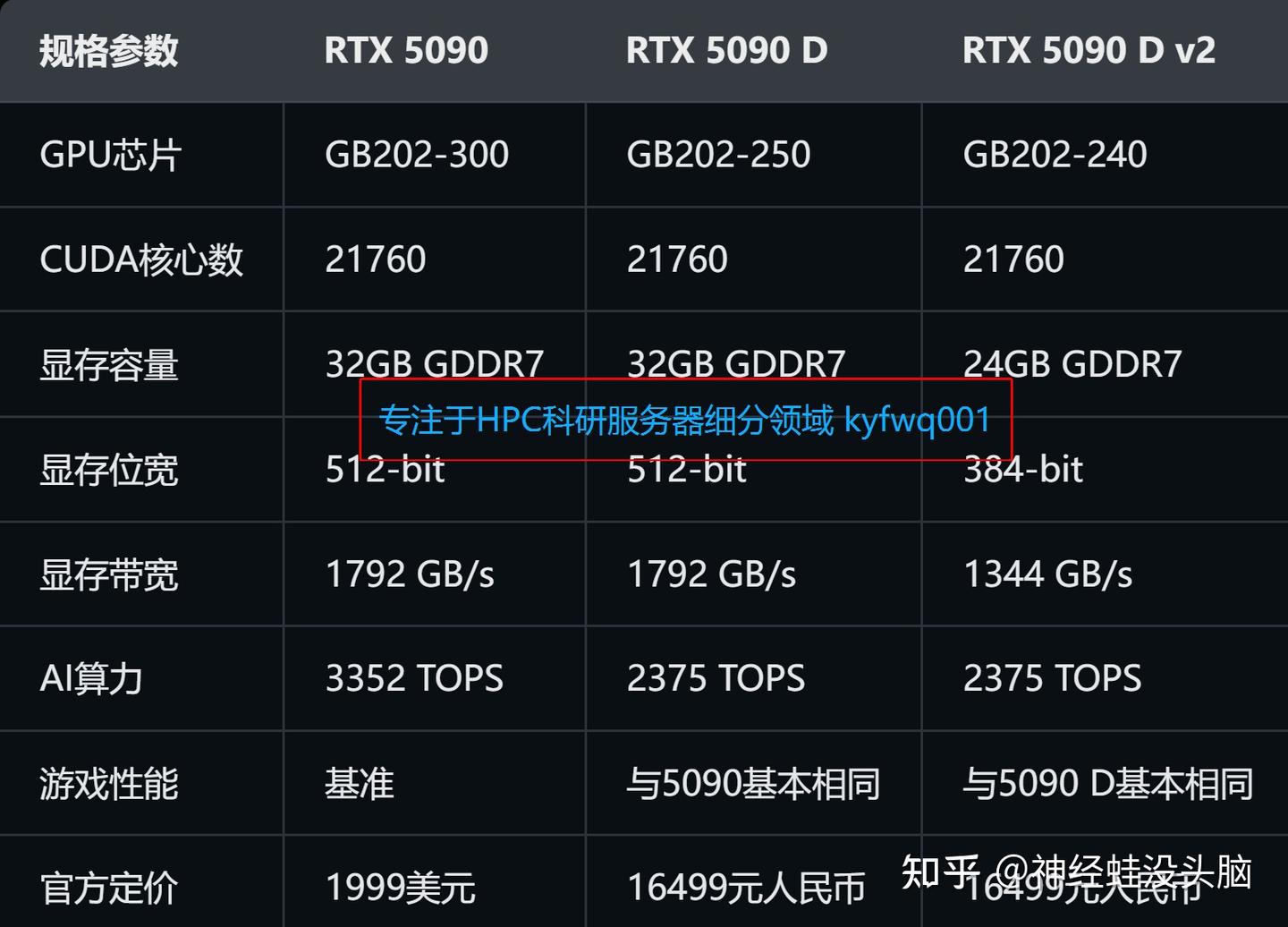
游戏玩家可能觉得24GB也够用了——但你知道对AI开发者来说,32GB到24GB意味着什么吗?意味着原本能跑70B大模型的机器,现在只能跑30B了。而价格,一毛钱没降。
一张被反复阉割两遍的卡,定价比标准版还贵,还要被当成“特供诚意”摆在货架上。 中方这次说不,等于是把这些“热脸贴冷屁股”的行为一次性怼了回去。
三、“游戏卡”的隐藏身份:中小AI团队的救命稻草
看到这儿,你可能还会问:AI圈到底为什么这么紧张?一张游戏卡而已,没有就没有呗,专业AI卡又不是没有。
问题恰恰出在这里。
对于普通玩家而言,24GB显存的5090D v2确实够用了。但对于AI初创团队和中小企业来说,这张卡的真实身份早就变了——它是中国AI圈里最普遍的“廉价算力来源”。
RTX 4090在FP16精度下理论算力达83.6 TFLOPS,实测中单卡可支持10亿参数级模型的实时推理。在很多工业质检、智慧零售场景下,一张消费级显卡就能撑起一整条AI业务线。这些中小企业买不起数百万美元的专业AI集群,但几千块到两万多美元一张的5090系列显卡,插几块就能跑起不少AI推理甚至微调任务。
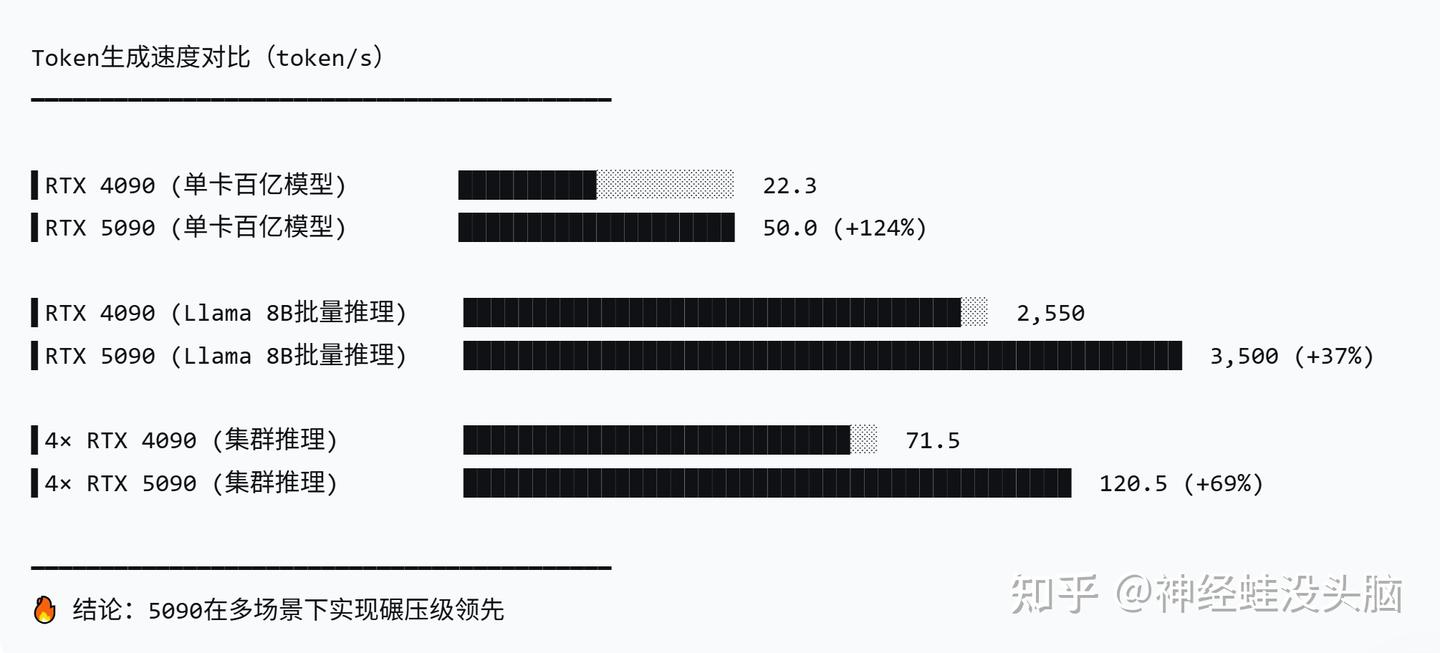
更魔幻的是,当正规AI芯片H20被美国卡住,大量中国企业开始用RTX 4090作为替代方案。消费级显卡在部分场景下的性价比远超合规的“特供版”AI芯片,有实测显示4090在FP16精度下的能效比还是A100的1.2倍。
现在5090D v2被禁,相当于砍断了一条重要的“灰色AI补给线”。对依赖多卡并行做AI研发的中小团队来说,这波阵痛是真真实实的。
但换个角度来看,这种“硬拆拐杖”式的操作,也是在倒逼整个产业走向真正的自主算力道路。
四、国产算力正在“翻盘”
为什么中方有底气下这个禁令?原因很简单——国产AI芯片已经不一样了。
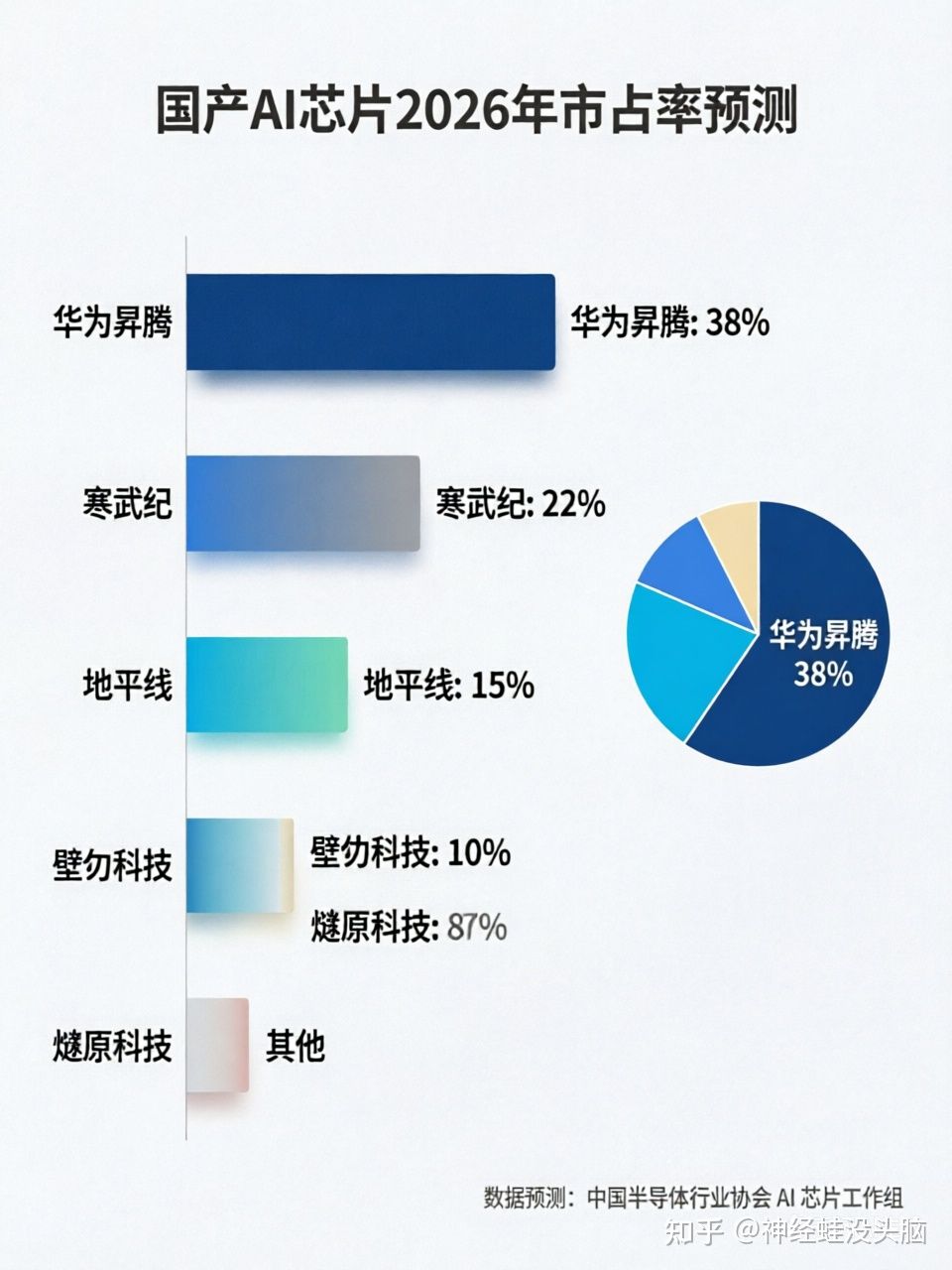
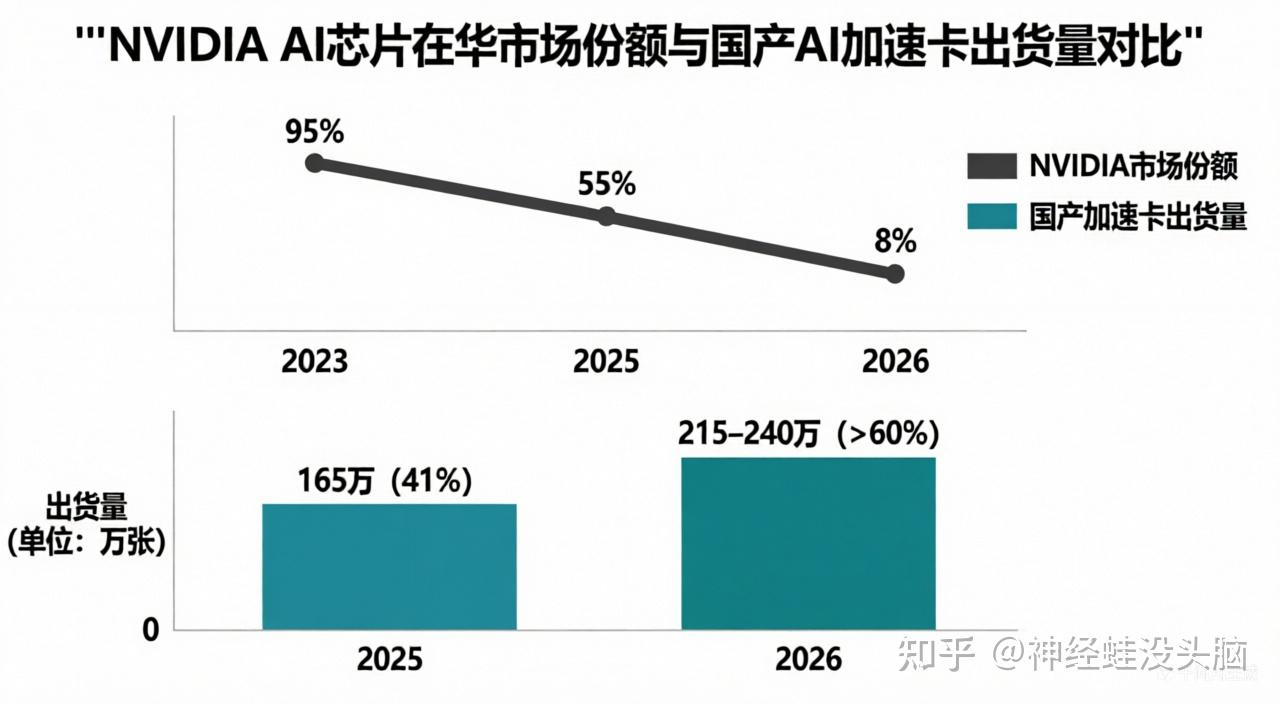
据机构统计,英伟达在中国AI芯片市场的份额已从三年前的95%暴跌至8%,国产AI加速卡市场份额突破60%。
具体到各厂商:
华为昇腾堪称“国产一哥”。2025年出货占比44%,是唯一能支持4万卡集群线性加速的国产芯片。权威机构预测,至2026年,华为昇腾有望在中国AI芯片市场独占50%的份额。
寒武纪走的是“性价比路线”。思元370在同等算力下价格仅为英伟达A10的三分之一,新一代思元590预计2026年出货30万颗。
海光信息的深算二号采用类CUDA架构,AI训练效率可达英伟达A100的80%,极大降低了迁移门槛。
摩尔线程的MTT S5000单卡AI稠密算力高达1000 TFLOPS,刚刚拿下国内首个万卡级国产全功能GPU系统订单,更兼容CUDA 12.8、支持3194个PyTorch算子。
在模型适配层面,好消息也是一个接一个。DeepSeek V4发布当天,华为昇腾、寒武纪、海光信息、摩尔线程、沐曦、昆仑芯、平头哥、天数智芯8家国产芯片同步完成“Day0”适配,模型发布即上线,无需额外调试周期。
更重要的是,禁令不止针对5090D v2。H200被中方拒绝采购,NVIDIA已于780亿美元的年度营收指引中将H200对华营收贡献下调至零。背后逻辑一以贯之:优先采购国产芯片。
所以,这次禁售本质上是在提前放大这些本土厂商的订单量和生存空间。“卡脖子”倒逼出来的国产算力,正在从“勉强能用”变成“越来越好用”。
五、CUDA才是真正的“天堑”
听到这儿,你可能已经兴奋了——国产AI芯片出货都60%了,那不是很快就能取代英伟达了吗?
且慢,我得泼一盆冷水。
硬件的进步只是第一步,真正的战场在于软件生态。英伟达真正的护城河从来不是GPU本身的算力优势,而是CUDA这个“事实标准”——它把开发者、企业、应用场景深度绑定,形成了难以撼动的生态壁垒。
数百万中国工程师从大学第一行GPU代码开始,接触的就是CUDA。把整个项目从CUDA生态迁移到国产平台,成本比给一台跑了20万公里的车换全套发动机还让人头疼。
好消息是,国产厂商们正在打一场“填坑战”:
- 华为CANN架构:对标CUDA的异构计算平台,能以较低资源成本实现CUDA到CANN的转换。
- 摩尔线程MUSA SDK 5.1.0:兼容CUDA 12.8,开源vLLM-MUSA,全力降低开发者的迁移摩擦。
- 软件适配提速:DeepSeek V4在八家国产芯片上“Day0”适配,标志着芯片厂商不再需要漫长的调试周期。
但必须承认,这套国产AI软件栈从“能用”到“好用”,从“好用”到“开发者心甘情愿地用”,依然是一场马拉松,不是百米冲刺。
迁移的阵痛,注定是未来几年内国产算力面临的最大挑战。
六、后续更狠的还在路上
一张游戏卡被禁,影响的远不止玩家。
韩国市场那边已经炸了——禁令一出,华硕TUF RTX 5090 OC一天之内从759万韩元涨到799万韩元(约3.62万元),Astral白夜神从779万涨到819万韩元(约3.71万元),涨幅均超过5%。这是担心中国玩家去海外扫货带来的恐慌性涨价。估计这只是个开始。
更值得关注的是,AI芯片领域也悬着一把更大的刀。2025年底,美国已批准H200出口中国,但中方至今未给予采购许可。如果再有一刀将H200这类合规AI芯片也全线收紧,整个中国AI产业链的算力供应结构将彻底换血。
对于中国企业和开发者来说,牌局已经变了。从“有什么用什么”到“合我意我才用”,这不是一道选择题,而是一场必须打赢的硬仗。
写在最后:算力的拐点,才刚刚开始
从最初的A800/H800被禁,到RTX 5090无法入华,再到5090D被二次降级,最后到5090D v2被中方自己拦在门外——英伟达的中国特供路线图,仿佛画出了一条走不出的死胡同。
而这一次,牌桌上的中国第一次从“被美国掐脖子”的角色,转为了“主动说不”的一方。
这个转变背后,是三年间国产AI芯片市场占比从不足5%做到超60%的硬核数据;是华为昇腾、寒武纪、海光、摩尔线程们在性能上步步紧逼的实体进度;是DeepSeek V4“Day0”适配八家国产芯片的生态共进。
转型期当然会有阵痛:依赖消费卡做AI的中小企业会感到压力;习惯了CUDA的开发者会面对迁移成本。但如果你把目光拉长,今天砸掉的这根“拐杖”,最终会逼出一条真正自主的算力之路。
一张游戏卡被禁,AI圈为什么炸?
因为这件事标志着:特供时代的落幕,和国产窗口的正式开启。
这盘大棋,才刚刚落子。
觉得这篇文章讲透了的,点赞、在看、转发三连走起~我们下期见!👇
H200放行,全球AI分流,国产算力要不要换一套打法? - 知乎
2025年最新技术参数、市场份额及应用场景的国产AI计算卡综合排名 - 知乎
超节点分析:ScaleX640、NVL72/144和Atlas 950/960 - 知乎
国产“GPU四小龙”加速崛起:两家上市中支持CUDA 两家仍在辅导 - 知乎
2025年内存“狂飙”涨价超预期——深度分析幅度、持续性及驱动逻辑 - 知乎
2025.11.28国产AI计算卡参数信息汇总 - 知乎 2025,国产智能算力芯片或将突破万亿市场? - 知乎
人形机器人产业链投资布局 2024,未来2万亿高增长市场 -神经蛙没头脑- 知乎
大模型简史:从Transformer(2017)到DeepSeek-R1(2025) - 神经蛙没头脑的文章 - 知乎

清华大学:DeepSeek从入门到精通(2025) - 神经蛙没头脑的文章 - 知乎
【2025科技参考指南】全年重磅事件一览,你绝对不能错过! - 知乎
2025 年 GPU 风云再起:NVIDIA RTX 50 系列登场,RTX 5070 凭啥叫板 4090? - 知乎
NVIDIA GB200 Superchip及各厂家液冷服务器和液冷机柜介绍 - 知乎
【英伟达GB300即将登场!】从“短命”GB200到“升级版”GB300,这场科技革命你必须知道! - 知乎
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
如何制造出比英伟达更好的GPU? - 知乎 (zhihu.com)

Nvidia B100/B200/GB200 关键技术解读 - 知乎 (zhihu.com)
大模型训练推理如何选择GPU?一篇文章带你走出困惑(附模型大小GPU推荐图) - 知乎 (zhihu.com)
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
AI核弹B200发布:超级GPU新架构30倍H100单机可训15个GPT-4模型,AI进入新摩尔时代 - 知乎 (zhihu.com)
紧跟“智算中心”这波大行情!人工智能引领算力基建革命! - 知乎 (zhihu.com)
先进计算技术路线图(2023) - 知乎 (zhihu.com)
建议收藏!大模型100篇必读论文 - 知乎 (zhihu.com)
马斯克起诉 OpenAI:精彩程度堪比电视剧,马斯克与奥特曼、OpenAI的「爱恨纠缠史」 - 知乎 (zhihu.com)
2023第一性原理科研服务器、量化计算平台推荐 - 知乎 (zhihu.com)
Llama-2 LLM各个版本GPU服务器的配置要求是什么? - 知乎 (zhihu.com)
人工智能训练与推理工作站、服务器、集群硬件配置推荐

整理了一些深度学习,人工智能方面的资料,可以看看
机器学习、深度学习和强化学习的关系和区别是什么? - 知乎 (zhihu.com)
人工智能 (Artificial Intelligence, AI)主要应用领域和三种形态:弱人工智能、强人工智能和超级人工智能。
买硬件服务器划算还是租云服务器划算? - 知乎 (zhihu.com)
深度学习机器学习知识点全面总结 - 知乎 (zhihu.com)
自学机器学习、深度学习、人工智能的网站看这里 - 知乎 (zhihu.com)
2023年深度学习GPU服务器配置推荐参考(3) - 知乎 (zhihu.com)

多年来一直专注于科学计算服务器,入围政采平台,GB200、H200、H100、A100、H800、A800、L40、L40S、RTX6000 Ada,RTX A6000,单台双路256核心服务器等。