【Windows工具】批量OCR指定区域图片PDF自动识别内容重命名工具使用的基本操作方法和注意事项
「咕嘎批量OCR识别图片PDF多区域内容重命名导出表格系统」是一款 Windows 平台的绿色/安装版桌面工具,核心功能是对图片(JPG/PNG/TIFF)和扫描版PDF进行指定区域OCR文字识别,并支持:
- 按识别出的字段批量重命名文件
- 将多区域识别结果导出为 Excel/CSV 表格
- 支持固定版面坐标模板 + 动态关键字定位(非统一尺寸文件也可处理)
典型场景:发票/送货单/体检报告/合同/证件/简历等关键字段提取与归档。
✅ 核心功能
| 功能模块 | 说明 |
|---|---|
| 批量OCR识别 | 支持 JPG/PNG/TIFF 图片及扫描版 PDF(含多页),中英文混排识别 |
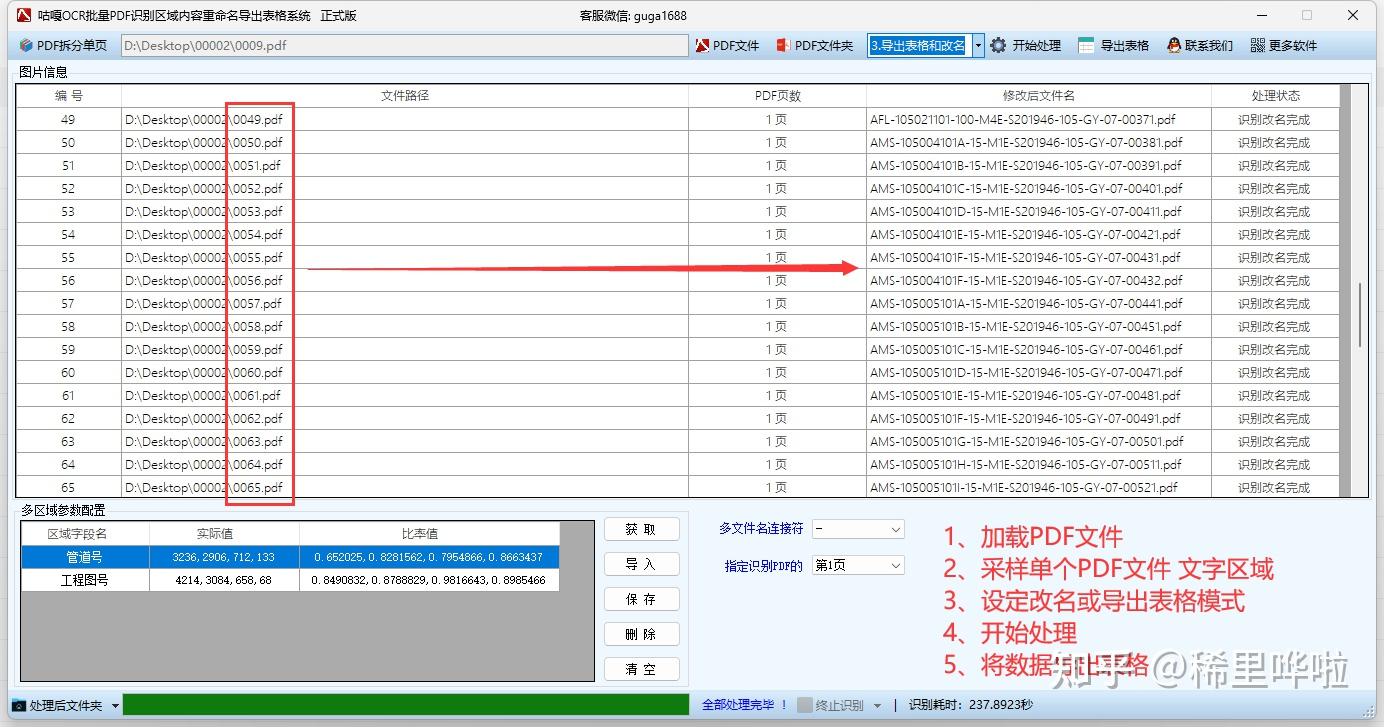
| 多区域框选 | 在样本文件上用矩形工具框选多个区域(如"发票号""日期""金额"),每个区域独立命名,作为Excel列名 |
| 按内容重命名 | 用识别结果拼接新文件名,如 发票号_日期_金额.pdf,支持连接符、 fallback 处理 |
| 导出Excel表格 | 自动生成结构化表格,含原文件名、新文件名、各区域文字、置信度等,长数字防科学计数法 |
| 动态区域识别 | 对尺寸不统一文件,可按关键字动态锁定区域位置,无需固定坐标 |
| 半自动模式 | 手动框选→核对→改名→自动跳转下一张,适合少量异常文件补处理 |
| 文件名二次修正 | 批量替换/删除内容、加前后缀(含序号)、删除指定字符类型、大小写转换等 |
| 模板复用 | 保存区域坐标模板,同规格文件直接调用,无需重复标注 |
📋 支持格式与环境
- 文件格式:JPG、PNG、TIFF、扫描版 PDF(图片型PDF);加密PDF需先解密
- 系统要求:Windows XP~Windows 11(官方主要提供 Windows 版,部分版本提及 macOS),建议 ≥4核 CPU、≥8GB 内存处理大批量文件
- 建议扫描分辨率:200–400 DPI,印刷体(宋体/黑体)识别率较高
🔧 标准操作流程
- 启动与选择模式
运行软件 → 选「图片处理模式」或「PDF处理模式」(标准尺寸统一文件用固定区域;不同尺寸用动态识别)
- 区域采样(关键步骤)
- 拖入一张样本文件预览
- 用矩形工具框选需识别区域 → 点「保存区域」→ 给区域命名(如"合同编号""签订日期")
- 可框选多个区域,系统记录坐标写入模板
- 批量导入文件
点击「导入文件夹」,载入待处理目录,可在列表剔除非目标文件
- 设置处理方式
- 区域识别重命名:按设定规则拼文件名
- 区域识别导表格:仅导出 Excel
- 两者同时:重命名 + 导出表格同步进行
- 开始处理 & 导出
点击「开始处理」→ 完成后可点「导出表格」查看/保存.xlsx
💼 典型应用场景
- 财务/行政:报销单、发票、送货单——提取金额/日期/单号,归档重命名+生成台账
- HR/招聘:简历PDF批量提取姓名/学历/年限,汇总候选人信息表
- 医疗:体检报告关键指标(血压/血糖等)批量提取建健康数据表
- 档案/合同管理:按合同编号或签署日期重命名扫描件,方便检索
- 物流/仓储:快递面单、发货单自动识别单号并重命名图片
⚠️ 注意事项
- PDF 若加密需先解密,否则无法读取
- 拍照文件注意光照均匀、避免倾斜严重阴影,可先简单纠偏提高识别率
- 大批量处理前建议先用 1~2 份文件测试区域坐标/动态规则是否正确
编辑于 2026-06-29 · 著作权归作者所有