
桌面上的AI超算:技嘉AI TOP ATOM轻体验
从近年来的硬件发展趋势可以清晰地观察到,AI能力正经历一场从云端向本地迁移的深刻变革。曾经只属于数据中心机架上的算力资源,如今正试图下沉到每个人的办公桌面上。然而,这条下沉之路此前并不平坦:开发者们要么受限于消费级显卡的显存瓶颈,只能运行一些体量较小、精度打折的模型;要么就必须在漫长的环境配置和层出不穷的代码报错中消耗大量精力。技嘉AI TOP ATOM的出现,某种程度上为这一困境提供了一个系统级的解决方案——它证明了我们期待中的“个人AI超级电脑”,确实已经具备了落地的形态。
第一次上手这台机器,它的体积确实让人有些意外。150mm见方、不到一瓶可乐的高度,就这么安静地放在显示器旁边,如果不看接口,你可能会以为它只是个设计考究的客厅播放器。整机没有夸张的灯条,也没有为了散热而张牙舞爪的开孔,取而代之的是银灰色的哑光金属机身和简洁的横栅格通风口。这种极简风格对于需要长时间专注工作的开发者或研究员来说,其实是一种心理上的减负——它明确告诉你,这是一台生产力工具,而不是光污染玩具。

当然,作为专业玩家,我们更关心的是藏在金属外壳下的那套配置。技嘉AI TOP ATOM的核心是NVIDIA的GB10 Grace Blackwell芯片,这并不是简单地把CPU和GPU焊在一块板上,而是通过NVLink-C2C技术实现了芯片间的超高速互联,双向带宽是传统PCIe 5.0的五倍左右。这意味着CPU和GPU可以像访问自家后院一样随意访问彼此的内存空间,这也是它真正区别于普通PC的地方:128GB的统一内存不再被割裂为“内存”和“显存”,而是作为一个整体被GB10芯片无缝调用。

对于跑大模型的老玩家来说,显存墙一直是最大的痛。但在这台AI TOP ATOM上,Blackwell GPU可以直接利用那128GB的统一内存。实测运行GLM-4.5-Air这个106B的模型时,在NVFP4精度下,显存占用稳定在69GB左右,整个过程流畅无阻。这意味着我们终于可以在本地桌面端跑起那些以前只能租云端A100才能玩的大家伙了。得益于Blackwell架构针对低精度计算的优化,它在FP4精度下能释放出高达1000 TOPS的算力,文本生成速度在千亿模型下也能维持在20 Tokens/s以上,这个吞吐量对于本地推理和调试来说,已经非常够用了。
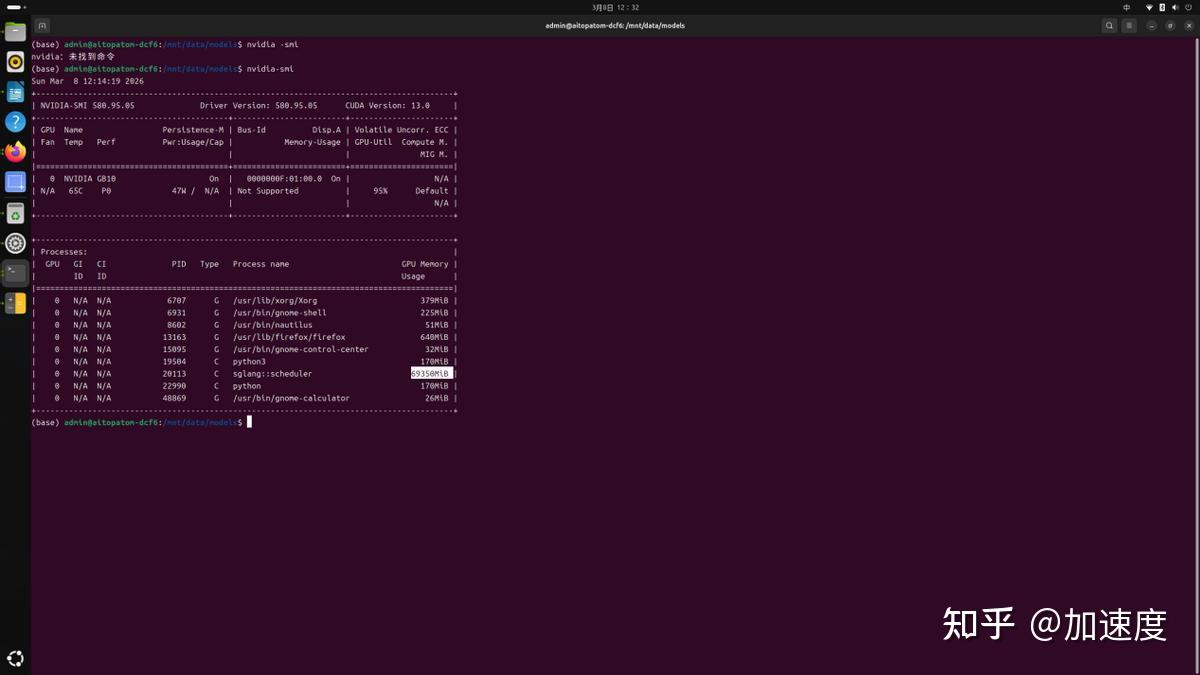
除了硬件底层的突破,这次让我觉得最省心的地方,其实是软件层面的“开箱即用”。机器自带的趋境智问系统平台,不需要你在Linux命令行里敲任何一行代码。开机后,在浏览器里输入IP地址加端口号,你就能看到一个完整的图形化AI工作台。
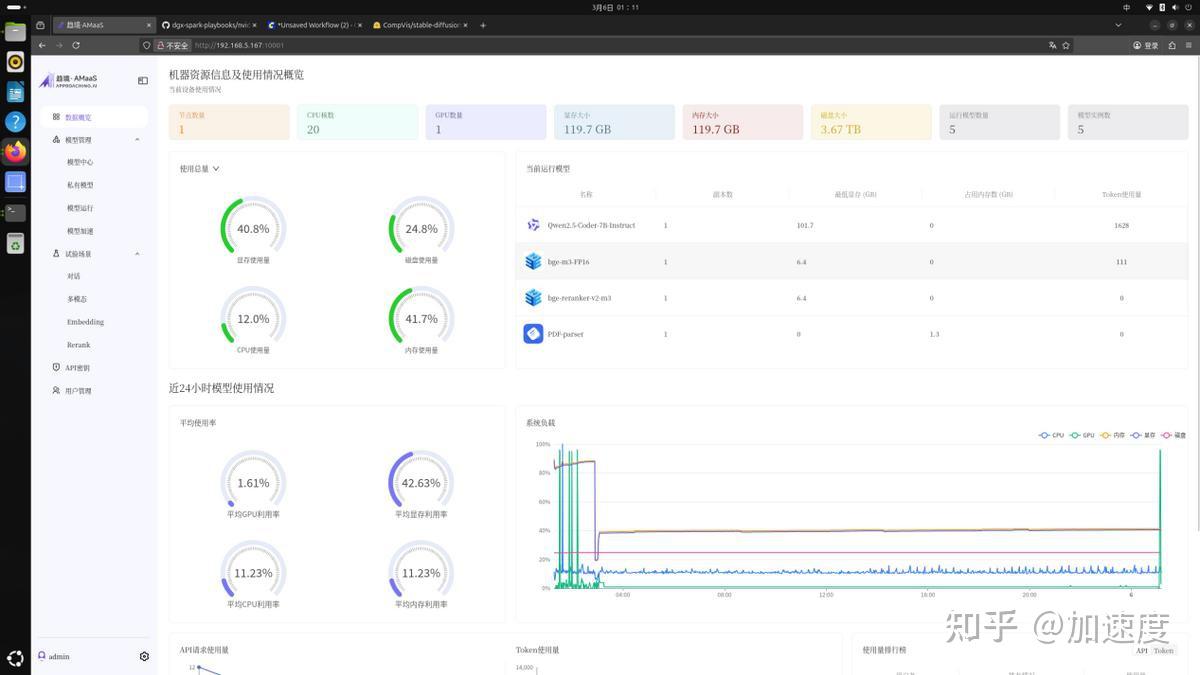
登录后台的第一感觉是“干净且专业”。趋境AMaaS管理平台把GPU负载、显存占用、Tokens消耗这些关键指标全都做成了可视化的仪表盘,谁在跑模型、吃了多少资源、有没有爆显存,一眼就能扫出来。对于团队协作或小型工作室来说,这个后台不仅能监控资源,还能管理多模型实例。
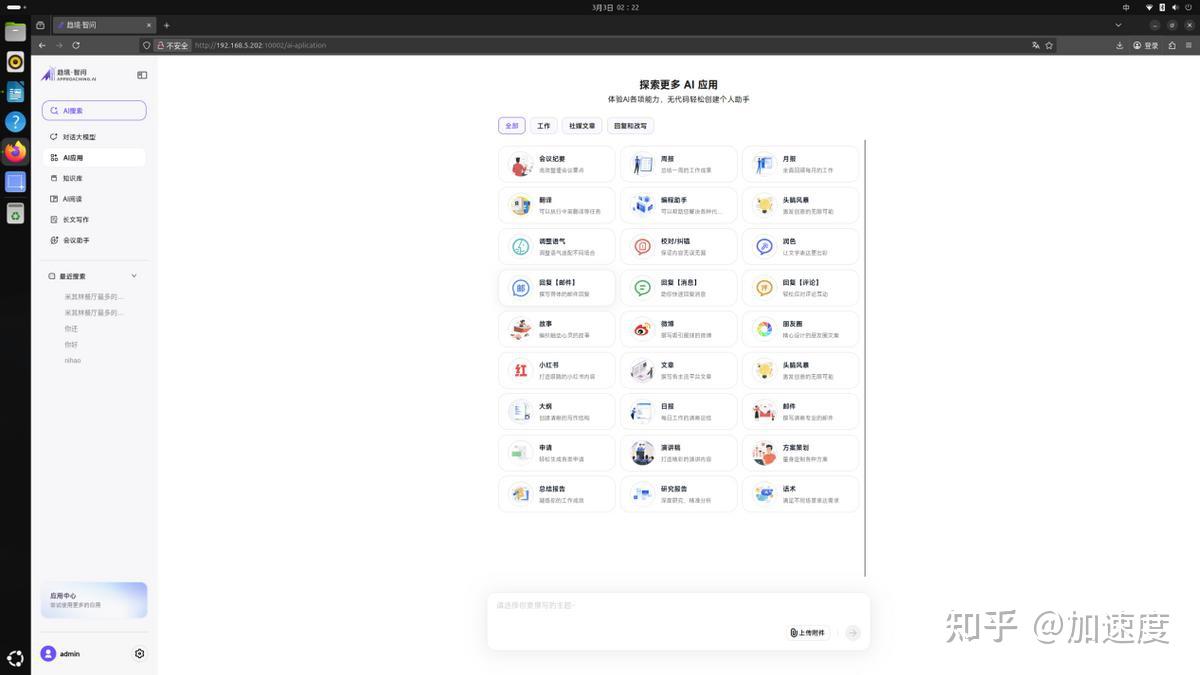
对于纯粹只想用AI干活的应用层用户,趋境智问平台的上手门槛几乎为零。它集成的不是那种只有一个对话框的简陋前端,而是一整套覆盖办公场景的工具链。你可以把它当做一个本地的知识库问答系统,上传文档让AI阅读并提炼摘要;也可以把它当成写作助手,帮你生成周报、润色文章、整理会议纪要。会议助手功能甚至能实时记录并提取行动项,这对于频繁开会的研发团队来说,确实是个生产力Buff。
在扩展性方面,技嘉也没有因为体积小而妥协。机身背部留了一个NVIDIA ConnectX-7接口,这是DGX SPARK同款的互联方案。如果你手头有两台AI TOP ATOM,可以直接通过这个接口把它们连起来,实现显存和算力的“池化”。这种“乐高式”的拼接玩法,对于需要跑4000亿参数以上超大模型的极客来说,是一种非常灵活的升级路径,不需要一次性投入高昂成本去买大型服务器,而是可以根据项目需求逐步堆叠算力。

这台机器并不是要去和那些动辄几千核的数据中心GPU拼绝对性能,而是在桌面级的功耗和体积限制下,给出了一个当前最优解——140W的TDP、240W的电源适配器、静音散热,却能跑通千亿参数大模型,还能支持4到8路的并发推理。一个小型研发团队完全可以用它作为内部的AI原型验证服务器,几个人同时接入调试模型,互不干扰;一个高校实验室可以用它做私有化的数据训练,不用担心核心数据上传云端带来的隐私风险;甚至一个独立开发者,也可以把它当成7x24小时待命的私人代码助手。
总之,技嘉AI TOP ATOM的特别之处在于,它把AI算力的门槛从“专业团队”拉低到了“个人开发者”。当你不再需要为了跑一个模型去学全套运维知识,不再需要为了数据安全去租昂贵的专属服务器,AI的本地化才算真正落到了实处。对于那些想要在AI赛道上动手实践,却又受限于环境配置和硬件成本的玩家来说,这台机器确实提供了一个近乎完美的起点。