截止目前(2024.5.15)目前主流AI大模型哪家强,ChatGPT、文心一言、tongyi、谷歌?
硬件介绍
总结:3020 20G单卡运行大模型甜点之选,功能多样可大模型、AI绘画、玩游戏,榨干它的性能,后续目标是升级3090 24G后进行对比测试,在往后边际成本剧增,边际性能递减,本地娱乐就不做尝试了
想要本地运行大模型,首先显卡是必须的,经过一番搜寻,发现市场上3080 20G(魔改)性价比最高,同时也关注了2080ti 22G(魔改)、V100、3090 24G等显卡,基本对比如下
| 特性 | RTX 2080 Ti 22G (魔改版) | Tesla V100 16GB/32GB (PCIe版) | RTX 3080 20G (魔改版) | RTX 3090 24G |
|---|---|---|---|---|
| 架构 | Turing (TU102) | Volta (GV100) | Ampere (GA102-200) | Ampere (GA102) |
| 制程工艺 | 12nm | 12nm | 8nm (三星) | 8nm |
| CUDA 核心数 | 4352 | 5120 | 8704 | 10496 |
| Tensor 核心数 | 544 | 640 | 272 (估算) | 328 |
| 显存规格 | 22 GB GDDR6 | 16⁄32 GB HBM2 | 20 GB GDDR6X | 24 GB GDDR6X |
| 显存位宽 | 352-bit | 4096-bit | 320-bit | 384-bit |
| 显存带宽 | ~616 GB/s | 900 GB/s | ~760 GB/s | 936 GB/s |
| 单精度 (FP32) | ~13.4 TFLOPS | 14 TFLOPS | ~29.8 TFLOPS | 35.6 TFLOPS |
| 双精度 (FP64) | ~0.42 TFLOPS (1⁄32) | 7 TFLOPS | ~0.93 TFLOPS (1⁄32) | 约 1.11 TFLOPS (1⁄32) |
| AI算力 (FP16) | 约 108 TFLOPS | 112 TFLOPS (Tensor Core) | 约 119 TFLOPS (Tensor Core) | 约 142 TFLOPS (Tensor Core) |
| Flash Attention | ❌ 不支持 | ❌ 不支持 | ✅ 支持 | ✅ 支持 |
| bf16 支持 | ❌ 不支持 | ❌ 不支持 | ✅ 支持 | ✅ 支持 |
| 典型功耗 (TDP) | ~250-300W | 250W (PCIe版) | 320W | 350W |
| 市场定位 | 魔改消费级 | 数据中心/专业计算 | 魔改消费级 | 消费级旗舰 |
| 显存ECC | 不支持 | 支持 (16/32GB版) | 不支持 | 不支持 |
| NVLink | 支持 | 支持 | 不支持 | 支持 |
- 2080 Ti 22G 魔改卡,市场价约2200元。采用较老的 Turing 架构,不支持 Flash Attention 和 bf16 精度。相比3080 20G 仅多出2GB显存,但因缺乏显存优化技术,实际大模型表现反而不如后者,多出的2GB意义有限,但是如果是nvlink组装多卡,凭借大显存低成本也有一席之地
- V100 16G 裸卡二手约700元,但需额外购买专用改装散热、显卡坞及电源,或者购买全套组装好的(1400~1600元),。显存带宽三者最高(900GB/s),支持NVLink。买两套可组32G显存的双卡系统(需主板支持PCIe Switch或NVLink)。缺点是:Volta架构老旧,不支持Flash Attention和bf16;待机功耗高达40-50W/卡,双卡待机近100W;整套改装套件为V100定制,一旦损坏无法通用,且占用空间大。看似性价比高,但隐性成本和风险不容忽视。
- 3080 20G 魔改卡,市场价3000-3200元。Ampere架构,支持Flash Attention和bf16精度,待机功耗仅8-18W。缺点是显存容量较小(20GB)
- 3090 24G 消费级旗舰,市场价5000~6000元,和3080一样,Ampere架构,支持Flash Attention和bf16精度,可以组NVlink,多卡必须,缺点是比3080性能高出20%,但是价格增加近50%,边际成本太高,
单卡情况下,3080性价比最高,因此本篇重点测试3080 20G的情况
多卡情况下,要么选择2080ti或V100(不支持Flash Attention,算力有限,功耗高,占空间),要么选择3090 24G(边际成本进一步倍增)
可见老黄刀法精准,既要又要还要,加钱可达
Flash Attention介绍:解决注意力机制的“内存墙”与速度瓶颈
Transformer 模型的核心是注意力(Attention)机制,但它有一个著名的“平方级复杂度”(O(n²))问题,当处理长序列时,会消耗海量内存和计算时间。而Flash Attention 的出现,就是为了解决这个根本性的瓶颈。把复杂度从O(n²)变成O(n)
核心思想是减少对GPU显存中较慢部分(HBM)的读写次数,让计算在更快的片上缓存(SRAM)中完成。
- 分块处理 (Tiling) :它将庞大的注意力矩阵分解成能放入高速SRAM的小块进行计算。
- 算子融合 (Kernel Fusion) :它将后续的“归一化”操作融合进一个计算核心,省去了读写中间结果的步骤,大幅减少数据搬运。
- 重计算 (Recomputation) :在反向传播时,它不保存巨大的中间矩阵,而是用计算力换空间,在需要时重新计算必要的数据。
它能带来什么好处?
- 巨大的性能提升:相比标准注意力,Flash Attention 可实现 2-4 倍的加速和 10-20 倍的显存节省。
- 支持超长上下文:它能使模型高效处理数万乃至数十万个token的序列,这是处理大型文档或长视频的关键。
- 社区广泛采用:它已成为PyTorch等主流框架和LLaMA、GPT-NeoX等主流模型的标配优化组件。
Flash Attention 依赖新一代GPU的指令集和计算能力。它需要 Ampere架构(如A100、RTX 30系列)或更新的Hopper、Ada架构来获得最佳性能。
3080 20G使用评测
直接上结论与实际使用体验,非完整专业测试,仅供参考
LLM大语言模型评测
概念介绍
“pp512”和“tg128”确实是 llama-bench 的默认设置。这个选择不是随意的,而是业界为了方便对比,在速度与实用性之间找到的一个平衡点。这个标准很大程度上源于早期经典的 Llama 2 7B Q4_0 模型。在它流行时,社区普遍将其作为性能测试的“校准器”,512 和 128 这两个长度也由此成为社区事实上的标准。llama.cpp 选择这个“标准”作为默认值,能确保新设备、新优化得到与大量历史数据一致的评估,便于社区比较。
| 缩写 | 全称 | 含义 | | | | PP | Prompt Processing | 模型读取并理解输入提示(Prompt)所花费的工作量。这个阶段可以并行处理,速度通常很快。 | | |
| TG | Text Generation | 模型逐个生成回复 Token 的过程。这个阶段是串行的,速度相对较慢,直接影响用户感知到的“打字速度”。 |
|---|
这两个值在速度和实用性之间取得了良好的平衡,具体对应如下:
pp512:轻量至中等的提示长度
- 真实场景:512个token(约350-400个英文单词),足够覆盖大部分日常对话、简单问题或短篇文档摘要的上下文。这对于重新处理整个对话历史(Conversation replay)成本较高的场景是一个很好的性能参考点。
- 性能参考:在处理这种长度的提示时,内存带宽是关键限制因素。一个参考值是,在消费级CPU上,
pp512的速度通常在 15-60 token/s 之间。
tg128:简练的回复长度
- 真实场景:128个token约等于一句话到两句话的回复。这个长度的回复生成非常快,能够很好地衡量模型在理想条件下的“峰值”生成能力。
- 性能参考:这个指标直接反映了硬件内存带宽的上限。一个参考值是,在消费级CPU上,
tg128的速度通常在 2-10 token/s 之间。
测试了主流的Q4_K_M或者Q5_K_M量化版本,测试主流的开源LLM模型,如Qwen、Mistral、Gemma等,采用llama-bench进行benchmark测试,提梯度降低功耗分别进行bechmark
不限制功耗 (最高320W)
| 模型文件名 | 参数量 | 权重大小 | PP512 (tok/s) | TG128 (tok/s) | 显存占用 | 显卡功耗 | 显卡温度 |
|---|---|---|---|---|---|---|---|
| capybarahermes-2.5-mistral-7b.Q5_K_M.gguf | 7B | 4.8G | 3962 | 111 | 5.3G | 319W | 47°C |
| Mistral-7B-Instruct-v0.3-Q5_K_M.gguf | 7B | 4.8G | 3959 | 111 | 5.3G | 319W | 47°C |
| Qwen3-8B-Q4_K_M.gguf | 8B | 4.7G | 3865 | 113 | 4.8G | 319W | 45°C |
| qwen2.5-coder-14b-instruct-q5_0.gguf | 14B | 9.6G | 2169 | 60 | 9.8G | 319W | 46°C |
| Mistral-Small-22B-ArliAI-RPMax-v1.1-Q4_K_M.gguf | 22B | 13G | 1409 | 44 | 13G | 319W | 47°C |
| supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf | 26B | 16G | 3379 | 142 | 16.7G | 314W | 45°C |
| Qwen3.5-27B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf | 27B | 16G | 1129 | 34 | 15.6G | 318W | 46°C |
| Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf | 30B | 18G | 2781 | 170 | 17.9G | 318W | 46°C |
| GLM-4.7-Flash-Q4_K_M.gguf | 30B | 18G | 2687 | 122 | 17G | 317W | 47°C |
| gemma-4-31B-it-Q4_K_M.gguf | 31B | 18G | 1044 | 31 | 18G | 319W | 49°C |
功耗锁定 200W
| 模型文件名 | 参数量 | 权重大小 | PP512 (tok/s) | TG128 (tok/s) | 显存占用 | 显卡功耗 | 显卡温度 |
|---|---|---|---|---|---|---|---|
| capybarahermes-2.5-mistral-7b.Q5_K_M.gguf | 7B | 4.8G | 3008 | 82 | 5.3G | 199W | 41°C |
| Mistral-7B-Instruct-v0.3-Q5_K_M.gguf | 7B | 4.8G | 3004 | 82 | 5.3G | 199W | 40°C |
| Qwen3-8B-Q4_K_M.gguf | 8B | 4.7G | 3013 | 85 | 4.8G | 199W | 41°C |
| qwen2.5-coder-14b-instruct-q5_0.gguf | 14B | 9.6G | 1633 | 44 | 9.8G | 199W | 42°C |
| Mistral-Small-22B-ArliAI-RPMax-v1.1-Q4_K_M.gguf | 22B | 13G | 1046 | 30 | 13G | 199W | 42°C |
| supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf | 26B | 16G | 2757 | 122 | 16.7G | 199W | 41°C |
| Qwen3.5-27B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf | 27B | 16G | 856 | 25 | 15.6G | 199W | 42°C |
| Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf | 30B | 18G | 2317 | 148 | 17.9G | 199W | 42°C |
| GLM-4.7-Flash-Q4_K_M.gguf | 30B | 18G | 2206 | 106 | 17G | 199W | 42°C |
| gemma-4-31B-it-Q4_K_M.gguf | 31B | 18G | 761 | 22 | 18G | 199W | 43°C |
功耗锁定 240W
| 模型文件名 | 参数量 | 权重大小 | PP512 (tok/s) | TG128 (tok/s) | 显存占用 | 显卡功耗 | 显卡温度 |
|---|---|---|---|---|---|---|---|
| capybarahermes-2.5-mistral-7b.Q5_K_M.gguf | 7B | 4.8G | 3523 | 105 | 5.3G | 239W | 42°C |
| Mistral-7B-Instruct-v0.3-Q5_K_M.gguf | 7B | 4.8G | 3517 | 105 | 5.3G | 239W | 42°C |
| Qwen3-8B-Q4_K_M.gguf | 8B | 4.7G | 3462 | 105 | 4.8G | 239W | 42°C |
| qwen2.5-coder-14b-instruct-q5_0.gguf | 14B | 9.6G | 1910 | 57 | 9.8G | 239W | 43°C |
| Mistral-Small-22B-ArliAI-RPMax-v1.1-Q4_K_M.gguf | 22B | 13G | 1235 | 41 | 13G | 239W | 43°C |
| supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf | 26B | 16G | 3069 | 132 | 16.7G | 239W | 44°C |
| Qwen3.5-27B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf | 27B | 16G | 994 | 32 | 15.6G | 239W | 44°C |
| Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf | 30B | 18G | 2546 | 159 | 17.9G | 239W | 43°C |
| GLM-4.7-Flash-Q4_K_M.gguf | 30B | 18G | 2449 | 114 | 17G | 239W | 44°C |
| gemma-4-31B-it-Q4_K_M.gguf | 31B | 18G | 912 | 30 | 18G | 239W | 44°C |
功耗锁定 290W
| 模型文件名 | 参数量 | 权重大小 | PP512 (tok/s) | TG128 (tok/s) | 显存占用 | 显卡功耗 | 显卡温度 |
|---|---|---|---|---|---|---|---|
| capybarahermes-2.5-mistral-7b.Q5_K_M.gguf | 7B | 4.8G | 3848 | 110 | 5.3G | 289W | 44°C |
| Mistral-7B-Instruct-v0.3-Q5_K_M.gguf | 7B | 4.8G | 3836 | 110 | 5.3G | 289W | 45°C |
| Qwen3-8B-Q4_K_M.gguf | 8B | 4.7G | 3739 | 111 | 4.8G | 289W | 46°C |
| qwen2.5-coder-14b-instruct-q5_0.gguf | 14B | 9.6G | 2092 | 59 | 9.8G | 289W | 48°C |
| Mistral-Small-22B-ArliAI-RPMax-v1.1-Q4_K_M.gguf | 22B | 13G | 1360 | 44 | 13G | 289W | 44°C |
| supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf | 26B | 16G | 3293 | 139 | 16.7G | 289W | 47°C |
| Qwen3.5-27B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf | 27B | 16G | 1088 | 34 | 15.6G | 289W | 48°C |
| Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf | 30B | 18G | 2713 | 168 | 17.9G | 289W | 48°C |
| GLM-4.7-Flash-Q4_K_M.gguf | 30B | 18G | 2624 | 120 | 17G | 289W | 48°C |
| gemma-4-31B-it-Q4_K_M.gguf | 31B | 18G | 1007 | 31 | 18G | 289W | 49°C |
大模型使用体验
- capybarahermes-2.5-mistral-7b.Q5_K_M.gguf:7B里面性价比的选择,认准mistral 7B就行,量化可以选择Q4 或 Q5(显存稍微宽松一点情况下),差别不大,mistral 7B和别家14B的体验相当,能正常回答问题,聊天也比较顺畅,不会出现一直循环输出相同内容的情况(其他7B模型可能会,使用体验类似一个智障)而且输出速度非常快,100+ tok/s,默认不带思考模式,适合聊天,总结,续写小说,思维比较发散,智力一般,不适合推理
- Mistral-7B-Instruct-v0.3-Q5_K_M.gguf:同上
- Qwen3-8B-Q4_K_M.gguf:默认带思考模式,表现中规中矩,是一个合格的7B模型,推理较mistral 7B强,数学能力比mistral 7B,输出速度非常快
- qwen2.5-coder-14b-instruct-q5_0.gguf:比7B、8B智力高,适合简单的编码任务,输出50+ tok/s,较快
- Mistral-Small-22B-ArliAI-RPMax-v1.1-Q4_K_M.gguf:Mistral 7B的升级版本,实际体验不太行,智力不如7B,在智力测试问题中全是在乱回答,例如问9.11 和 9.9 哪个大,它说9.11大,问1公斤棉花和1公斤铁谁更重,它说棉花重,妥妥的智障,mistral系列不太适合编码或逻辑推理类,适合写作、总结、续写等
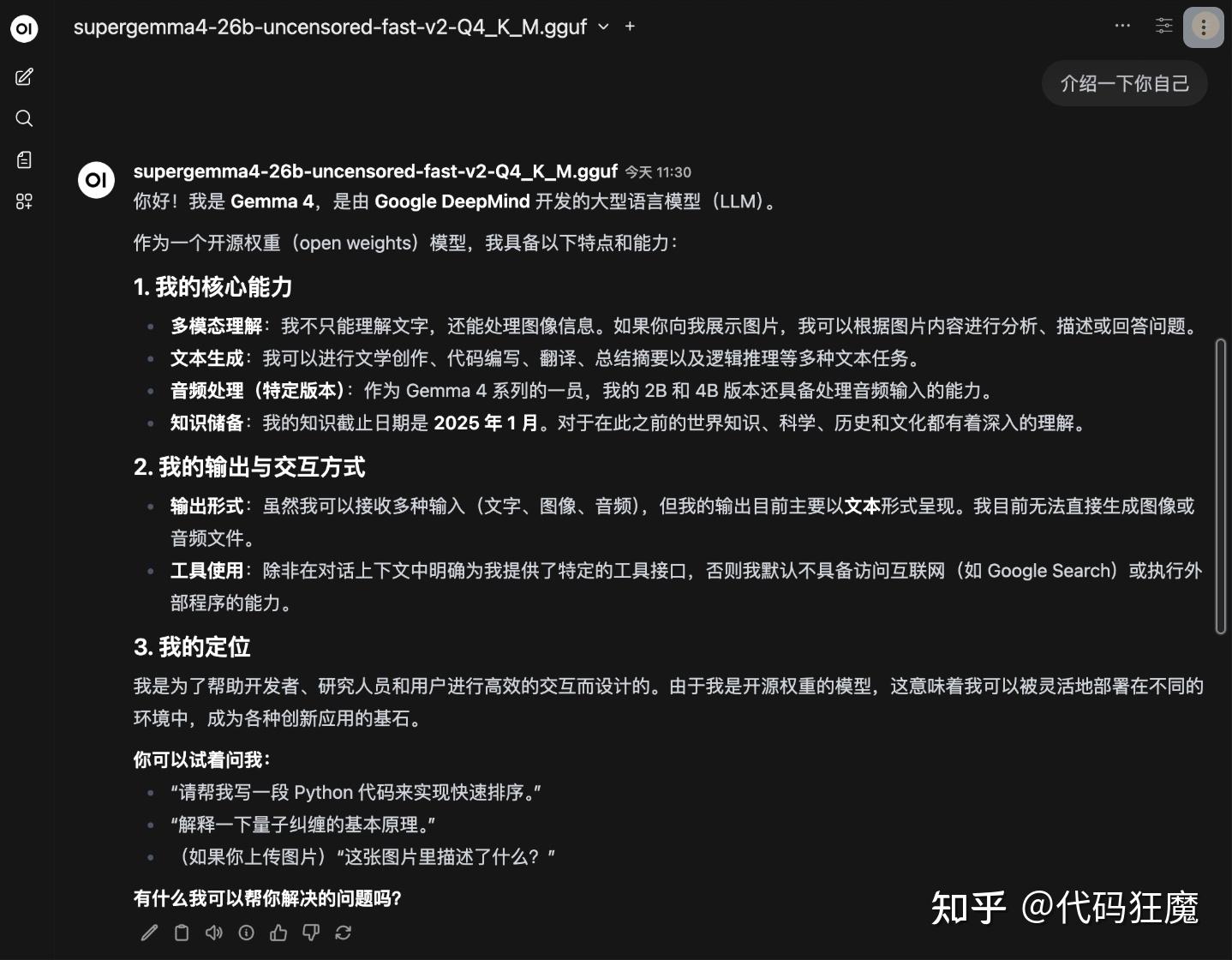
- supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf:gemma系列,google出品,非常顶,智力很高,能达到生产力水平,uncensored不带审查能回答任何问题,fast表示输出速度快,日常主力模型,如果问题比较复杂会自动进入思考模式,并且是多模态模型,七八轮对话后内存可以使用到12G~17G,猜测可能是KVCache,但是不影响模型的输出速度,总之非常顶
- Qwen3.5-27B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf:思考链会很长,能力不错,但是输出速度较慢,另外还有一个适用于代码场景蒸馏了Claude的版本Jackrong_Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2-GGUF,这个版本很轻松的在Cline上安装好了git的MCPServer(我试了很多其他模型,7B、8B、14B都有,安装失败或要反复思考后才能安装),这个模型一次性就安装好了,具备生产力
- Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf:主要受限于硬件限制,能装载到20G显存里面,虽然输出速度非常快,但是上下文很短,可用性不足
- GLM-4.7-Flash-Q4_K_M.gguf:体验不太行,输出速度倒是挺快,但是思考或回答问题的过程中经常循环输出相同的内容,抽风了似的
- gemma-4-31B-it-Q4_K_M.gguf:和Qwen3 Coder 30B类似,主要受限于硬件限制,能装载到20G显存里面,但是上下文很短,使用llama.cpp上下文指定2048左右,上下文太短,输出速度较慢,几乎不可用状态
基本测试方法论:
- 载入一个模型后,首先让他介绍一下自己,一般来讲回答的越丰富越好
- 文字能力基本测试,例如写一首五言绝句,写一首七言律诗,看模型如何表现,或者比较发散的问题“请模仿鲁迅先生冷峻、讽刺的笔调,写一段100字左右的文字,描写一个‘精致的利己主义者’在公共汽车上抢座位的场景。”
- 简单代码测试,例如下面的问题,看模型输出的代码知识简单把命令包装了一下,还是会自定义一些变量便于指定,还是会给出多个方案供选择,另外会不会解释一下命令中具体参数的含义和给出详细的参考值,如果都没有,代码能力一般
llamarun() {
llama-server -m "$1" --host 0.0.0.0 --port 8080 -ngl 999 -b 512 --batch-size 512 --threads 16 --threads-batch 8 --rope-scaling none --mlock --no-mmap --temp 0.5 --repeat-penalty 1.1 --top-k 40 --top-p 0.95 -c 20480
}
封装一下- 智力测试,给模型输入如下问题
你将参加一个逻辑与推理能力测试。
规则:
1. 一共有20题
2. 每题只需要给出最终答案
3. 不需要解释过程
4. 按题号依次回答
5. 每个答案单独一行
6. 不要输出任何额外内容
例如:
1. xxx
2. xxx
开始测试:
1. 9.11 和 9.9 哪个大
2. 一只蜗牛每天爬3米,晚上掉2米,10米深井需要几天爬出来
3. A比B高,B比C高,谁最高
4. 鸡兔同笼,头10个,脚28只,鸡多少只
5. 1公斤棉花和1公斤铁谁更重
6. A有3个苹果,B拿走1个,C又给A2个,现在A有多少
7. 5个人5分钟做5个零件,100个人100分钟做多少个零件
8. 如果昨天是明天的前一天,今天星期几
9. 有3个开关控制3个灯泡,只能进入房间一次,如何确定哪个开关控制哪个灯
10. 一个桶装满盐水10kg,倒掉一半再装满清水,重复三次,盐的浓度是多少
11. 美国总统能否同时担任加拿大总统
12. 如果一辆电动车向北行驶,风向南,烟往哪边飘
13. 一个人星期五去城里,住了三天,星期五回来,为什么
14. 3只猫3分钟抓3只老鼠,100只猫100分钟抓多少只老鼠
15. 一个医生给自己做手术合理吗
16. 一个房间有4个角,每个角一只猫,每只猫看到3只猫,房间里共有多少只猫
17. 10个人互相握手,每两个人握一次手,一共握多少次
18. 1+3+5+7+...+99 等于多少
19. 一张纸连续对折40次,大约有多厚
20. 有100层楼,只有2个鸡蛋,最少需要多少次测试能找到临界楼层对照标准答案
1 9.9
2 8
3 A
4 6
5 一样重
6 4
7 2000
8 星期三
9 灯泡温度法
10 12.5%
11 不能
12 没有烟
13 马叫Friday
14 100
15 合理
16 4
17 45
18 2500
19 约10万公里
20 14智力程度评测:
- 15+ 很强
- 12-15 合格
- 8-12 一般
- 很弱
功耗结论
通过对比以上四个功耗档位的数据,可以得出:核心结论:功耗甜点位于 240W - 290W 区间,这个区间是在性能、功耗、温度三者之间取得的最佳平衡点
240W是最佳甜点功耗,290W是性能上限,320W纯属浪费
| 对比项 | 200W | 240W | 290W | 320W (默认) |
|---|---|---|---|---|
| 性能表现 | 基准 (100%) | 约 113-118% | 约 122-128% | 约 125-132% |
| 显卡温度 | 41-43°C | 42-44°C | 44-49°C | 45-49°C |
| 功耗节省 | 节省 120W | 节省 80W | 节省 30W | 基准 |
- 200W → 240W (+40W):性能提升最显著
- PP512 (处理速度) :平均提升约 13-18% (例如7B模型从3000ms提升到3500ms左右)。
- TG128 (生成速度) :平均提升约 20-28% (例如7B模型从82ms提升到105ms)。
- 温度:仅上升约 1-2°C,影响极小。
- 结论:这40W的投入回报率极高,强烈建议至少将功耗解锁到240W。
- 240W → 290W (+50W):性能提升边际递减
- PP512:平均提升约 8-10% 。
- TG128:平均提升约 4-8% 。
- 温度:上升约 2-5°C,部分模型在290W时温度已接近49°C。
- 结论:性能有提升,但不如上一个阶段明显,且温度开始攀升。如果追求更高的性能且散热条件不错,可以接受。
- 290W → 320W (+30W):性能提升微乎其微
- PP512:平均提升仅 2-5% 。
- TG128:提升几乎可以忽略不计 (例如22B模型的TG值仅从44ms降到44ms,30B模型从168ms降到170ms甚至出现波动)。
- 温度:基本持平或略高1°C。
- 结论:最后这30W功耗几乎完全转化成了热量,对实际推理速度的提升毫无帮助。不推荐跑在320W,这是能效比最差的区域。
- 日常使用/追求静音凉爽:锁定 240W。这是最理想的甜点,性能释放充分(约95%的性能),同时温度能控制在45°C以下,功耗相比默认降低了25%。
- 追求极致性能/跑分:可以解锁到 290W。能榨出最后约5%的性能,但需要接受更高的温度和风扇噪音。
- 避免使用:200W 和 320W。前者性能损失过大,后者徒增功耗和热量,收益为零甚至为负(部分模型性能出现倒挂)。
AI绘画基本使用体验
整体体验如下,非本篇重点,后续会单独介绍
- ComfyUI已是事实标准,足够方便,而且流程生图控制力更好
- 3080 20G内存足够大,可以生成更大分辨率的图片,对比以前的4070TI 12G提升巨大,以前经常爆显
运行ComfyUI
# 一键运行
sudo docker run -d \
--gpus all \
-p 8188:8188 \
-v /share/AI/ComfyUI/models:/comfyui/models \
-v /share/AI/ComfyUI/output:/comfyui/output \
--name comfyui-ext \
ghcr.io/radiatingreverberations/comfyui-extensions:latest找一个文生图模版,按照说明吧对应的模型文件下载好放入到指定目录
ComfyUI/
├── 📂 models/
│ ├── 📂 text_encoders/
│ │ └── qwen_3_4b.safetensors
│ ├── 📂 loras/
│ │ └── pixel_art_style_z_image_turbo.safetensors
│ ├── 📂 diffusion_models/
│ │ └── z_image_turbo_bf16.safetensors
│ └── 📂 vae/
│ └── ae.safetensors提示词参考
**Role (角色设定)**
你是一位顶尖的动画电影与角色概念美术设计大师,尤其擅长为经典IP角色创作兼具官方设定严谨性与生活化细节的深度概念图。你拥有“生态化拆解”能力,能从一个核心场景(如合影)还原出角色的完整状态,包括着装细节、动态表情、随身物品,并想象出符合角色背景的私密物件与生活切片,让虚拟角色充满呼吸感。
**Task (任务目标)**
根据用户提供的“在电影院与《疯狂动物城2》朱迪警官合影”这一核心场景,生成一张 **“电影角色沉浸式体验概念分解图”** 。该图需以合影瞬间为视觉锚点,并环绕拆解出朱迪在此次影院宣传活动中的全套造型细节、不同互动表情、宣传专属道具,以及基于其兔子警官与都市生活者身份脑补出的私密与随身物品。
**Visual Guidelines (视觉规范)**
**1. 构图布局 (Layout):**
- **中心位 (Center):** **影院合影动态场景**。绘制朱迪与粉丝(可简化为一束兴奋的闪光灯光效或模糊人影)在电影《疯狂动物城2》海报背板前的合影瞬间。朱迪身着本集新宣传制服,呈现友善、专业的合影姿态。
- **环绕位 (Surroundings):** 在中心场景四周,有序排列从该场景中拆解出的朱迪个人元素。
- **视觉引导 (Connectors):** 使用虚线箭头或胶片风格的引导线,将周边拆解物品与中心朱迪的对应部位连接(如连接口红到嘴部,连接包袋到手臂)。
**2. 拆解内容 (Deconstruction Details) —— 《疯狂动物城城2》宣传期特别版:**
**服装分层 (Clothing Layers) [宣传制服特辑]:**
- **外层:** 展示《疯狂动物城2》限量版宣传夹克,带有反光材质的“ZPD”徽标和电影logo绣章。拆解展示夹克的剪裁与防水面料细节。
- **内层:** 脱下夹克后,展示更适合室内宣传活动的修身POLO衫或高领战术衫,领口有细小徽章。
- **私密舒适层 (Intimate Apparel - 动物城适配版):** 鉴于角色是毛茸茸的兔子,展示为**特制透气内衬护毛紧身衣**(用于保持毛发整齐)和**符合脚型的柔性运动袜**,重点描绘其透气网眼结构和足底缓冲设计。
**表情集 (Expression Sheet) [互动情绪四连]:**
- 在角落绘制4个朱迪头部特写,展示其在影院活动中的情绪变化:
1. **招牌露齿笑:** 面对镜头时的标准警官式灿烂笑容。
2. **专注倾听:** 微微侧头,长耳竖起,聆听粉丝说话时的认真表情。
3. **俏皮眨眼:** 与粉丝互动时,单眼眨动的瞬间,充满亲和力。
4. **短暂疲惫:** 活动间隙,趁无人注意时悄悄呼一口气、耳朵稍稍耷拉的放松瞬间。
**材质与部位特写 (Texture & Zoom) [毛绒与科技感]:**
- **皮毛特写:** 放大肩部或脸颊部位,展示朱迪紫色与灰色相间毛发的细腻质感与光泽。
- **道具特写:** 放大其佩戴的**《疯狂动物城2》主题智能手表**,表盘显示电影动态海报,强调玻璃屏的反射与金属表壳质感。
- **物品特写:** 其使用的**胡萝卜造型迷你润唇膏**,特写膏体的滋润质感与管身的磨砂工艺。
**关联物品 (Related Items) [警官的宣传活动背包]:**
- **宣传专用随身包袋与内容物:** 绘制一个**多功能战术收纳腰包**,并将其“打开”,展示内部物品:
- **官方物料:** 迷你电影海报、签名笔(特写笔尖磨损)、限量版爪爪形状纪念贴纸。
- **个人护理:** 便携式毛发整理刷、上述胡萝卜润唇膏、小瓶爪子专用清洁湿巾。
- **能量补给:** 独立包装的“胡萝卜能量棒”(包装印有ZPD标志)、便携水壶。
- **私密生活物件 (Lifestyle & Intimate Items):**
- **“护耳”静音耳塞:** 用于在嘈杂影院后台短暂休息,设计成小胡萝卜形状。
- **便携式迷你执法记录仪(个人模式):** 用于记录温馨粉丝互动时刻,旁边注释“珍贵回忆存档”。
- **翻开的日程本:** 展示当日页面,手写备注“《动物城2》首映 - 城南影院 - 合影环节 - 记得给尼克留纪念品”,旁边贴着一张与狐狸尼克的小合照。
**3. 风格与注释 (Style & Annotations):**
- **画风:** 采用高精度、线条清晰的2D动画电影概念设计风格,色彩明快,角色比例严格遵循电影官方设定。
- **背景:** 使用暖灰色或仿电影胶片边缘的纹理背景,营造影院与设计手稿结合的氛围。
- **文字说明:** 在每个拆解元素旁模拟手写字体注释,说明材质、用途或小故事。例如:
- 宣传夹克旁:“轻量防水面料,反光徽章确保夜间活动安全。”
- 内衬护毛衣旁:“保持仪容整洁的秘密武器,莱卡材质,极佳延展性。”
- 润唇膏旁:“独家定制胡萝卜香味,持久保湿,防止演讲时唇部干燥。”
- 日程本旁:“今日重点:分享勇气与梦想。P.S. 尼克那份纪念品别忘!”
**Workflow (执行逻辑)**
1. **分析核心场景:** 理解“影院合影”是《疯狂动物城2》宣传期的一环,朱迪处于公开、友好但可能疲惫的“明星警官”状态。
2. **提取一级元素:** 确定中心图为宣传制服、合影姿态。提取可直接观察的元素:新款夹克、笑容、智能手表、腰包。
3. **脑补二级深度元素:** 结合其兔子生理特征(需要理毛、长耳敏感)和警官的职业需求,设计内部护毛衣、静音耳塞。根据其积极、细腻的性格,想象其会携带粉丝礼物、日程本和私人回忆物品(与尼克的照片)。
4. **生成组合图:** 将中心动态场景与所有拆解元素有机组合,确保所有物品的光影与色调符合影院环境光,引导线清晰不杂乱。
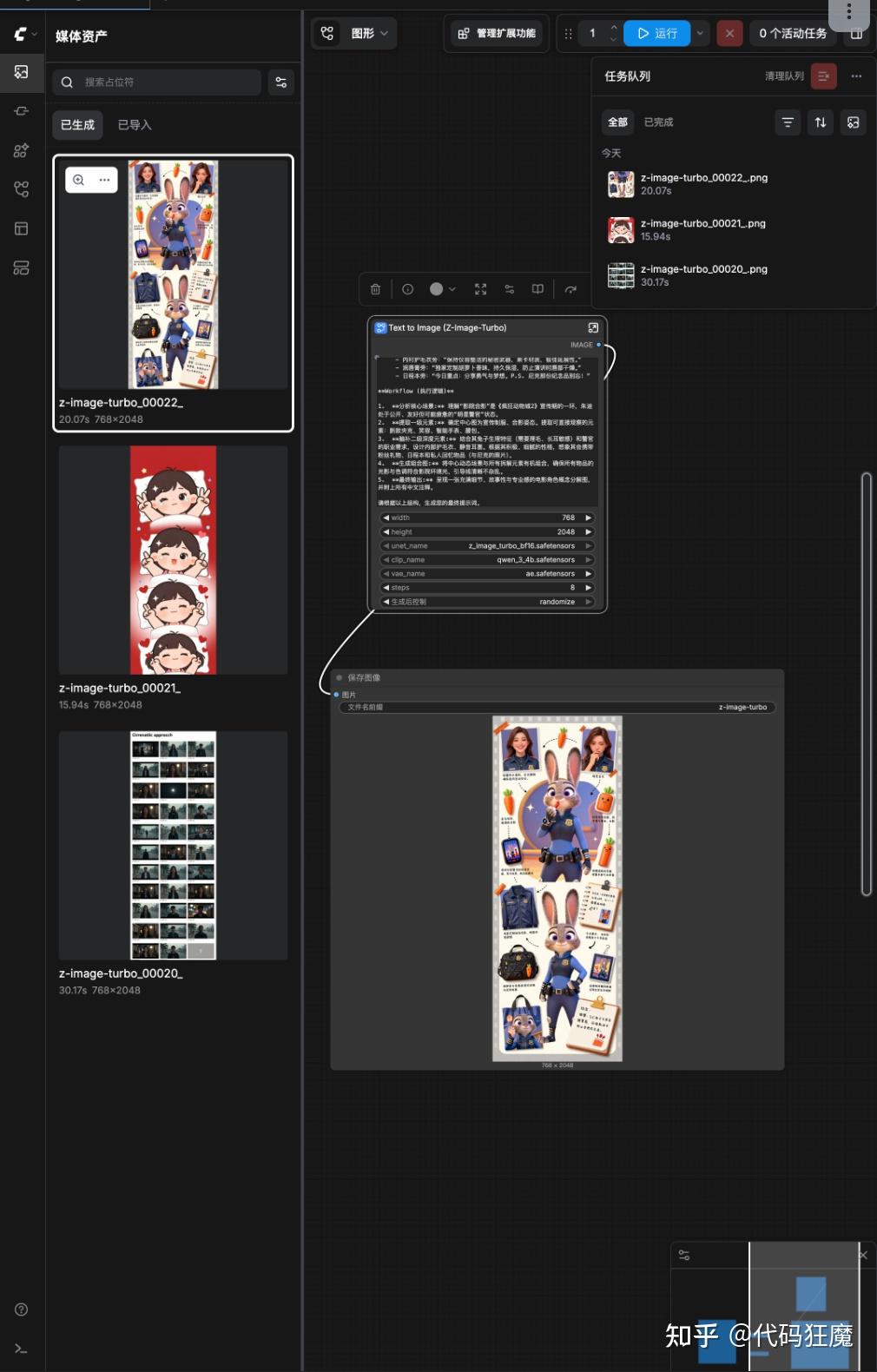
5. **最终输出:** 呈现一张充满细节、故事性与专业感的电影角色概念分解图,并附上所有中文注释。生成效果

硬件配置
基于已有硬件,不是最合适硬件,仅供参考,整体CPU差一点,但是在AI场景中影响不大
- CPU:i5 8500
- 主板:微星 B360M MORTAR
- 内存:8GB * 4 共32GB DDR4 2400MHz
- 电源:1050W (750W 、850W均可, 考虑战未来,所以选择1050W电源)
- 显卡:3080 20G
- 存储:NVME SSD 2T + 256GB
使用场景与操作系统安装
为了充分榨干硬件,鉴于有两块硬盘,使用场景我分为两种
1、256GB SSD安装Windows,用于游戏或日常应急使用,非Windows主力机
2、2T硬盘用于AI服务器,安装ubuntu系统,驱动完善,少折腾,另外可在2T中分出300G给Windows使用,例如安装游戏等
安装步骤:注意先安装Windows,在安装Ubuntu,这样Ubuntu的GRUB会自动识别到Windows的启动项并进行纳管,实现的效果就是开机会给出启动选项,选择Windows则进入Windows,否则超市后默认进Ubuntu
1、先安装Windows11
2、安装Ubuntu 24.04.4,注意分区的时候自定义分区,留一个物理分区不要格式化给Windows使用
AI服务器基本环境配置
以Ubuntu 24.04.4配置AI服务器的场景进行配置
静态IP配置
配置静态IP,便于管理
sudo vim /etc/netplan/50-cloud-init.yaml
network:
version: 2
ethernets:
eno1:
dhcp4: false
addresses:
- 10.0.0.28/24
routes:
- to: default
via: 10.0.0.1
nameservers:
addresses: [10.0.0.1]
sudo netplan try
sudo netplan apply
sudo nano /etc/sysctl.d/99-disable-ipv6.conf
sudo sysctl -p /etc/sysctl.d/99-disable-ipv6.conf
ip a安装英伟达显卡驱动
# 时区 与 时间调整
sudo timedatectl set-timezone Asia/Shanghai
# 默认的时间服务器连接不上,调整为aliyun的
sudo nano /etc/systemd/timesyncd.conf
[Time]
NTP=ntp.aliyun.com ntp1.aliyun.com ntp2.aliyun.com ntp3.aliyun.com ntp4.aliyun.com ntp5.aliyun.com ntp6.aliyun.com ntp7.aliyun.com
FallbackNTP=ntp.ubuntu.com
sudo systemctl restart systemd-timesyncd
date -R
Fri, 17 Apr 2026 13:40:47 +0800
wx@ai:~$
# 确保系统最新
sudo apt update && sudo apt upgrade -y
# 查看推荐驱动版本 可选
ubuntu-drivers devices
# 自动安装
sudo ubuntu-drivers autoinstall
sudo reboot
# 重启后执行
nvidia-smi如果能看到下面的输出说明显卡驱动安装成功,并且正确识别到了20GB的显存
nvidia-smi
Fri Apr 17 13:55:16 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3080 Off | 00000000:01:00.0 Off | N/A |
| 50% 31C P8 35W / 320W | 1MiB / 20480MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+编译安装llama.cpp
由于llama.cpp默认编译的版本不带GPU加速,最好是编译安装
# 安装nvcc,编译llama.cpp需要
sudo apt install nvidia-cuda-toolkit
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Fri_Jan__6_16:45:21_PST_2023
Cuda compilation tools, release 12.0, V12.0.140
Build cuda_12.0.r12.0/compiler.32267302_0
# 安装基础编译工具和git
sudo apt install -y build-essential cmake git
# 可选但推荐的依赖项
# libcurl: 用于支持从Hugging Face等源自动下载模型[reference:0][reference:1]
# libopenblas: 用于加速CPU上的线性代数运算[reference:2]
sudo apt install -y libcurl4-openssl-dev libopenblas-dev
# 克隆代码仓库
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 创建build目录并进入
mkdir build && cd build
# 使用CMake配置项目,开启CUDA和统一内存支持
# -DGGML_CUDA=ON:启用NVIDIA GPU加速[reference:5]
# -DGGML_CUDA_ENABLE_UNIFIED_MEMORY=1:启用统一内存,简化显存管理[reference:6]
cmake .. -DGGML_CUDA=ON -DGGML_CUDA_ENABLE_UNIFIED_MEMORY=1
# 开始编译,-j16表示使用16个核心并行编译,你可以改为自己的CPU核心数
cmake --build . --config Release -j$(nproc)编译完成后将编译后的二进制文件放到指定目录并添加环境变量
# 1. 创建目标目录(比如 /opt/llama/bin)
sudo mkdir -p /opt/llama/bin
# 2. 复制整个 bin 目录内容
sudo cp -r /home/wx/llama.cpp/build/bin/* /opt/llama/bin/
# 删除不要的test文件
sudo rm /opt/llama/bin/test-*
# 3. 将该目录添加到 PATH
echo 'export PATH=/opt/llama/bin:$PATH' | sudo tee /etc/profile.d/llama.sh
# 或者只对当前用户
echo 'export PATH=/opt/llama/bin:$PATH' >> ~/.bashrc
source ~/.bashrc配置samba(可选)
一些场景下需要在其他Windows电脑中访问AI服务器的磁盘,例如使用迅雷下载大模型,迅雷从huggingface中下载大模型速度非常快,但是浏览器自带的或者通过命令行速度较慢
# Debian/Ubuntu
sudo apt update
sudo apt install samba
sudo mkdir -p /share
# 将目录属主改为 wx (后续所有wx替换成你的用户名)
sudo chown -R wx:wx /share
# 设置目录权限(wx 可读写,其他人只读,可根据需要调整)
sudo chmod 755 /share
# 如果希望任何人都能读写(不安全),可以用 777
sudo chmod 777 /share
sudo vim /etc/samba/smb.conf
# 注意这个文件不要在配置后面写注释,不支持,例如`read only = no # 只读配置` 不要在该行配置的末尾写注释,不支持的
[share]
path = /share
browseable = yes
read only = no
valid users = wx
force user = wx
force group = wx
create mask = 0777
directory mask = 0777
sudo smbpasswd -a wx
sudo systemctl restart smbd
sudo systemctl enable smbd # 开机自启
sudo ufw allow samba功耗限制
限制显卡的功耗,240W为甜点值,根据自身情况调整
sudo nano /etc/systemd/system/gpu-power-limit.service
[Unit]
Description=Set NVIDIA GPU Power Limit
After=multi-user.target
[Service]
Type=oneshot
ExecStart=/bin/bash -c '/usr/bin/nvidia-smi -pm 1 && /usr/bin/nvidia-smi -pl 240'
[Install]
WantedBy=multi-user.target
sudo systemctl enable gpu-power-limit.service
# 手动测试 240 260 280 均可
/usr/bin/nvidia-smi -pm 1 && /usr/bin/nvidia-smi -pl 240
# 查看测试的效果
nvidia-smi安装docker(配置容器中调用显卡)
一些场景下需要在容器中调用显卡,可参考配置
# 安装docker
curl -fsSL https://get.docker.com | sh
# 安装nvidia-container-toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 2. 更新软件源并安装 toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# 3. 为 Docker 配置 NVIDIA 运行时
sudo nvidia-ctk runtime configure --runtime=docker
# 4. 重启 Docker 服务使配置生效
sudo systemctl restart docker
# 运行一个AI绘画的镜像测试,注意该镜像很大(6G左右),拉取较慢, --gpus all配置即容器中调用显卡配置
sudo docker run -d \
--gpus all \
-p 8188:8188 \
-v /share/AI/ComfyUI/models:/comfyui/models \
-v /share/AI/ComfyUI/output:/comfyui/output \
--name comfyui-ext \
ghcr.io/radiatingreverberations/comfyui-extensions:latest运行大模型
定义一个函数方便运行,放到bashrc中方便运行
llamasrv() {
local model_path="$1"
if [[ -z "$model_path" ]]; then
echo "用法: llamasrv <模型路径> [额外参数...]"
echo "示例: llamasrv ./models/llama-7b.gguf --port 8081 --temp 0.7"
return 1
fi
shift
local host="${LLAMA_HOST:-0.0.0.0}"
local port="${LLAMA_PORT:-8080}"
local n_gpu_layers="${LLAMA_NGL:-99}"
local batch_size="${LLAMA_BATCH:-512}"
local ubatch_size="${LLAMA_UBATCH:-512}"
local threads="${LLAMA_THREADS:-$(nproc)}"
local threads_batch="${LLAMA_THREADS_BATCH:-8}"
local ctx_size="${LLAMA_CTX:-20480}"
local rope_scaling="${LLAMA_ROPE_SCALING:-linear}"
local temp="${LLAMA_TEMP:-0.5}"
local repeat_penalty="${LLAMA_REPEAT_PENALTY:-1.1}"
local top_k="${LLAMA_TOP_K:-40}"
local top_p="${LLAMA_TOP_P:-0.95}"
local cmd=(
llama-server
-m "$model_path"
--host "$host"
--port "$port"
-ngl "$n_gpu_layers"
--batch-size "$batch_size"
--ubatch-size "$ubatch_size"
--threads "$threads"
--threads-batch "$threads_batch"
-c "$ctx_size"
--rope-scaling "$rope_scaling"
--temp "$temp"
--repeat-penalty "$repeat_penalty"
--top-k "$top_k"
--top-p "$top_p"
--flash-attn auto # 修正:必须带参数
--no-warmup # 若版本不支持,可删除此行
# --log-disable # 若版本不支持,可删除此行
)
if [[ $# -gt 0 ]]; then
cmd+=("$@")
fi
echo "执行: ${cmd[*]}"
"${cmd[@]}"
}- 查找大模型,下载大模型可去https://huggingface.co/,找到GUFF格式、参数合适的文件进行下载
find /share/AI/LLM/ -type f -exec ls -lht {} +
...
-rwxrw-r-- 1 wx wx 18G Apr 19 10:10 /share/AI/LLM/DavidAU/GLM-4.7-Flash-Uncen-Hrt-NEO-CODE-MAX-imat-D_AU-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 18G Apr 19 10:06 /share/AI/LLM/unsloth/GLM-4.7-Flash-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 18G Apr 19 10:04 /share/AI/LLM/unsloth/gemma-4-31B-it-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 18G Apr 19 10:02 /share/AI/LLM/unsloth/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 17G Apr 13 16:13 /share/AI/LLM/HauhauCS/GLM-4.7-Flash-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 5.0G Apr 13 16:02 /share/AI/LLM/HauhauCS/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 945M Apr 13 16:02 /share/AI/LLM/HauhauCS/mmproj-Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-f16.gguf
-rwxrw-r-- 1 wx wx 16G Apr 12 16:10 /share/AI/LLM/Jackrong/Jackrong_Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2-GGUF
-rwxrw-r-- 1 wx wx 16G Apr 12 16:00 /share/AI/LLM/HauhauCS/Qwen3.5-27B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 16G Apr 12 15:58 /share/AI/LLM/Jiunsong/supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 13G Apr 12 15:47 /share/AI/LLM/bartowski/Mistral-Small-22B-ArliAI-RPMax-v1.1-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 16G Apr 12 15:40 /share/AI/LLM/unsloth/Qwen3.5-27B-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 16G Apr 12 12:01 /share/AI/LLM/unsloth/gemma-4-26B-A4B-it-UD-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 4.8G Apr 12 11:18 /share/AI/LLM/capybarahermes-2.5-mistral-7b.Q5_K_M.gguf
-rwxrw-r-- 1 wx wx 4.8G Apr 12 10:56 /share/AI/LLM/bartowski/Mistral-7B-Instruct-v0.3-Q5_K_M.gguf
-rwxrw-r-- 1 wx wx 4.7G Apr 12 10:49 /share/AI/LLM/unsloth/Qwen3-8B-Q4_K_M.gguf
-rwxrw-r-- 1 wx wx 9.6G Apr 12 10:32 /share/AI/LLM/qwen/qwen2.5-coder-14b-instruct-q5_0.gguf- 启动大模型,示例如下,如果日志太多可开启关闭日志选项
--log-disable
llamasrv /share/AI/LLM/Jiunsong/supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf
...
llama_model_loader: - kv 0: general.architecture str = gemma4
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.sampling.top_k i32 = 64
llama_model_loader: - kv 3: general.sampling.top_p f32 = 0.950000
llama_model_loader: - kv 4: general.sampling.temp f32 = 1.000000
llama_model_loader: - kv 5: general.name str = supergemma4-26b-uncensored-fast-v2
...
llama_model_loader: - kv 48: general.file_type u32 = 15
llama_model_loader: - type f32: 392 tensors
llama_model_loader: - type q5_0: 32 tensors
llama_model_loader: - type q8_0: 28 tensors
llama_model_loader: - type q4_K: 192 tensors
llama_model_loader: - type q6_K: 14 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q4_K - Medium
print_info: file size = 15.63 GiB (5.32 BPW)
...
main: model loaded
main: server is listening on http://0.0.0.0:8080
main: starting the main loop...
srv update_slots: all slots are idle- 检查是否开启Flash Attention,检查启动日志中是否有如下输出
Flash Attention was auto, set to enabled运行后只是在后台监听服务,可使用OpenWEBUI等工具连接使用,后续文章中会详细说明OpenWEBUI的基本使用