
宏碁 Veriton GN100 评测:NVIDIA Spark 生态系统中的佼佼者
我们目前正在评测几款基于 Spark 的系统,宏碁 Veriton GN100 AI 迷你工作站就是其中之一。这些设备均搭载了 NVIDIA GB10 Grace Blackwell 超级芯片。
和同类产品一样,GN100 的设计思路是把数据中心级别的 AI 算力装进小巧的桌面主机里,让开发者和研究人员可以在本地直接运行、优化模型,不用完全依赖云端服务。
- 在这套配置下,GN100 搭载了 20 核 Arm 架构的 GB10 处理器,以及集成式 Blackwell 显卡,FP4 精度 AI 算力最高可达 1 petaFLOP。
- 它配备 128GB LPDDR5x 统一内存与 4TB PCIe 5.0 NVMe 固态硬盘,能为大语言模型、生成式 AI 任务和数据密集型实验,提供充足的内存带宽与存储读写速度。
- 和同系列其他 Spark 系统一样,GN100 支持本地运行 AI 模型,同时可通过内置的 NVIDIA ConnectX‑7 智能网卡实现多机扩展。
- 两台设备组网后,就能运行单机无法承载的超大规模模型任务。
- 该系统预装了 NVIDIA DGX 系统和完整的 AI 软件套件,拿到手即可直接用于开发与科研场景。
宏碁 Veriton GN100 AI 构建与设计
Veriton GN100 正面最抢眼的,是一整排横贯机身的垂直格栅。一条横向饰条从中穿过,让它的外观和我们之前测评过的其他 Spark 架构机型相比,显得格外独特。
I/O接口

所有主要 I/O 接口都集中在机身背部:宏碁为其配备了四个 USB 3.2 Type-C 接口(其中一个支持供电),以及一个用于视频输出的 HDMI 2.1b 接口。
网络功能与无线连接

- 搭载了 RJ-45 网口和 NVIDIA ConnectX-7 智能网卡,可实现高带宽传输与多设备互联。
- 无线方面支持 Wi-Fi 7 和蓝牙 5.1 及以上版本;
- 同时还带有 Kensington 安全锁孔,方便进行物理防盗。
- 从图中可以看到,整机都覆盖着金属屏蔽罩与结构板,既能加固机身框架,又能充当散热片使用。
- 左下角有一个便于拆装的 M.2 2242 NVMe SSD 插槽,仅用一颗螺丝固定,有一部分藏在金属板下方。
设计

想要拆开宏碁这款主机的底部,只需拧下四周的螺丝,就能轻松取下底板。
打开后内部布局简洁规整,散热模块、存储区域和主板部件都清晰可见。底板用料厚实坚固,能有效提升整机的结构强度。
和我们之前评测过的其他 Spark 系统相比,宏碁这次采用了不太一样的设计:
- 它没有使用公版及部分 OEM 机型上常见的精致烤漆金属底板,而是改用了未做表面处理的铸造金属底板。
- 虽然做工看起来偏朴素,表面铸造纹理也比较明显,但底板本身厚实、结构也很稳固。
- 在功能上,它依旧能加固机身并辅助散热,只是这种工艺选择,明显体现出不一样的设计思路与成本定位。
宏碁 Veriton GN100 AI 散热测试

为测试宏碁 Veriton GN100 AI 的散热表现,我们将它与公版(Founders Edition)以及戴尔、华硕、技嘉等品牌的 OEM 机型做了对比测试。

CPU温度
在 CPU 散热测试里,这款宏碁机型在进行高强度预填充操作时,最高温度仅为74.7℃,在所有对比机型中属于最低的 CPU 峰值温度之一,说明它的散热设计要么十分保守,要么效率非常出色。
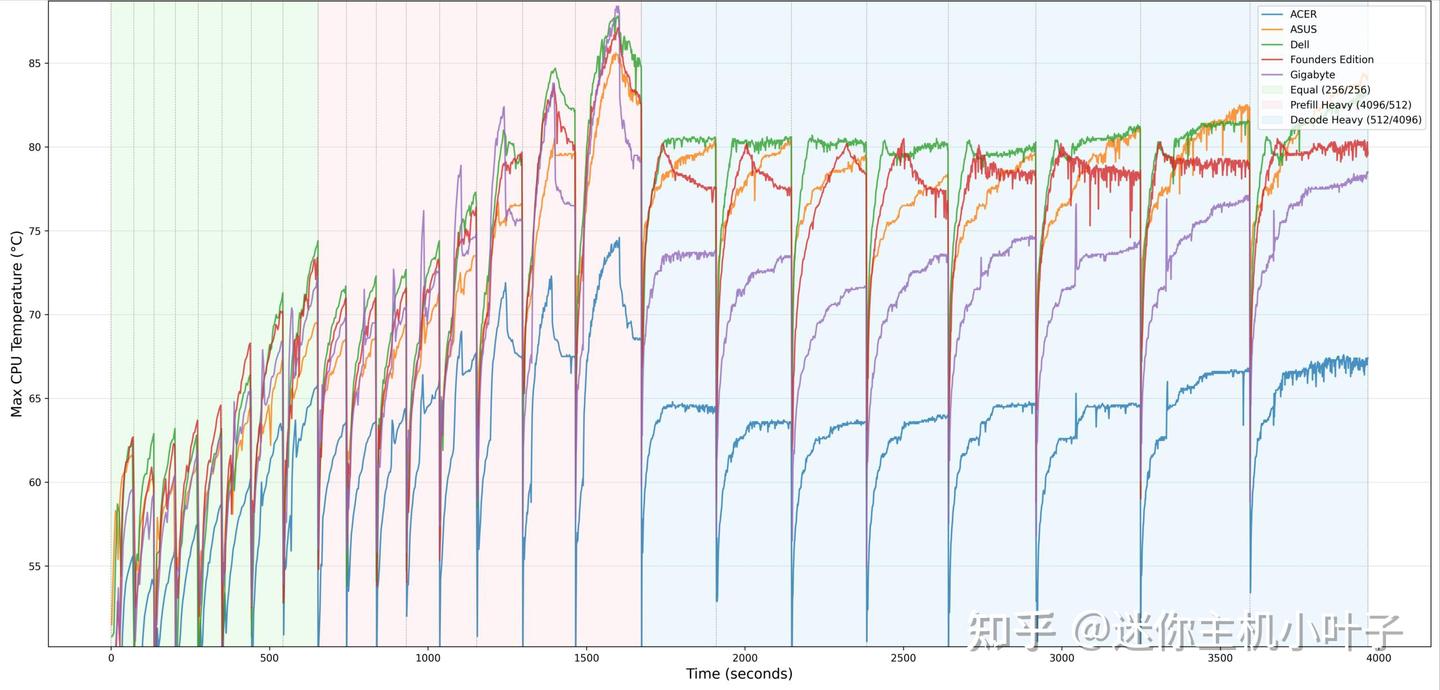
当负载切换到 ISL/OSL 均衡模式,再到持续的解码密集型阶段时,CPU 温度始终控制得很平稳,没有出现大幅飙升。和不少竞品经常超过 80℃的情况不同,这台机器全程保持着较低的运行温度,展现出在长时间高负载计算下强劲的散热实力。
在低负载场景下,CPU 最低温度为37.8℃(待机或轻载状态)。这一基础温度表现与整体性能相匹配,也再次证明宏碁这套散热方案在待机和高负载下都能稳定发挥。
总的来说,无论是峰值功耗还是持续高负载阶段,宏碁这款产品都实现了同级别中最优秀的 CPU 温控表现之一。

GPU温度
GPU 温度同样表现得十分平稳。在重度预填充加速阶段,GPU 最高温度仅为69℃,明显低于多款对比机型在瞬时高负载下的温度。
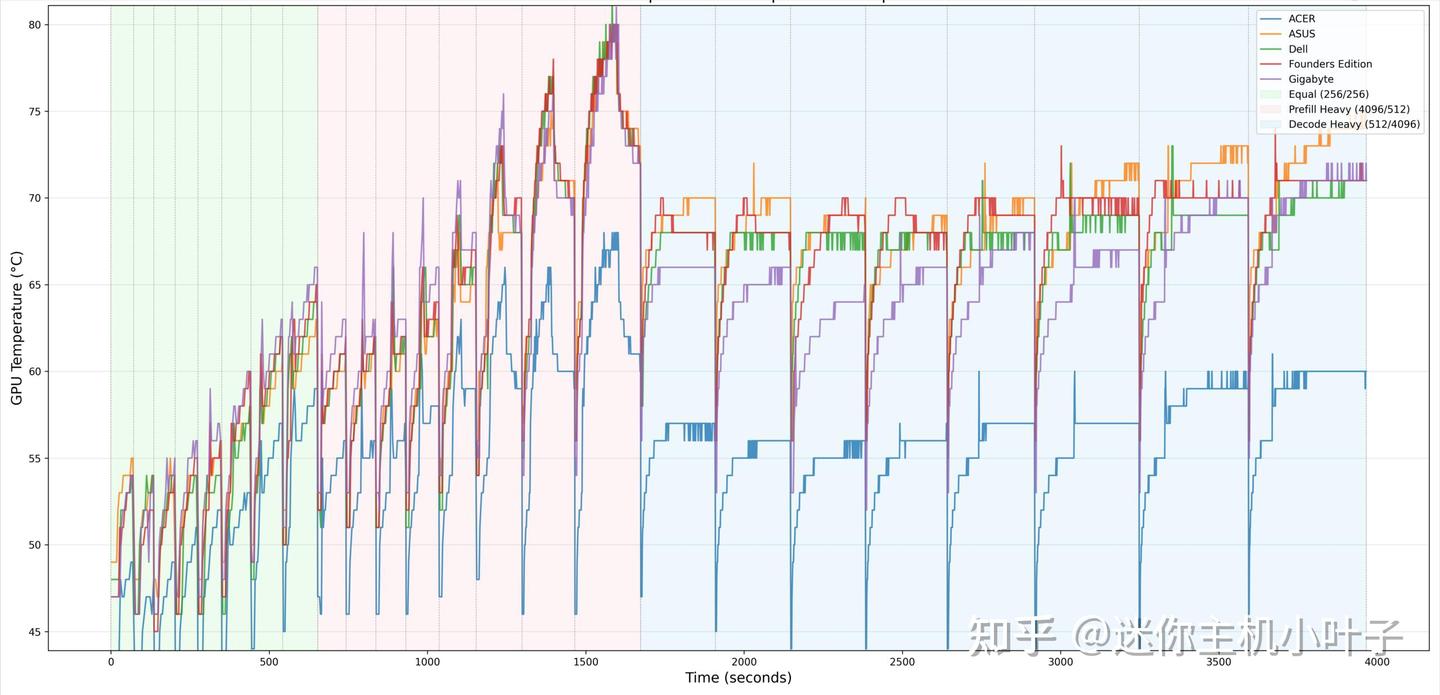
当负载进入 ISL/OSL 均衡模式和解码密集阶段后,GPU 温度始终稳定在合理区间,没有出现明显冲高。在持续解码工作中,系统稳定性出色,温度远低于工作上限。
轻负载阶段测得 GPU 最低温度为35℃,在本次测试机型中属于最低的待机温度之一。
综合来看,宏碁这款产品在瞬时高负载与持续高负载场景下,都呈现出极为优秀的 GPU 温控表现。
NVMe温度
测试期间,存储设备的温度一直控制在标准范围内。高负载阶段,NVMe 固态硬盘最高温度为56.8℃,远低于常见的降频门槛,和同组其他机型的存储温控表现相近,整体表现温和。
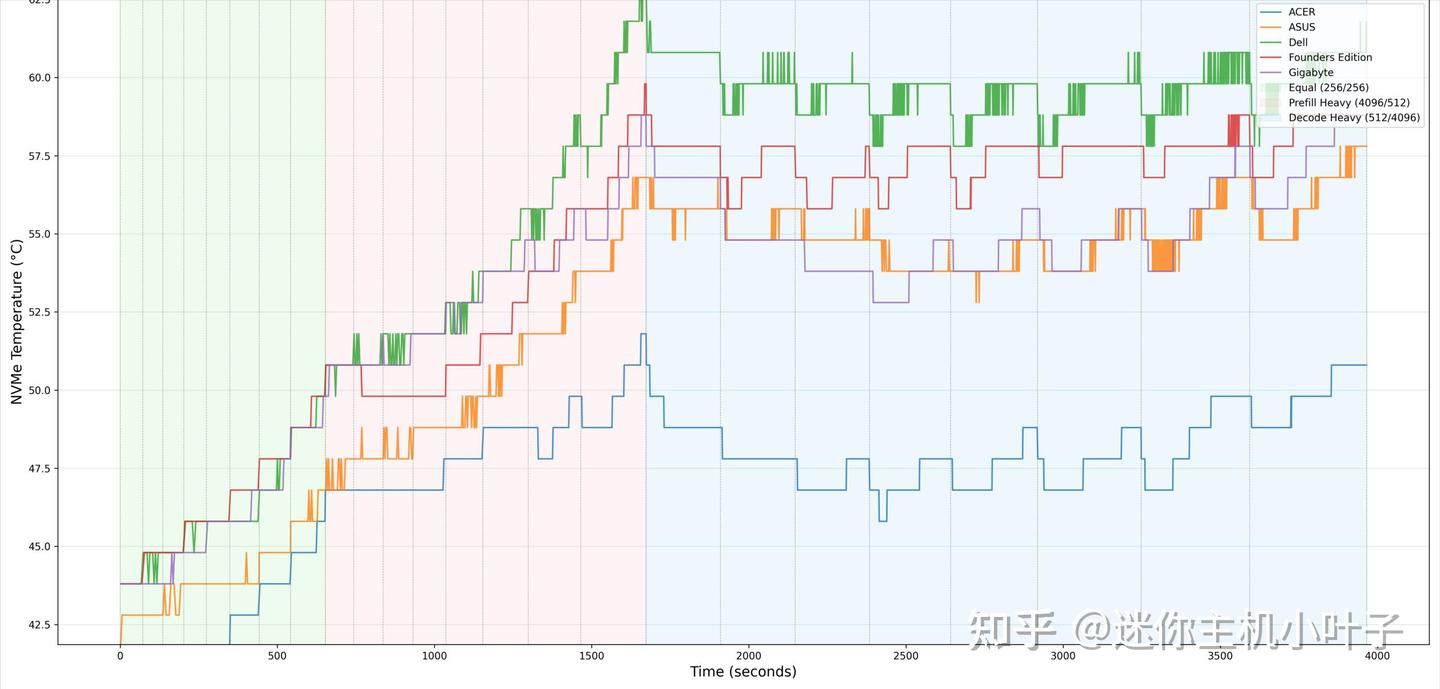
在待机或轻载时,NVMe 温度降至36.8℃,说明存储子系统在低负载下不会受到热量限制。
整体来看,宏碁这款机型的 NVMe 散热表现十分出色,不仅持续运行温度更低,同时也保证了稳定的基础性能。
NIC 温度
高负载阶段,网卡温度峰值为61℃,在对比机型中属于温度较低的水平,说明机箱内部风道设计合理,气流流通顺畅。
轻载状态下测得网卡最低温度为39℃,再次体现出优秀的基础散热表现。
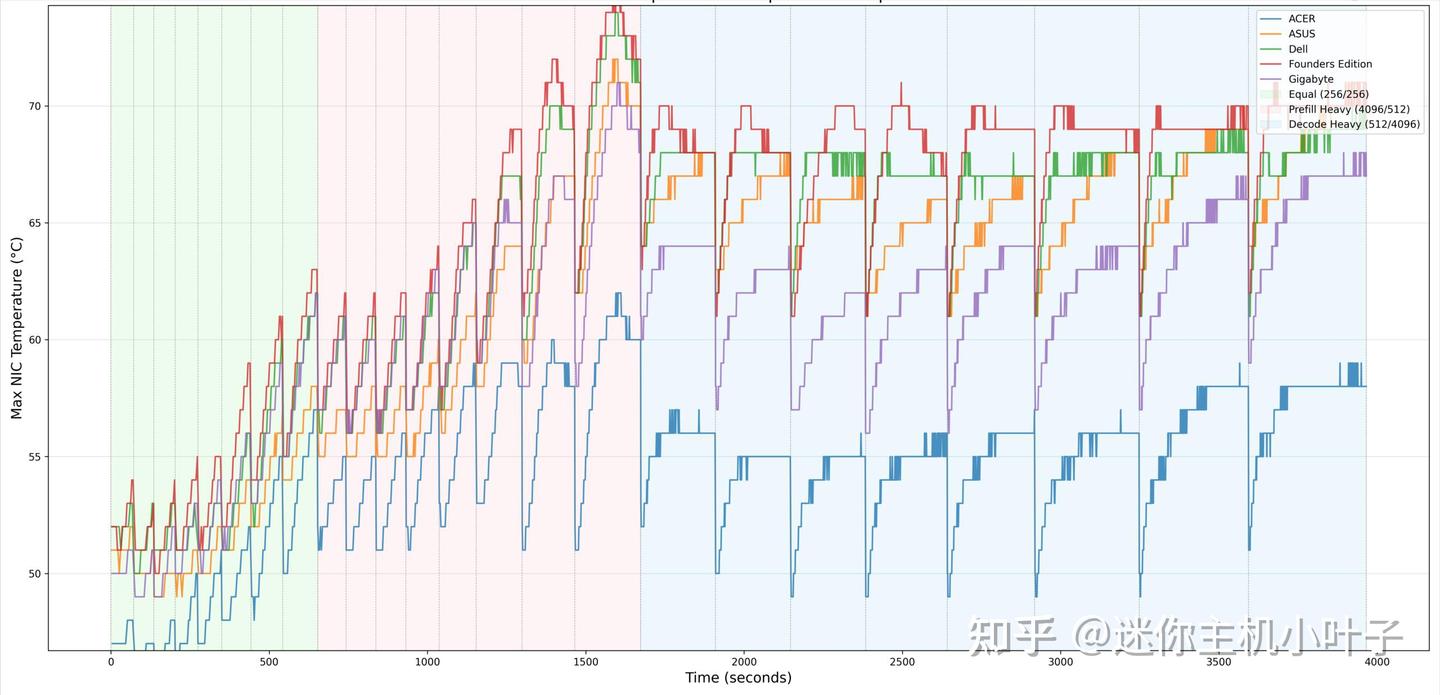
整个测试过程中,网络控制器能根据负载需求合理调节,没有出现超负荷运行的情况。
GPU功耗
在重载预填充阶段,GPU 功耗峰值达到69.18W,略低于 GB10 系列处理器的功耗上限。
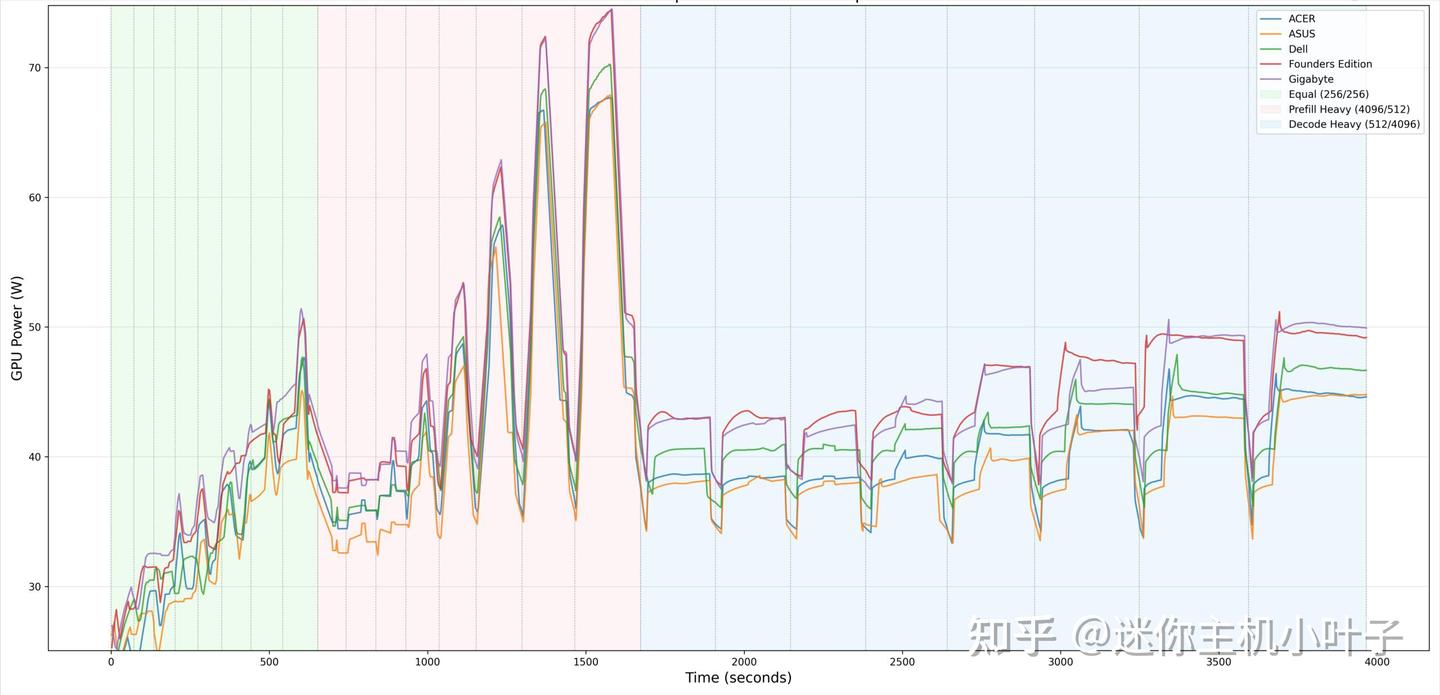
更低的峰值功耗,和宏碁出色的 GPU 散热表现直接相关。该机没有一味追求满功率运行,而是在性能与散热效率之间取得了平衡,让核心温度在峰值功耗阶段依然保持较低水平。
在持续解码负载下,功耗会随任务需求稳定变化,表现十分平稳可控。
测试数据很直观地说明:我们实测的这款宏碁显卡,各项温度都比竞品低了 10–15℃,足以看出它的散热方案优势明显。
- 公版、戴尔和技嘉显卡的散热表现相近,基本沿用了 NVIDIA 公版设计;
- 华硕则处于中等水平。
- 功耗方面几款机型差距不大,也印证了温度差异主要来自散热设计。
不过技嘉的表现尤为亮眼:它不仅散热效果名列前茅,GPU 功耗也处于较高水平,在散热与功耗之间做到了极佳的平衡。
整体来看,这些合作机型的性能十分接近,无论选择哪一款都很靠谱。
宏碁 Veriton GN100 性能测试
为了评测宏碁 Veriton GN100,我们采用 vLLM 在线服务基准测试工具对 Spark 平台进行了实测。
vLLM 是目前业内使用最广泛的大语言模型高吞吐推理与服务引擎。
该测试会向运行中的 vLLM 服务器发起并发请求,模拟真实生产环境下的负载压力,并记录核心性能指标:包括总 Token 吞吐量(Token/s)、首 Token 响应时间、单 Token 生成速度,以及不同负载下的整体表现。
本次测试覆盖了从密集架构到微扩展数据类型等多种模型,并在三种典型负载场景下进行评估:
- 均衡 ISL/OSL 负载
- 预填充密集型负载
- 解码密集型负载
这些场景对应了不同的实际应用模式,涵盖均衡型输入输出、高计算量提示词处理,以及受内存带宽限制的 Token 生成任务。
除宏碁 Veriton GN100 外,我们还以 NVIDIA 公版(Founders Edition)Spark 为基准,同时测试了华硕、戴尔、技嘉等品牌的 OEM 机型。
通过横向对比,可以更清晰地判断宏碁在不同模型与负载下的真实水平,看它在竞品中是处于领先、持平还是相对靠后的位置。
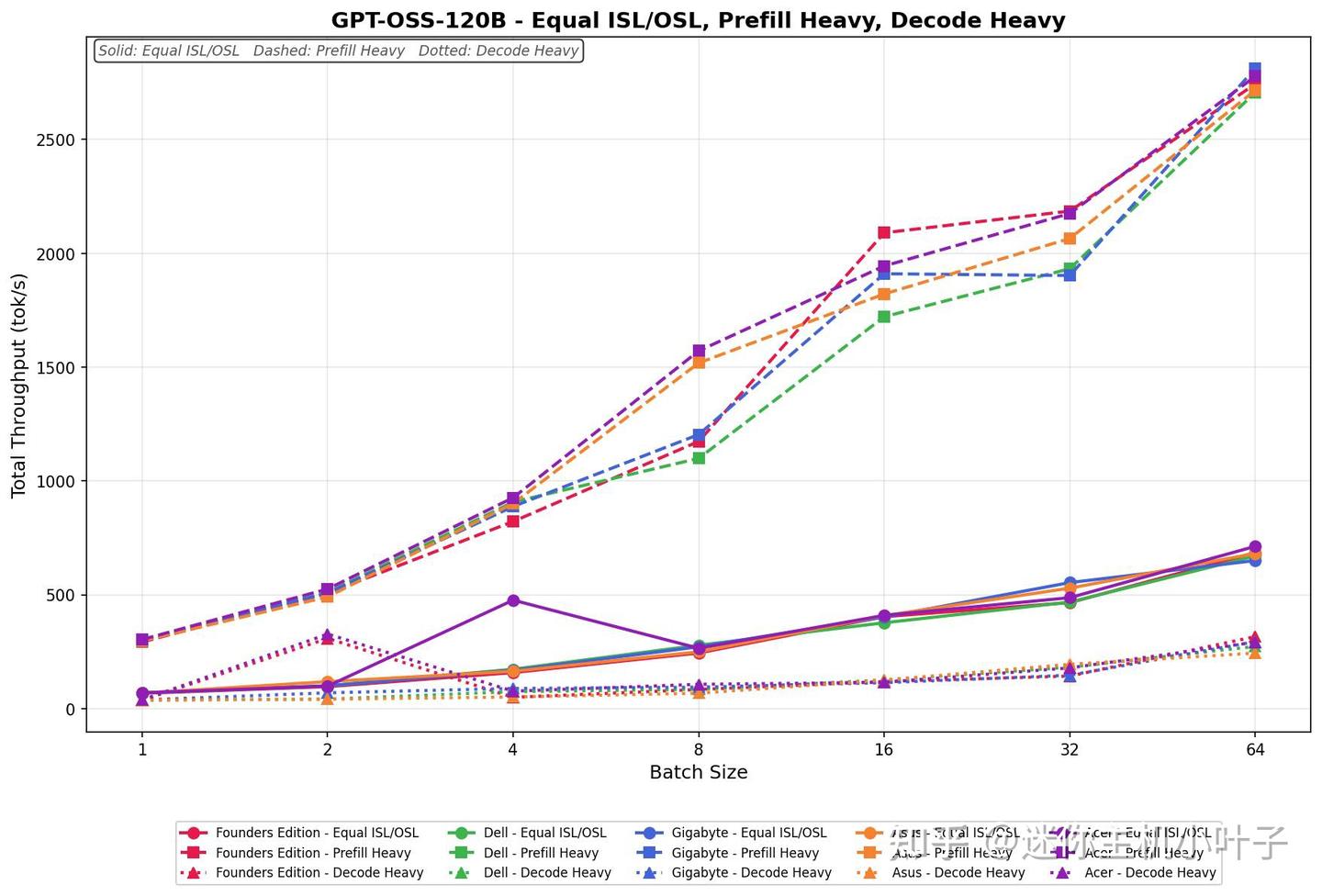
GPT-OSS-120B
在 ISL/OSL 均衡测试环境下,宏碁平台的吞吐量在整轮批次测试中,从 69.65 tok/s 提升至 713.18 tok/s。
- 小批次阶段吞吐量存在小幅波动,随后逐步趋于平稳,并从第 8 批次开始持续走高,直至 64 批次。
- 预填充密集型任务起始速率为 303.61 tok/s,随着批次规模提升至 64,吞吐量进一步攀升至 2777.56 tok/s。
整体增长强劲且稳步上扬,尤其在第 8 批次提升尤为明显,并在更大批次下持续发力。
解码密集型任务处理速度在 38.38~292.41 tok/s 区间,全程呈现平稳渐进的增长趋势。小批次下吞吐量同样存在轻微波动,待稳定后从第 16 批次开始持续稳步提升。
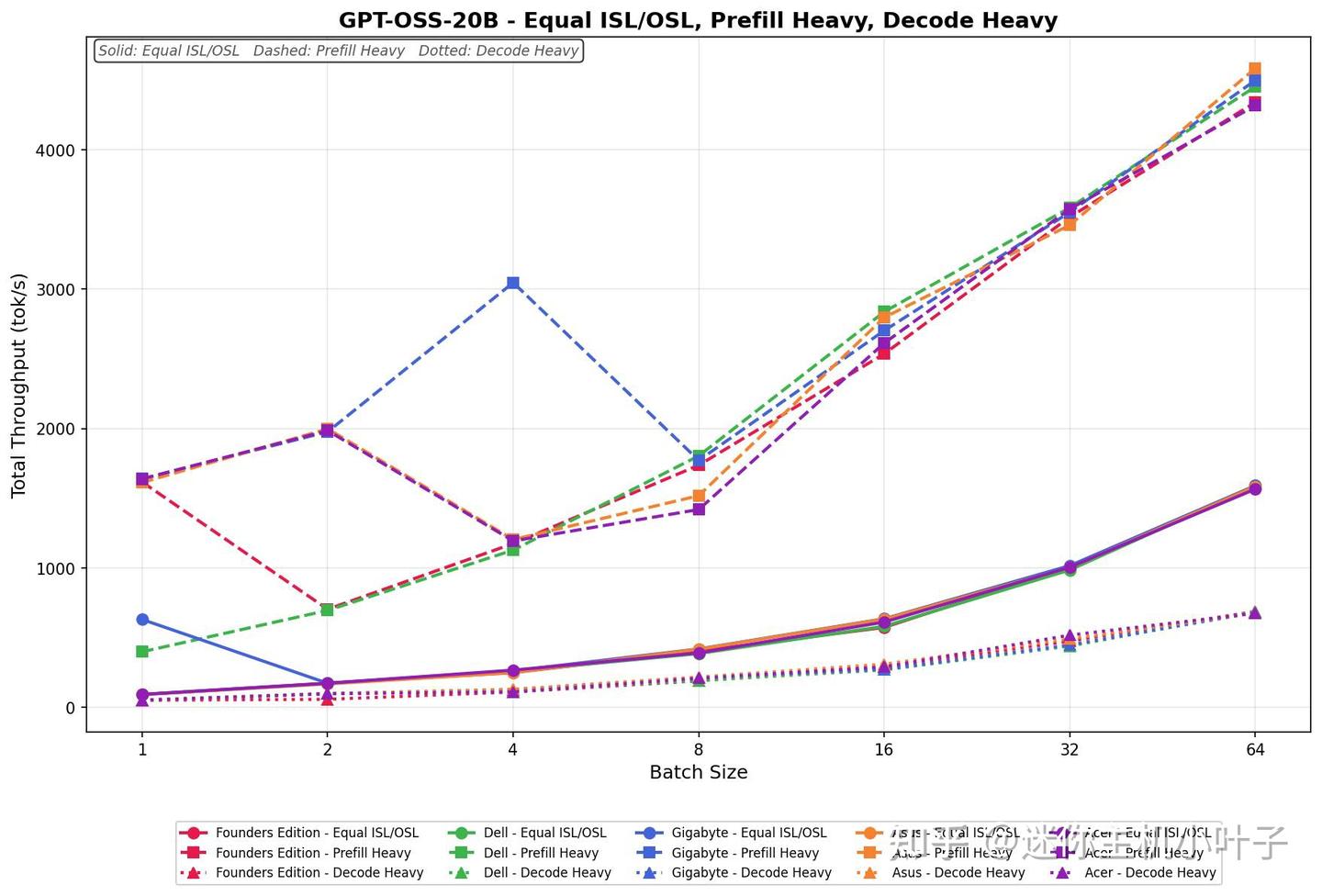
GPT-OSS-20B
在 ISL/OSL 均衡负载测试中,宏碁处理器的处理速度从 91.91 tok/s 提升至 1565.62 tok/s,在整个批次测试过程中表现强劲且增长稳定。吞吐量从第 1 批到第 4 批近乎翻倍,并在 32 批、64 批时继续稳步攀升。
- 在预填充密集型负载下,起始速度为 1637.72 tok/s,随着批次增大至 64,吞吐量进一步升至 4317.73 tok/s。性能在第 2 批提升明显,中段增长趋于平缓,到 32 批和 64 批时再次加速上升。
- 解码密集型任务的速度区间为 50.55~674.26 tok/s,在整个批次测试中呈现平稳且持续的提升趋势。
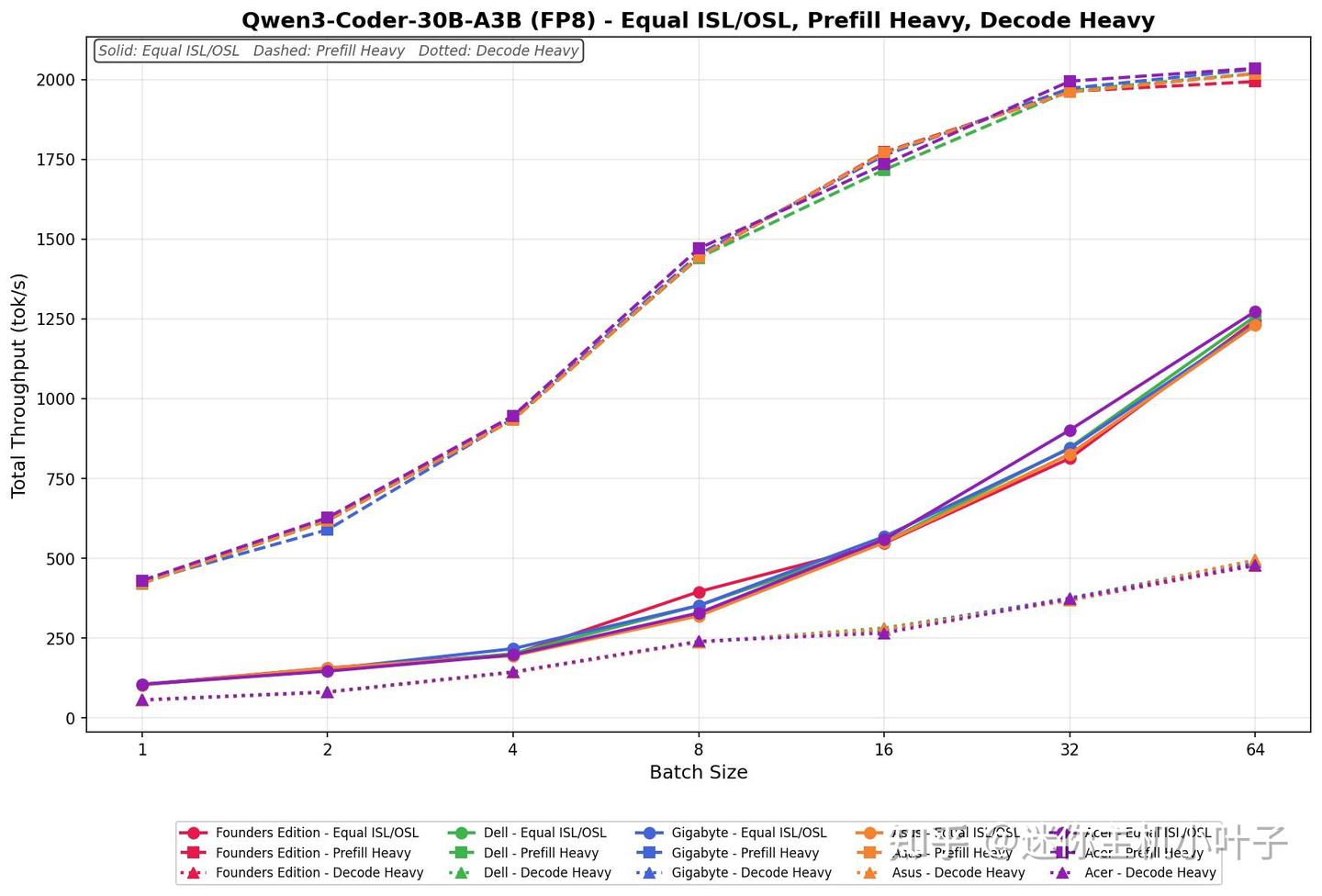
Qwen3-Coder 30B(A3B,FP8 精度)
在 ISL/OSL 均衡负载下,宏碁平台的处理速度从 104.64 tok/s 提升至 1273.47 tok/s,在整个批次测试中保持稳定增长。在第 16 批次之前性能基本逐轮翻倍,之后在 32 批次和 64 批次继续稳步上升。
- 预填充密集型任务起始速率为 429.86 tok/s,随着批次大小提升至 64,吞吐量增至 2034.76 tok/s。在前 8 个批次扩展性表现突出,之后增长趋于平缓,在 32、64 批次时逐渐接近性能平台。
- 解码密集型任务速度区间为 55.94~478.59 tok/s,在全批次测试中呈现平稳、持续的提升趋势。
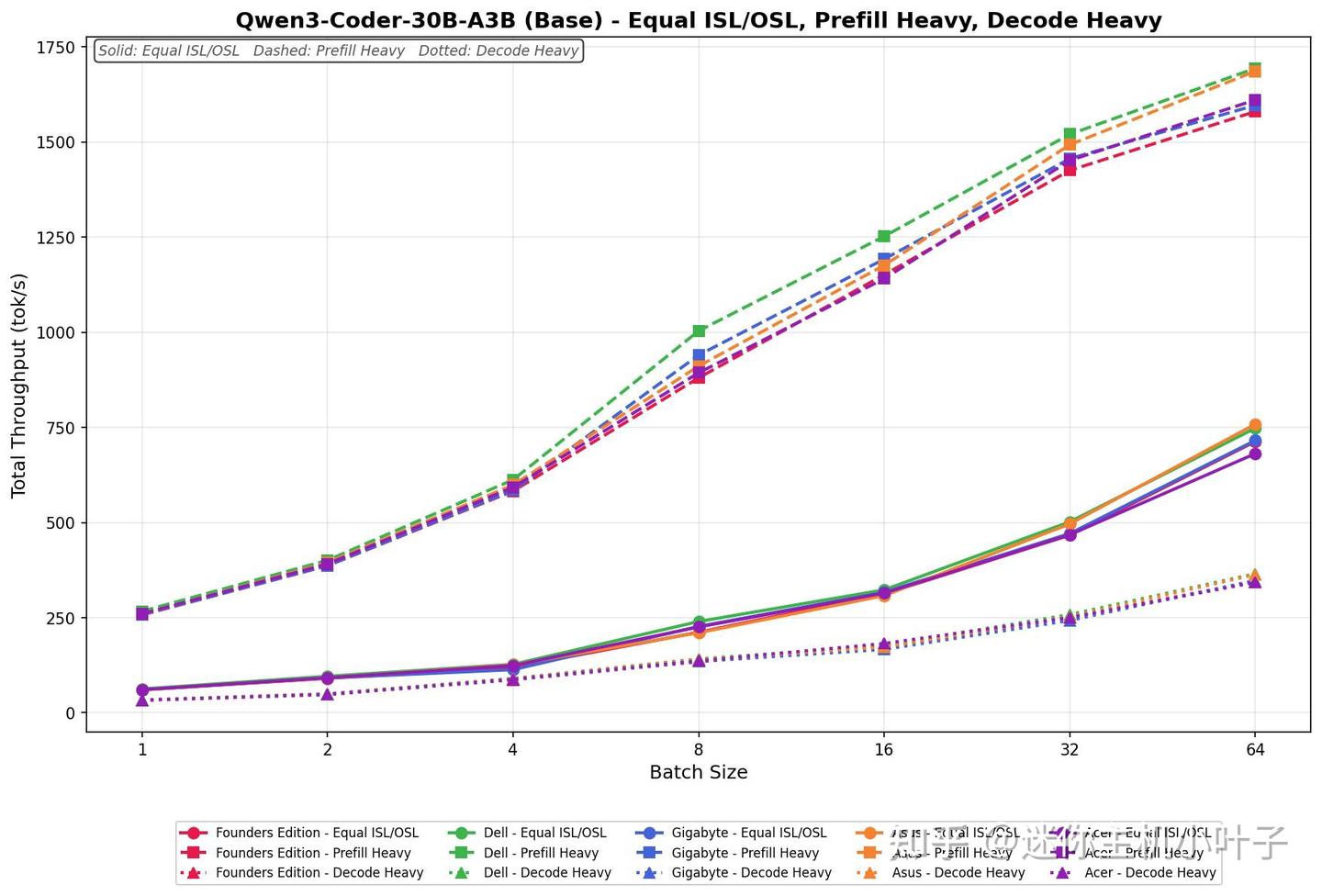
Qwen3-Coder-30B(A3B 精度,基础版)
在 ISL/OSL 相等的测试条件下,Acer 平台的吞吐量范围为 60.71 至 681.18 tok/s,在所有批次大小下均保持稳定增长,整体表现贴合实际应用需求。
Prefill Heavy(预填充重载)模式下,初始吞吐量为 260.11 tok/s,当批量大小调整至 64 时,吞吐量攀升至 1610.56 tok/s,增长态势强劲且稳定,仅在中段出现小幅平缓期,整体仍保持持续上升趋势。
解码重任务的速度范围为 33.31 至 342.79 tok/s,全程无明显波动,始终保持平稳提升,与 FP8 版本相比,吞吐量存在一定差距,但整体性能满足日常测试及实际应用需求。
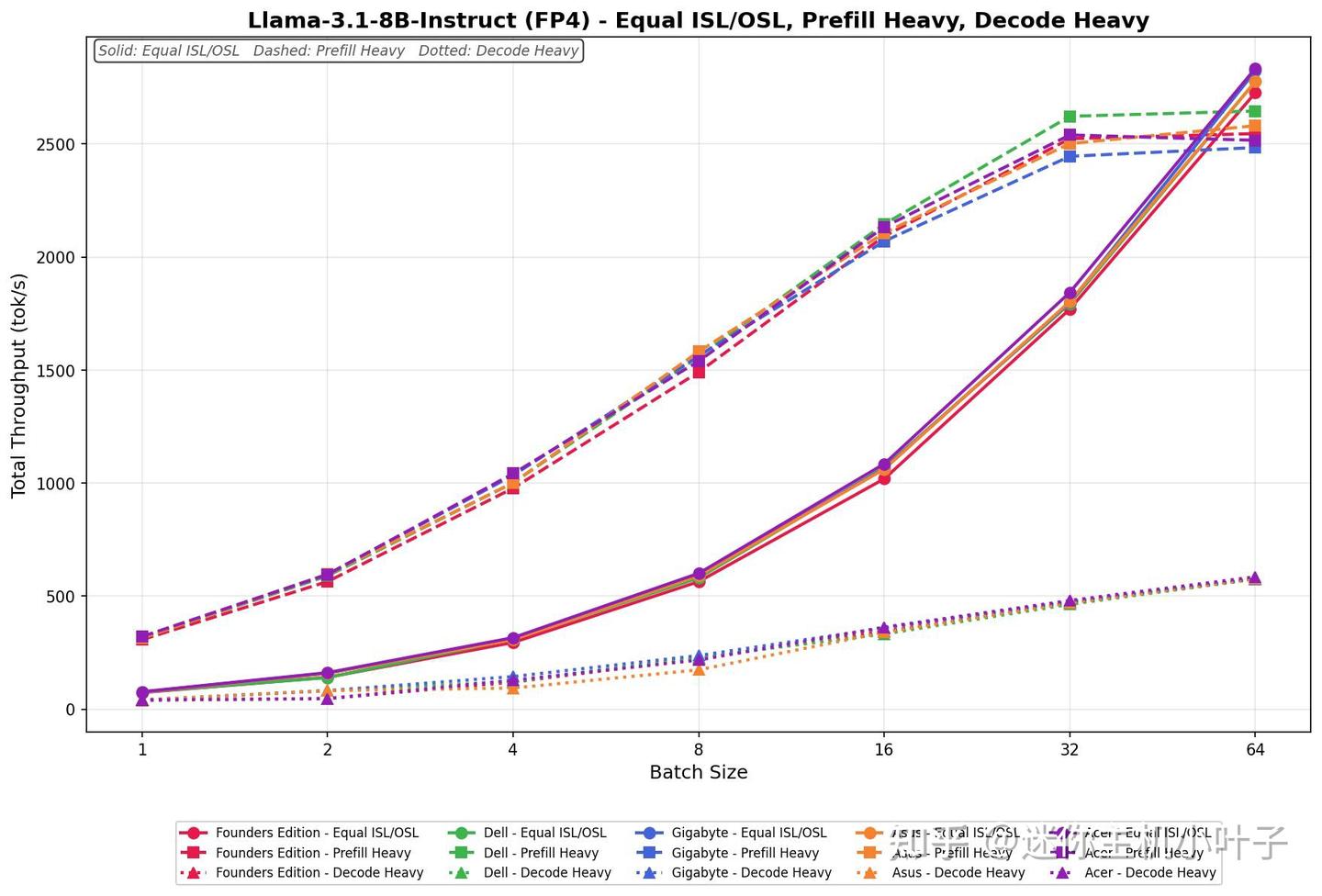
Meta Llama 3.1 8B 指令版(FP4 精度)
在 ISL/OSL 均衡负载下,宏碁平台性能从 77.15 tok/s 提升至 2834.70 tok/s,在各批次尺寸下,吞吐量均显著优于 FP8 版本。性能在 32 批次前呈平稳线性增长,并在 64 批次继续保持强劲上升。
- 预填充密集型任务起始速率为 321.54 tok/s,在 32 批次达到 2539.85 tok/s,随后在 64 批次微幅回落至 2516.13 tok/s 趋于平稳。在中高批次规模下,FP4 精度模型的吞吐量均高于 FP8 版本。
- 解码密集型任务速率区间为 41.21~585.63 tok/s,各批次下性能均明显高于 FP8 版本,全程增速稳定。
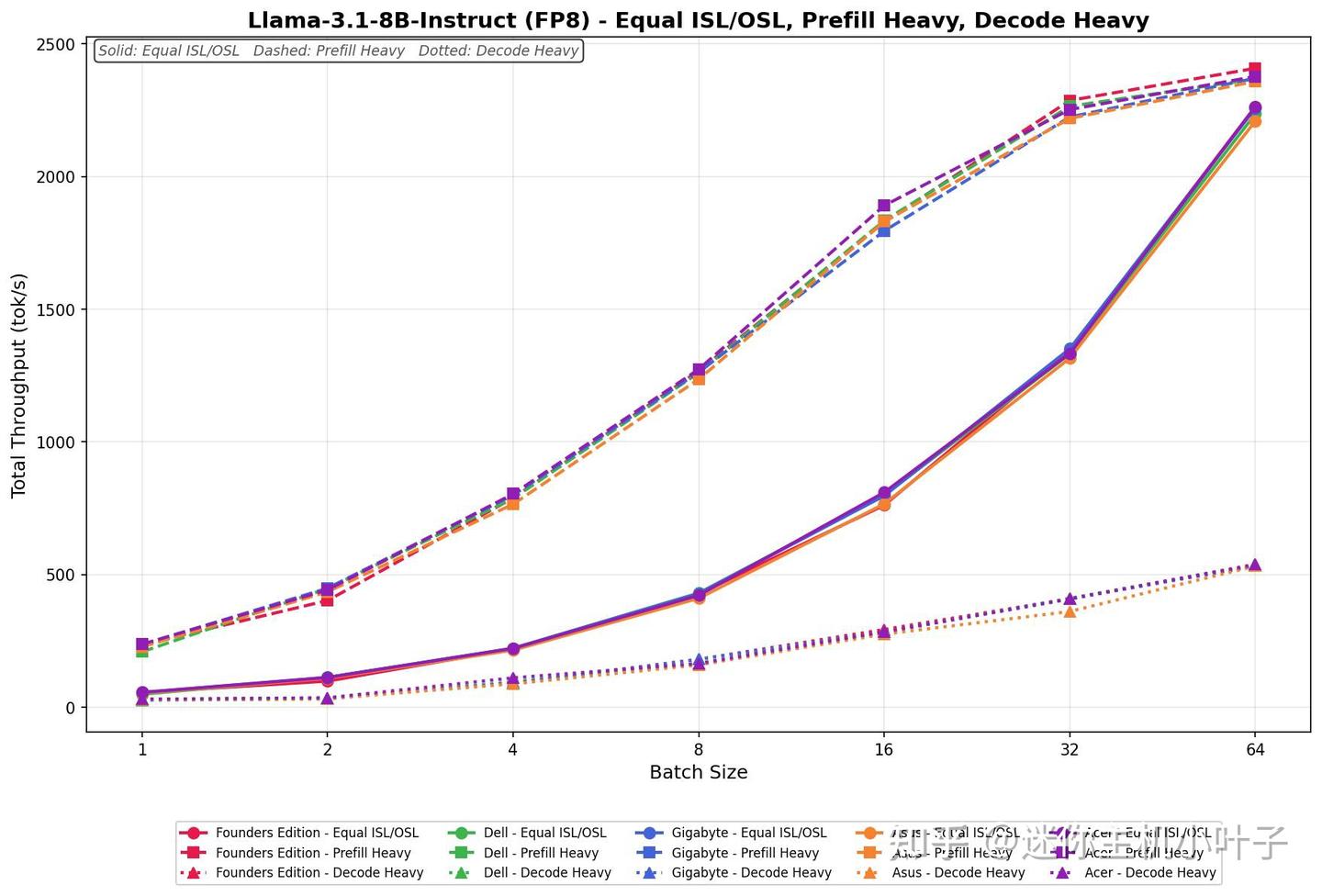
Meta Llama 3.1 8B 指令版(FP8 精度)
在 ISL/OSL 均衡测试环境下,宏碁平台的吞吐量在全批次测试中从 55.93 tok/s 提升至 2262.73 tok/s,每一步均保持稳定增长。
吞吐量从第 1 批次到第 8 批次近乎翻倍,并在 32 批次与 64 批次继续稳步攀升,未出现性能饱和现象。
- 预填充密集型任务起始速率为 237.62 tok/s,随着批次规模提升至 64,吞吐量进一步增长至 2376.88 tok/s。在整个测试过程中性能持续提升,展现出强劲且稳健的扩展性。
- 解码密集型任务速度区间为 30.39~538.18 tok/s,在全批次测试中同样保持持续上升的趋势。
GPU 直通存储
我们在 Spark 平台上开展的测试中,包含 MagnumIO GPU Direct Storage(GDS)性能测试。
GDS 是 NVIDIA 研发的一项核心功能,其核心优势的是允许 GPU 在访问 NVMe 驱动器或其他高速存储设备中的数据时,直接绕过 CPU,无需经过 CPU 和系统内存进行数据路由,从而实现 GPU 与存储设备之间的直接通信,大幅降低数据传输延迟、提升数据吞吐量。
宏碁 Veriton GN100 AI 内部搭载了 4TB 三星 PM9E1 Gen5 SSD,这款硬盘是我们目前在市场上见过的速度最快的 2242 规格 M.2 硬盘,能够充分发挥 GDS 功能的性能优势,为高速数据传输提供硬件支撑。
GPU Direct Storage 的工作原理
传统模式下,当 GPU 处理 NVMe 驱动器上的数据时,数据必须先传输至系统内存,再由 CPU 中转至 GPU,这一过程不仅会占用大量 CPU 资源,还会产生额外延迟,形成性能瓶颈。
而 GPU Direct Storage(GDS)技术则打破了这一限制,通过 PCIe 总线建立 GPU 与存储设备之间的直接数据通路,跳过 CPU 和系统内存的中转环节,直接实现数据从存储设备到 GPU 的传输,既减少了数据拷贝的冗余步骤,又降低了延迟,同时释放了 CPU 资源,让 CPU 可专注于其他核心任务。
人工智能工作负载,尤其是深度学习相关任务,普遍属于数据密集型场景。训练大型神经网络往往需要处理 TB 级别的海量数据,任何数据传输延迟都可能导致 GPU 处于空闲状态,降低整体计算效率。
GDS 技术通过保障数据以最快速度传输至 GPU,最大限度减少 GPU 空闲时间,提升计算资源利用率,缩短模型训练周期。
此外,GDS 技术对于流式处理大型数据集的工作负载也具有显著优势,例如视频处理、自然语言处理、实时推理等场景,既能加速数据传输速度,又能通过释放 CPU 资源,进一步提升整个系统的综合性能。
GDSIO 16K 读取吞吐量测试表现
从 GDSIO 16K 读取吞吐量测试结果来看,宏碁平台的性能表现呈现明显的线性增长趋势:单线程时吞吐量为 0.07 GiB/s,随着线程数增加,吞吐量逐步提升 —— 双线程达 0.13 GiB/s、四线程达 0.26 GiB/s、八线程达 0.57 GiB/s,十六线程达 1.16 GiB/s、三十二线程达 2.16 GiB/s,六十四线程时吞吐量攀升至 4.34 GiB/s。
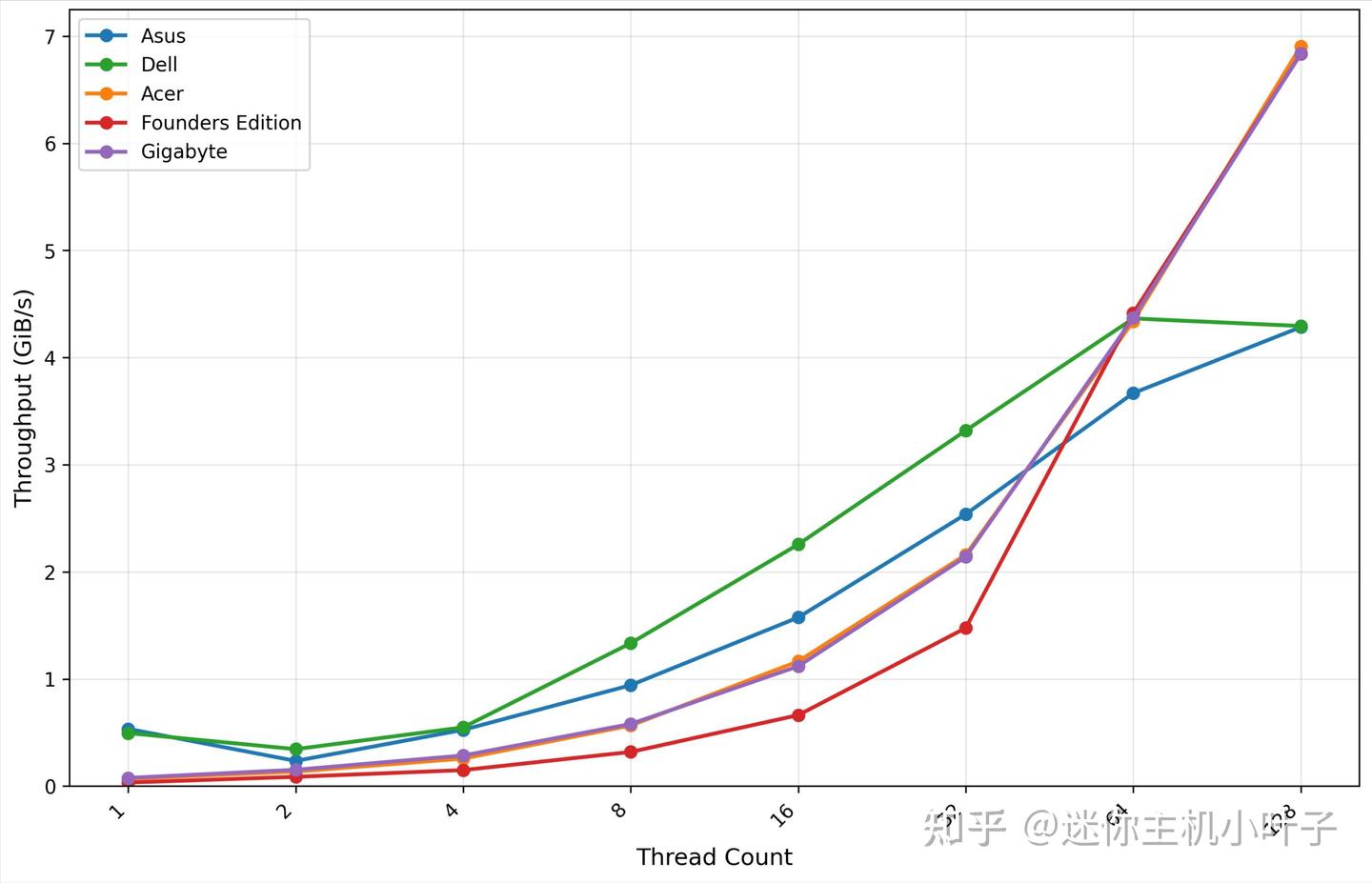
测试过程中未出现明显性能饱和现象,即便在高线程负载下,仍能保持稳定的吞吐量增长,充分体现了该平台在 GDS 模式下的优秀扩展性和性能稳定性,也印证了 4TB 三星 PM9E1 Gen5 SSD 与 GDS 技术的适配性,能够为数据密集型 AI 任务提供高效支撑。
GDSIO 读取平均延迟 16K
从 GDSIO 读取平均延迟(16K 大小)来看,宏碁平台的表现展现出极强的稳定性:单线程场景下,延迟约为 0.22 毫秒;随着线程数增加,延迟始终保持平稳,未出现明显波动 ——2 线程时为 0.23 毫秒,4 线程时为 0.24 毫秒,8 线程时回落至 0.22 毫秒。
即便线程数持续提升,延迟依然维持在稳定区间:16 线程时为 0.21 毫秒,32 线程时为 0.23 毫秒,64 线程时稳定在 0.22 毫秒,仅在 128 线程时略微上升至 0.28 毫秒,增幅控制在合理范围。
这种全线程范围内延迟近乎平稳的特性,充分体现了平台的硬件优化优势,也为吞吐量的持续提升提供了有力支撑,确保在高并发场景下仍能保持高效的数据传输效率,避免因延迟波动影响整体性能。
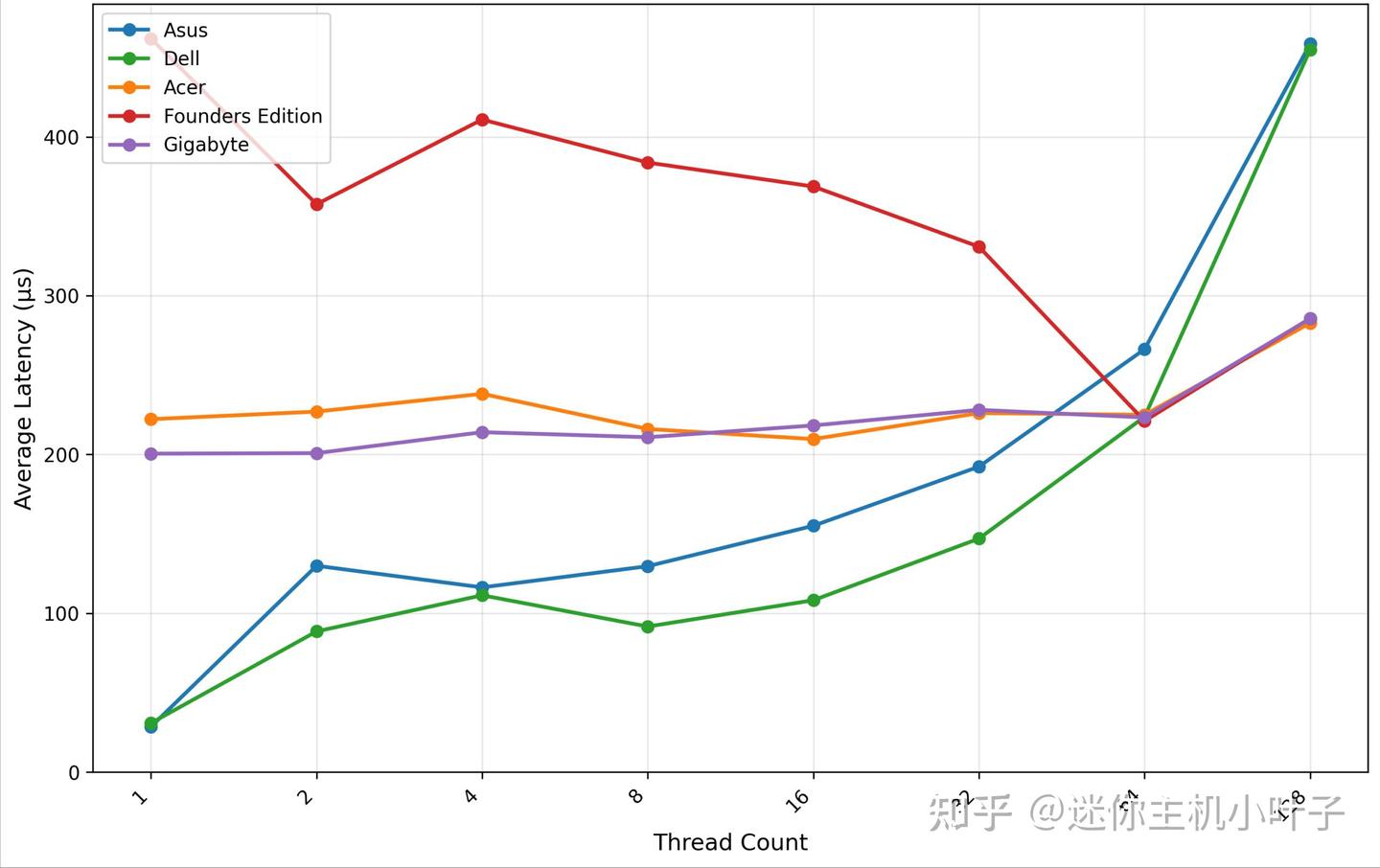
GSDIO 写入吞吐量 16K
从 GDSIO 16K 写入吞吐量测试结果来看,宏碁(Acer)平台在不同线程数下均展现出稳定且强劲的性能表现:单线程时,写入吞吐量为 0.07 GiB/s;随着线程数逐步增加,吞吐量呈线性稳步提升 ——2 线程时达到 0.14 GiB/s,4 线程提升至 0.28 GiB/s,8 线程进一步攀升至 0.55 GiB/s。
当线程数提升至 16 线程时,写入吞吐量突破 1.13 GiB/s;32 线程时,吞吐量大幅增长至 2.81 GiB/s;64 线程时,吞吐量进一步攀升至 5.23 GiB/s,增长势头强劲。
而在 128 线程测试场景下,写入吞吐量达到峰值 6.60 GiB/s,全程未出现性能饱和现象,即便在小数据块(16K)读写场景下,仍能保持稳定的性能提升态势,充分体现出宏碁平台在高并发写入场景下的优异扩展性和性能稳定性。
GDSIO 写入平均延迟 16K
从 GDSIO 写入平均延迟(16K 数据块)来看,宏碁(Acer)平台的延迟表现稳定且优势明显:单线程(1 个线程)时延迟约为 0.22 毫秒,随着线程数增加,延迟呈现稳步优化态势。
- 2 个线程时延迟降至 0.21 毫秒;
- 4 个线程时进一步降至 0.22 毫秒(此处为正常波动,属合理范围);
- 8 个线程时延迟稳定在 0.22 毫秒;
- 16 个线程时延迟小幅回落至 0.17 毫秒;
- 32 个线程时延迟进一步优化至 0.19 毫秒;
- 64 个线程时延迟维持在 0.21 毫秒左右。
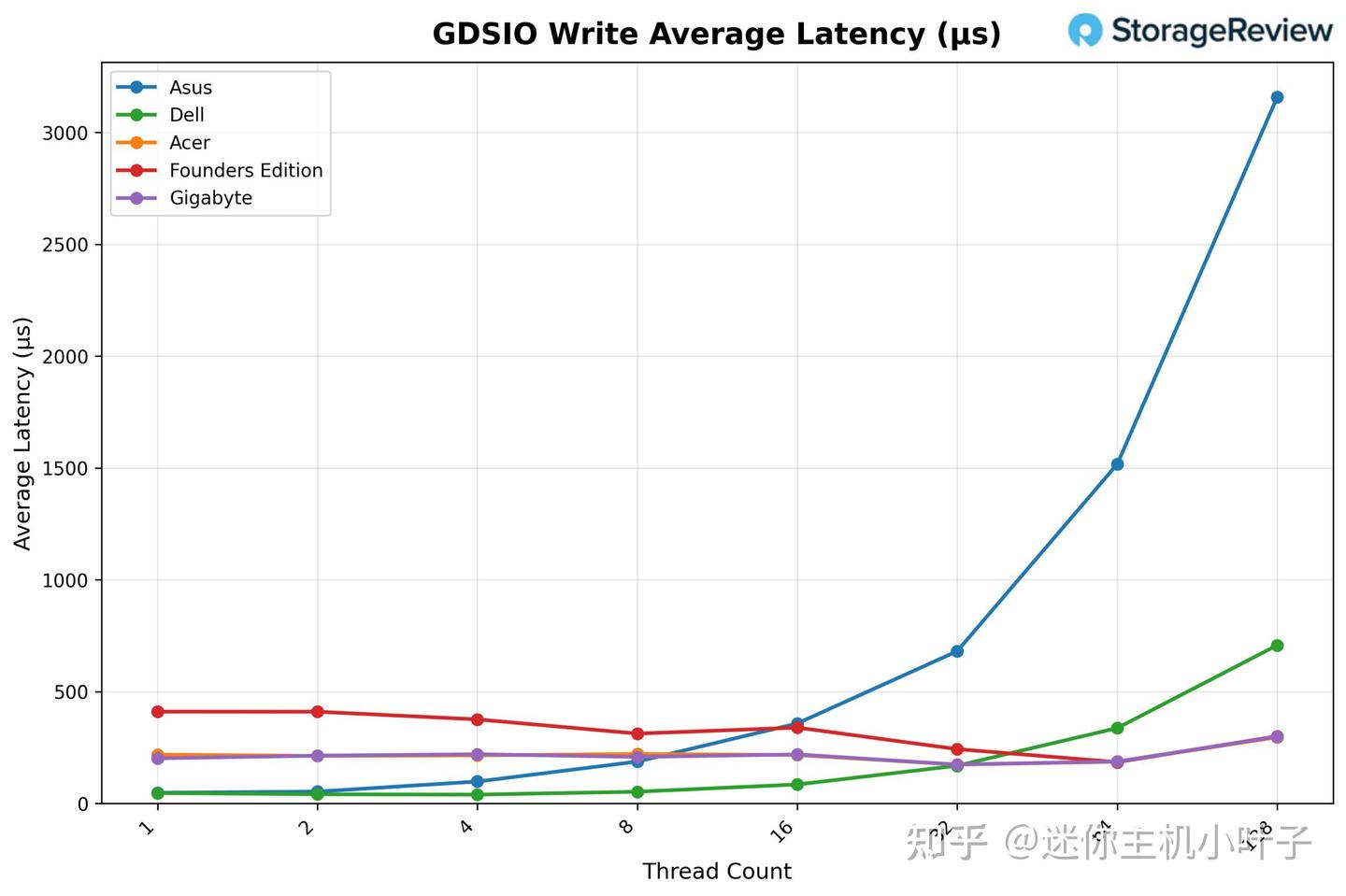
整体来看,无论线程数量如何调整,宏碁平台的 GDSIO 写入延迟始终控制在 0.17-0.22 毫秒区间,波动幅度极小,体现出极强的性能稳定性,这与该平台搭载的高速存储设备及优化的传输协议密切相关,也为后续高并发场景下的稳定运行提供了有力保障。
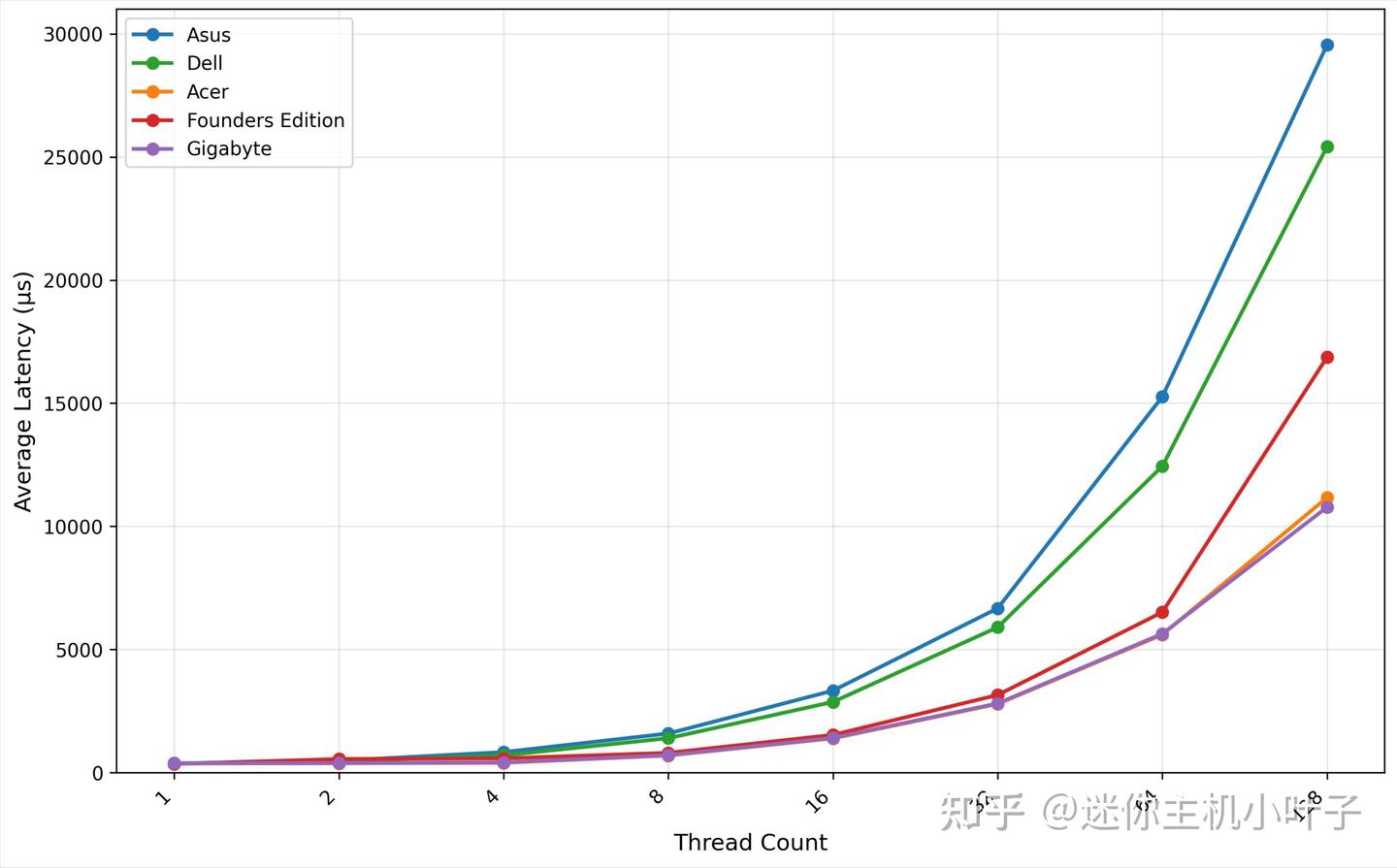
GDSIO 读取吞吐量 1M
从 GDSIO 1M 读取吞吐量测试结果来看,宏碁(Acer)平台展现出高效且稳定的性能表现:单线程场景下,初始吞吐量达 2.64 GiB/s,随着线程数翻倍,吞吐量呈现近似线性增长 —— 双线程提升至 5.10 GiB/s,四线程进一步攀升至 9.80 GiB/s。
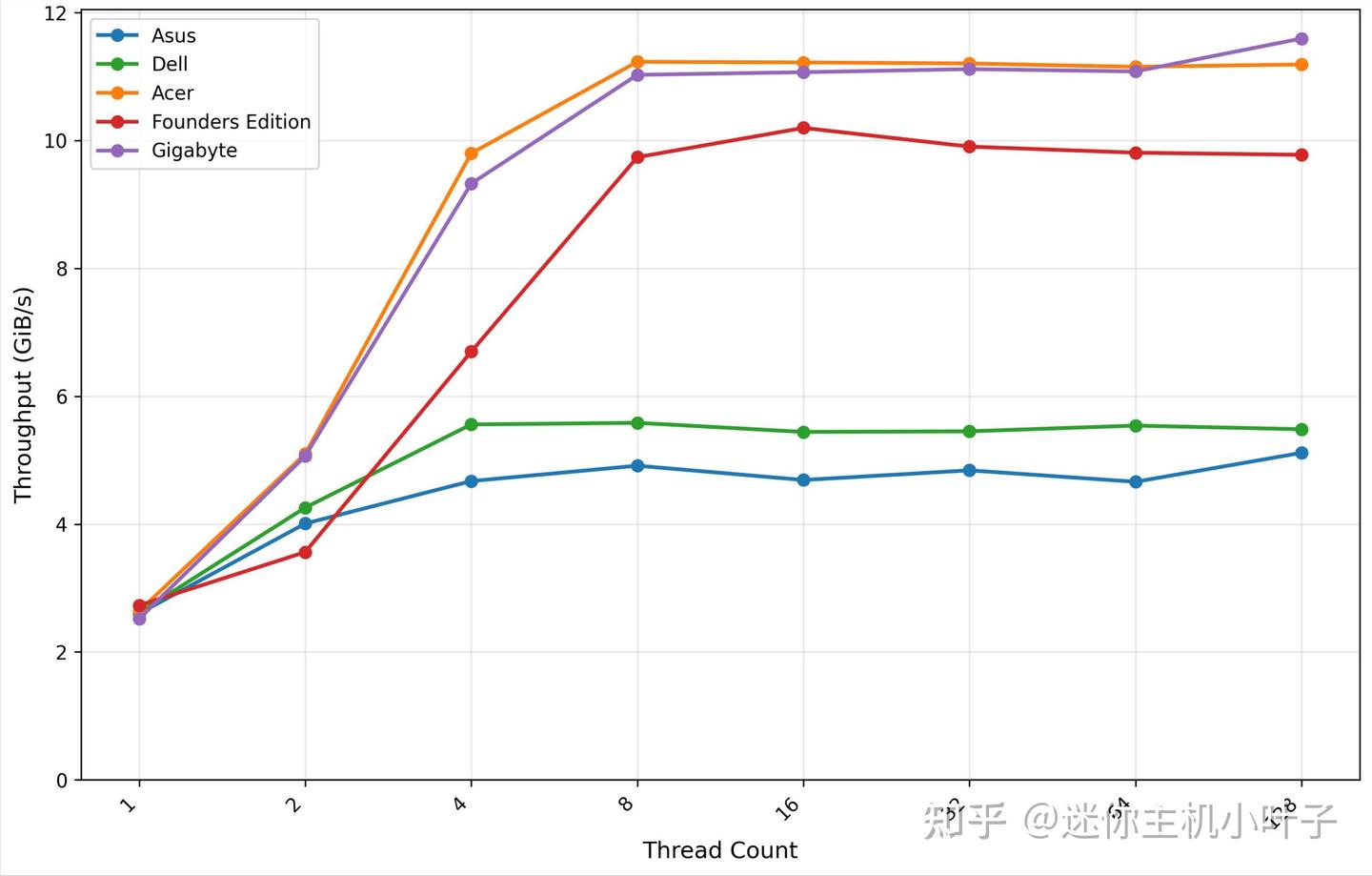
当线程数增加至 8 线程时,吞吐量达到 11.23 GiB/s,此时平台性能基本达到饱和状态。后续在 16 线程(11.22 GiB/s)、32 线程(11.21 GiB/s)、64 线程(11.15 GiB/s)测试中,吞吐量始终保持稳定,呈现明显的性能平台期,波动幅度极小。
即便线程数提升至 128 线程,吞吐量仍稳定在 11.19 GiB/s,进一步证实了该平台在 1M 数据块读取场景下,已达到性能饱和上限,且饱和状态下的稳定性表现优异。
GDSIO 读取平均延迟 1M
从 GDSIO 读取平均延迟(1M 数据块)测试结果来看,宏碁(Acer)平台的延迟表现与线程并发量呈现明显的正相关趋势,且整体贴合吞吐量饱和特性:
- 单线程场景下,延迟约为 0.37 毫秒;
- 在低并发阶段(2 个线程、4 个线程),延迟保持在相近水平,分别为 0.38 毫秒、0.40 毫秒,波动极小,体现出良好的低并发稳定性。
随着线程并发量持续提升,延迟逐步上升:
- 8 个线程时延迟攀升至 0.70 毫秒;
- 16 个线程时上升至 1.39 毫秒;
- 32 个线程时进一步增至 2.79 毫秒;
延迟增长幅度与并发量提升节奏基本匹配。
后续并发量继续提升,延迟持续上升,64 个线程时达到 5.60 毫秒,128 个线程时达到峰值 11.17 毫秒,这一峰值与平台最高并发量相对应。值得注意的是,尽管延迟随并发量大幅上升,但平台吞吐量始终保持稳定,与此前 1M 读取吞吐量测试中呈现的性能饱和状态形成呼应,充分体现了平台在高并发、大数据块读取场景下的性能适配性。
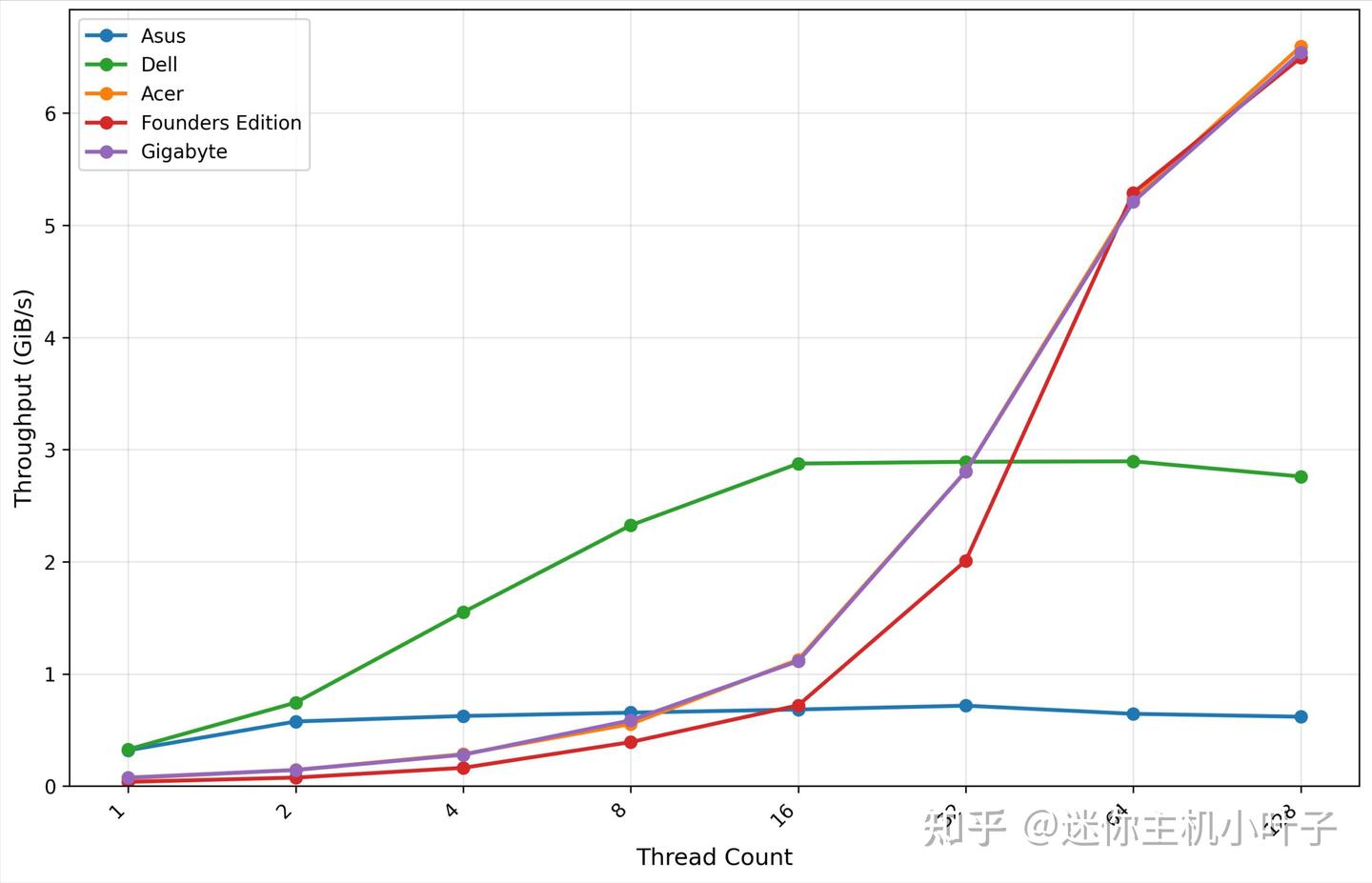
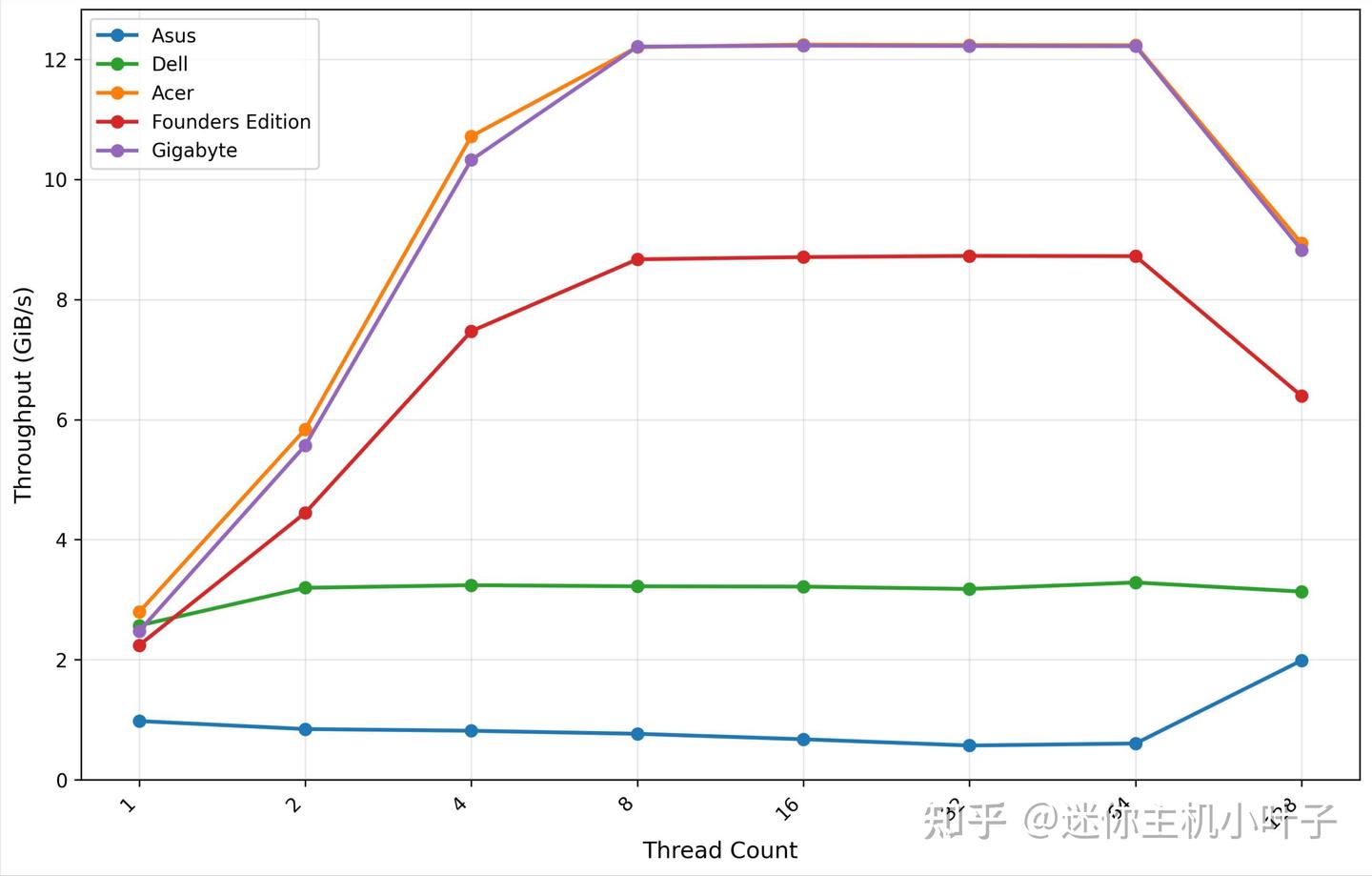
GDSIO 写入吞吐量 1M
从 GDSIO 写入吞吐量(1M 数据块)测试来看,宏碁平台表现出强劲的并发处理能力:单线程场景下,初始吞吐量达 2.79 GiB/s;随着线程数增加,吞吐量呈现显著提升趋势 —— 双线程时达到 5.84 GiB/s,四线程时进一步攀升至 10.72 GiB/s。
当线程数增加至 8 时,吞吐量达到 12.20 GiB/s,此时平台性能基本达到饱和状态;后续在 16 线程、32 线程、64 线程场景下,吞吐量分别稳定在 12.25 GiB/s、12.24 GiB/s、12.23 GiB/s,波动极小,展现出优异的性能稳定性。
但当线程数提升至 128 时,吞吐量出现明显下滑,降至 8.94 GiB/s,这一现象表明,在极高并发场景下,系统出现了资源争用或资源耗尽的情况,导致性能有所衰减。
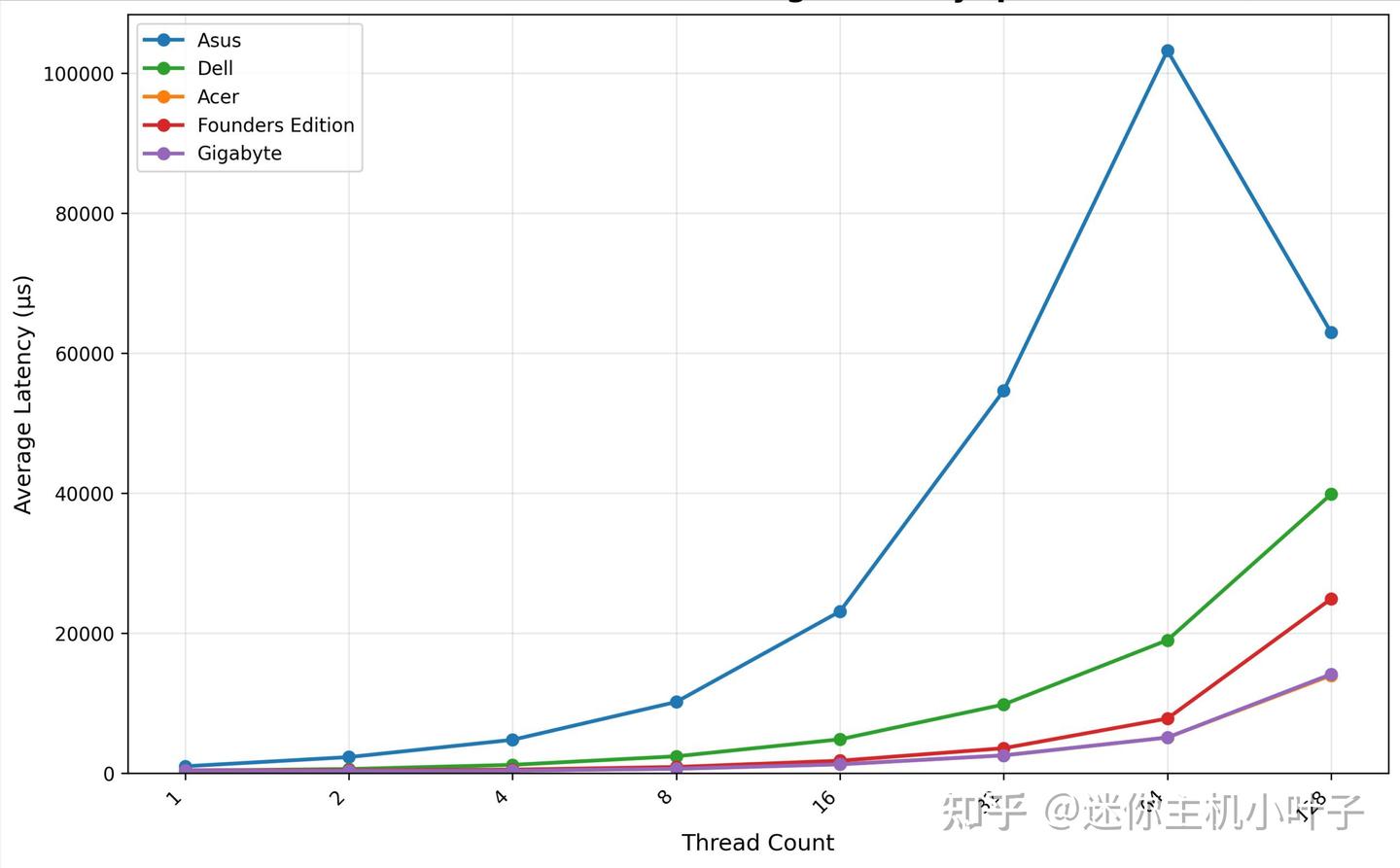
GDSIO 写入平均延迟 1M
从 GDSIO 写入平均延迟(1M 数据块)来看,宏碁平台的延迟表现依旧出色:单线程场景下,延迟约为 0.35 毫秒;双线程及四线程场景中,延迟保持在 0.33-0.36 毫秒区间,波动极小,展现出极强的稳定性。
随着并发量提升,延迟逐步上升:8 线程时延迟约为 0.7 毫秒,16 线程时达到 1.3 毫秒,32 线程时升至 2.6 毫秒,64 线程时进一步攀升至 5.2 毫秒。
即便在 128 线程的高并发场景下,延迟也仅为 13.98 毫秒,整体处于较低水平,与前文提到的吞吐量持续扩展特性相契合,充分体现了平台在高并发场景下的可靠性能。
结论
在本次 Spark 对比测试中,宏碁 Veriton GN100 展现出全场最优的整体散热表现。在高负载预填充转换与持续解码场景下,其 CPU 与 GPU 峰值温度均明显低于其他参测机型。
长时间满载运行时,该机核心温度并未像其他机型一样快速攀升至 80℃ 以上,而是始终维持在稳定且可控的区间,充分体现出其优秀的散热设计与成熟的功耗调校能力。

存储性能是宏碁 Veriton GN100 的另一大核心优势。该机搭载 4TB 三星 PM9E1 Gen5 SSD,在同组参测产品中,实现了最优的 GPU 直接存储(GPU Direct Storage)小块数据扩展能力。
在 16K 数据块场景下,其读写延迟在不同线程负载下始终维持在极低水平,吞吐量则呈平滑递增趋势,表现稳居同组测试机型首位;而在 100 万次传输测试中,该平台能够快速达到性能饱和,在中等并发水平下保持极具竞争力的性能上限,仅在高线程数负载下出现小幅性能衰减,整体表现符合高端 AI 工作站的应用需求。
在 vLLM 推理测试中,宏碁 Veriton GN100 的性能表现与更广泛的 Spark 生态系统高度契合,这与该机共享 GB10 基础架构的预期完全一致。
值得注意的是,其与同系列机型的性能差异,并非体现在原始计算输出层面,而是集中在高负载场景下的散热控制与存储传输表现上 —— 这也是其核心竞争力的关键所在。
Spark 产品线架构的一致性,有效确保了各机型推理性能的紧密衔接,而宏碁 Veriton GN100 在本轮测试中脱颖而出。
其长时间低温度稳定运行的特性,搭配强劲的第五代 NVMe SSD 存储性能,使其成为我们迄今为止测试过的、散热效率最优、存储性能最强的产品之一,完美适配数据密集型、高负载 AI 推理及相关工作场景。