带 npu 的 amd cpu,也就是所谓的 ai pc 是如何部署大模型的?
当全世界还在给GPT-4o交月租的时候,AMD直接放出话来:
笔记本里能够塞进1280亿参数的大模型,0.3秒就能够吐出一行诗。
要是你对“显存”这两个字有点了解,都会不自觉地摸钱包。
这听着就好像把三里屯放进你家冰箱,还保证不串味。
不要着急,更夸张的是,它仅仅只用一颗指甲盖大小的APU。

这事爆出来是1月6日深夜,拉斯维加斯CES展馆。
苏姿丰把一颗RyzenAIMax+395举过头顶,现场灯牌亮出“128BLOCALLY”。
没有融资额,没有PPT画饼,只有一句“2026Q2出货”,台下厂商瞬间把展区挤成春运。
听起来就像社区菜市场突然宣布卖火星土,到底图啥?

说白了,AMD把显存和内存缝成一块“统一粥”。
用256-bitLPDDR5X16.2GBs的勺子往CPU、GPU、NPU嘴里轮流喂,带宽干到2.7TBs。
问题出现,Intel的Ultra9285HX还是在用96EU的核显配置,NPU算力就只有13TOPS。
可对方直接就弄出了120TOPS的性能数据,这差距差不多都快到一台PS6那么大。
难道老黄就不担心游戏本市场会倒向别的地方?

2024年苹果M3Ultra也曾喊出“本地跑大模型”。
可实际测试的时候,70B模型一运行,风扇就转得比较快,续航还少了3.2小时。
它,是比较聪明的,不过128B参数光权重就有256GB,你那16GB板载内存能装下啥?
你说说看,资本家傻不傻,真觉得用户不装微信吗?

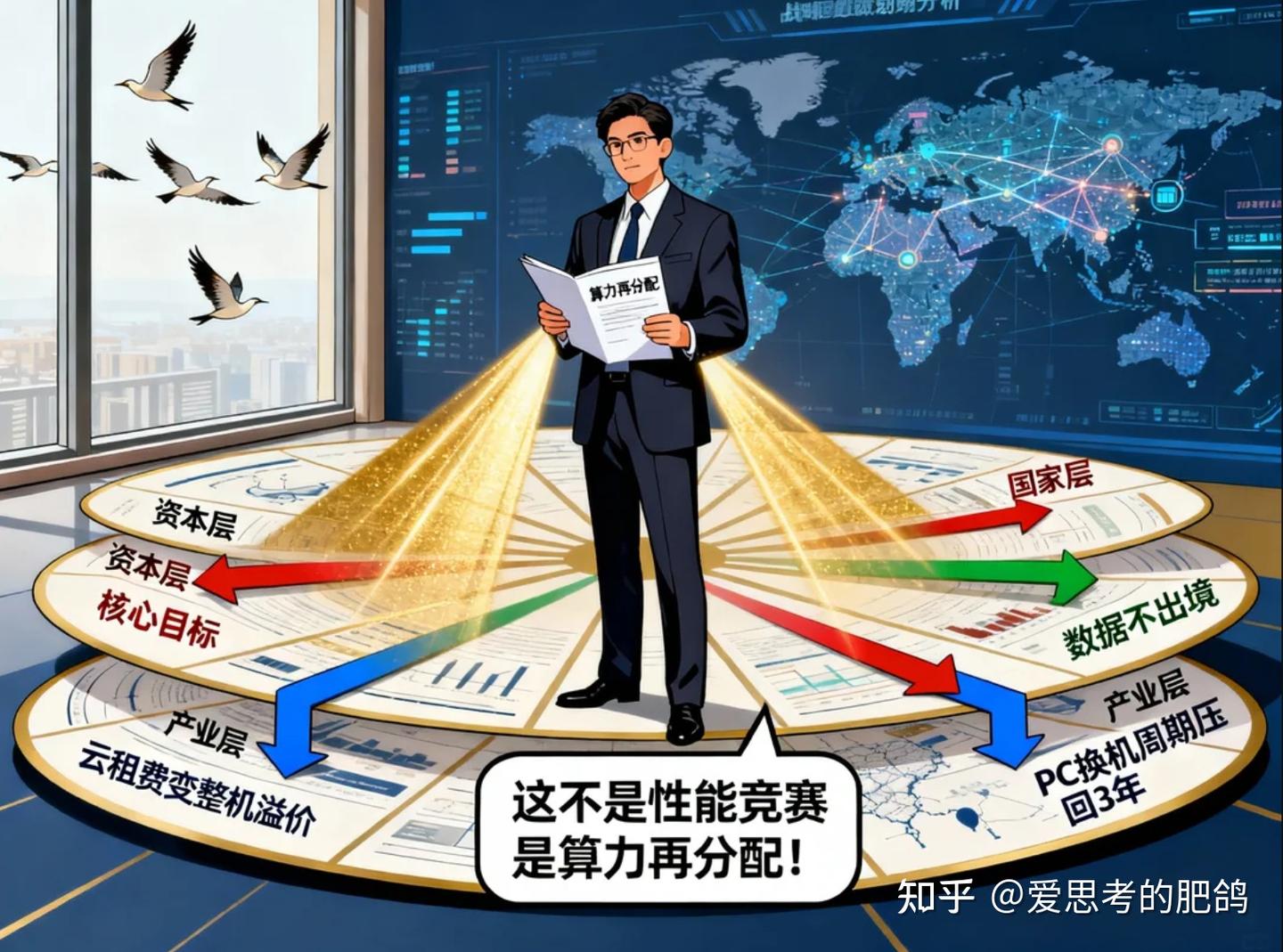
资本图的是把云租费变整机溢价,国家图的是数据不出境,产业图的是PC换机周期从6年压回3年。
这不是性能竞赛,而是算力再分配。
华硕ROG幻16抢先把Llama-3.1-128B跑通,离线写代码速度是每秒28个token,比MacBookProM4Max快1.7倍。
本地运行70B模型的时候,2025年高通骁龙8Gen4版的三星Book4温度热到了49.8℃,退货率一下子就升到31。
内存带宽每增加1TB/s,token的延迟就能缩短0.12秒,这里面的差别到底意味着啥?
可不要小看那小数点后面的数字,背后全都是实实在在的成本和收益。

未来三到五年,机场贵宾室里最响亮的就不再是抖音的声音,而是“本地AI渲染”设备散热风扇的嗡嗡声。
有看法预测,到2028年,一半轻薄笔记本会把风扇设计给去掉,反过来用相变散热片来压制高达130TOPS的算力发热。
本地大模型不是噱头,是下一次“宽带免费”时刻。

现实情况是,云算力赌桌开始收取佣金了,端侧芯片成了新的庄家。
内存涨价可能会先把你淘汰出局。
下次换电脑的时候,你还会问“显卡是多大的”吗?
如果喜欢,记得点个关注,点个赞,万分感谢!
声明:本文内容90%以上基于自己原创,少量素材借助AI辅助,但是所有内容都经过自己严格审核和复核。图片素材全部都是来源真实素材或AI原创。文章旨在倡导社会正能量,无低俗等不良引导,望读者知悉。