为什么 Gen4 x4 的 SSD,速度居然和 Gen3 x8 差不多?
有一次排查 PCIe 问题,看到这样一段输出:
$ lspci -vv -s 01:00.0结果是:
LnkCap: Port #0, Speed 16GT/s, Width x16
LnkSta: Speed 16GT/s, Width x8第一反应其实有点懵。
板子设计目标明明是:
Gen4 x16
插槽也是 x16。
为什么最后只有 x8?
继续往下查,发现设备本身没问题。
链路也已经 Link Up。
但真正工作的时候,只协商到了:
Gen4 x8
也是从那次开始,我才意识到:
PCIe 里面其实一直在描述两件事情。
一件是:
每条 Lane 跑多快
另一件是:
一共有多少条 Lane
前者叫:
Generation
后者叫:
Link Width
很多人第一次接触 PCIe,很容易把这两个东西混在一起。
于是看到:
Gen4 x8
Gen3 x16
Gen5 x4总觉得 x16 一定比 x8 快。
其实不一定。
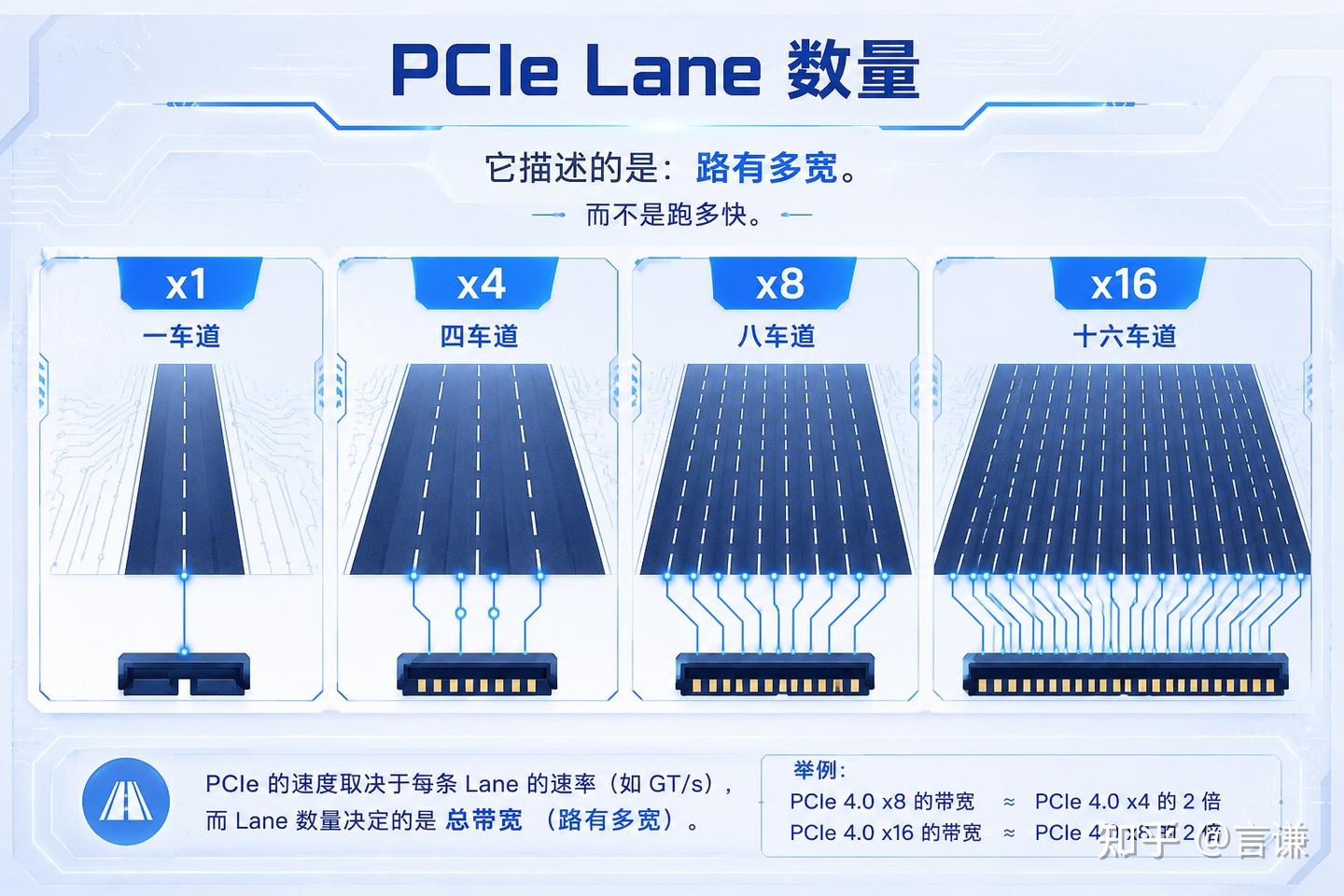
x1、x4、x8、x16,说的是几条 Lane
如果把 PCIe 看成高速公路。
Lane 就是一条车道。
x1:
CPU ================= Device
Lane0x4:
CPU ================= Device
=================
=================
=================x8:
CPU ================= Device
=================
...x16:
CPU ================================================= Device真正决定速度的,其实是 Gen
既然 x1、x4、x8、x16 表示的是车道数,
那么 Gen1、Gen2、Gen3、Gen4、Gen5,可以理解成限速。
每升级一代,单条 Lane 的速度都会提高:
Gen1:2.5 GT/s,约 250MB/s
Gen2:5 GT/s,约 500MB/s
Gen3:8 GT/s,约 1GB/s
Gen4:16 GT/s,约 2GB/s
Gen5:32 GT/s,约 4GB/s
Gen6:64 GT/s,约 8GB/s
所以,PCIe 的总带宽可以简单理解为:
总带宽 ≈ 单 Lane 带宽 × Lane 数
例如:
Gen3 x16 ≈ 1GB/s × 16 ≈ 16GB/s
而:
Gen4 x8 ≈ 2GB/s × 8 ≈ 16GB/s
两者的带宽其实差不多。
所以看到:
Gen3 x16
Gen4 x8
不要只盯着后面的 x16 和 x8。
Lane 数决定有几条车道,
而 Gen 决定每条车道跑多快。
很多时候,前面的 Gen,比后面的 x 几更重要。
这也是为什么:
x16 不一定比 x8 快。
一个 Gen4 x8 的设备,性能完全可以和 Gen3 x16 相当。
所以记住一句话就够了:
Gen 看车速,
x 几看车道。
总带宽 = 车速 × 车道数。

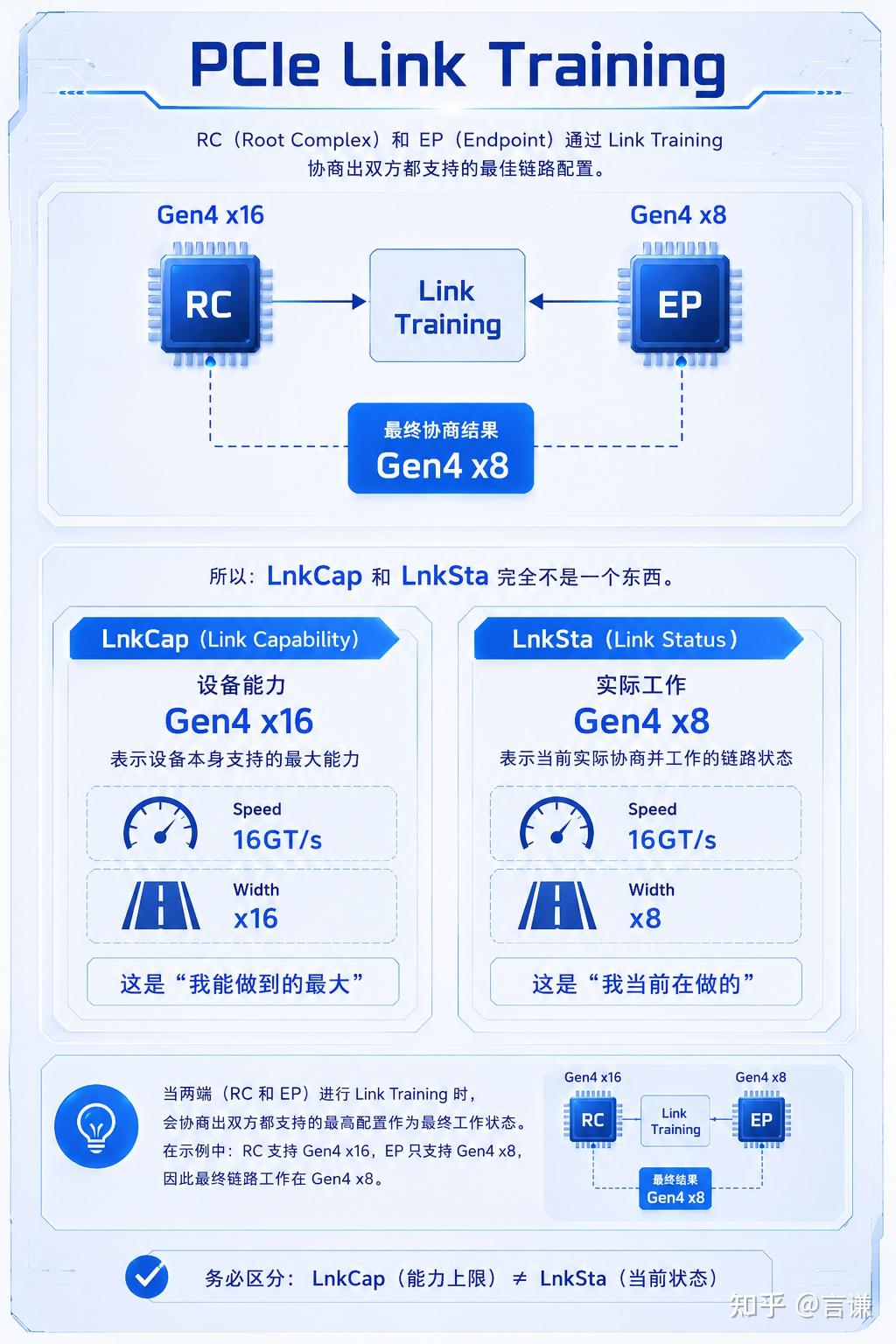
Link Up 的时候,Gen 和 Width 都会自动协商
很多人以为:
插上 x16 插槽,
就一定是 x16。
实际上并不是。
PCIe Link Training 的时候,双方会同时协商:
支持几条 Lane?
支持几代速度?
比如:
Root Complex:
Gen4 x16
Endpoint:
Gen4 x8
最终:
Gen4 x8
Linux 启动的时候,其实就能看到整个过程
高通平台上,经常可以看到:
[ 0.953472] qcom-pcie 1c00000.pcie: host bridge /soc@0/pcie@1c00000 ranges:
[ 1.028714] qcom-pcie 1c00000.pcie: Link up接着开始枚举:
[ 1.031582] pci 0000:00:00.0: PCI bridge to [bus 01-ff]
[ 1.035944] pci 0000:01:00.0: [144d:a808] type 00 class 0x010802随后:
[ 1.247315] nvme nvme0: pci function 0000:01:00.0
[ 1.255168] nvme nvme0: 8/0/0 default/read/poll queues整个过程看起来都很正常。
但真正关心性能的人,
最后一定会执行:
lspci -vv因为真正的答案在:
LnkSta里面。
Link Up,不代表没问题
做 PCIe bring-up 以后,
最怕看到的一句话其实是:
Link up
为什么?
因为:
Link Up,
只能说明链路起来了。
不代表:
速度对了;
Lane 对了;
性能对了。
例如:
[ 0.932715] qcom-pcie 1c00000.pcie: Link up大家都挺高兴。
结果:
lspci -vv发现:
LnkSta: Speed 2.5GT/s Width x1而预期明明是:
Gen4 x8
这意味着:
带宽差了三十多倍。
通常意味着:
• Equalization 没成功;
• 某几条 Lane 没通;
• REFCLK 不稳定;
• SI 不够;
• PHY 参数有问题。
做过 PCIe 调试的人,
看到:
Link up
第一反应往往是:
跑到 Gen 几?
几条 Lane?
有没有降速?
有没有 Recovery?
为什么 GPU 都是 x16,而 SSD 大部分都是 x4?
SSD 的瓶颈在 NAND。
Gen4 x4:
≈8GB/s已经接近闪存极限。
继续增加 Lane,
收益有限。
所以绝大部分 SSD 都是:
Gen3 x4
Gen4 x4
Gen5 x4而 GPU 不一样。
训练模型的时候:
CPU
↓
PCIe
↓
GPU传输:
- Tensor
- Feature Map
- DMA Buffer
- Texture
因此:
显卡基本都是:
Gen4 x16
或者
Gen5 x16例如:
03:00.0 VGA compatible controller
LnkSta: Speed 32GT/s Width x16单向理论带宽:
64GB/s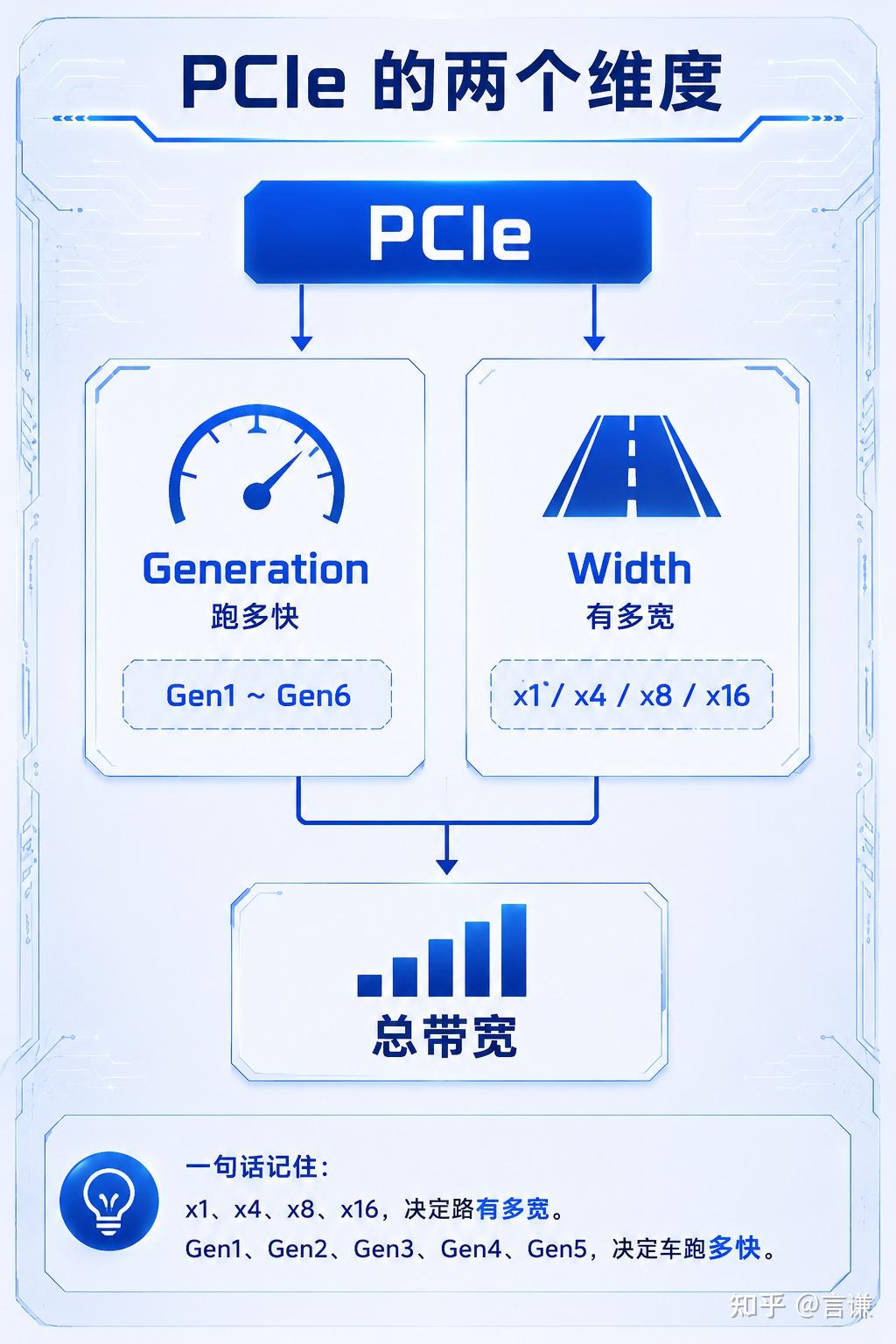
而真正跑出来多少,
不要看宣传页,
也不要看规格书。
看:
lspci -vv
尤其是:
LnkSta
因为:
Capability 是理想。
Status 才是现实。