
技嘉AI TOP ATOM:通电即用的私人AI超算
在本地化AI部署需求日益增长的当下,将数据中心级的算力压缩到桌面设备中,已成为硬件厂商的重要攻关方向。开发者和研究团队长期面临一个矛盾:既要足够算力,又不想占机房空间。技嘉AI TOP ATOM迷你桌面AI PC正好解决这个痛点。官方称其为“个人AI超级电脑”,把数据中心级AI能力压缩到桌面尺寸。作为NVIDIA DGX SPARK的定制版本,它不服务游戏玩家,专攻AI开发、模型微调和本地推理。下面从硬件、性能到软件生态,逐一判断是否值得入手。
从外观上看,AI TOP ATOM保持了高度内敛的工业风格。机身150mm见方、高50.5mm,比Mini ITX主机小得多,放桌面不占地。银灰色金属外壳加哑光磨砂,防指纹也辅助散热。出风口前置加侧置,横栅格配强化筋,风道隐蔽且安静,适合研发环境。接口方面,背面有3个USB 3.2 Type-C、1个240W供电Type-C、1个HDMI 2.1a、1个万兆网口,以及一个ConnectX-7接口。这个ConnectX-7是核心亮点,支持两台直连实现算力和显存翻倍,跑4000亿参数超大模型没问题,避免了一次性投入高昂服务器成本。左侧无开孔,右侧有肯辛通锁孔,底部橡胶垫脚加内凹槽辅助散热。240W Type-C电源适配器,整体紧凑、功能明确。

核心硬件层面,AI TOP ATOM搭载了NVIDIA GB10 Grace Blackwell芯片,这是一颗将CPU和GPU通过先进封装深度集成的Super Chip。GB10采用台积电3nm制程,TDP控制在140W左右,得以在桌面级散热条件下稳定运行。它使用2.5D CoWoS封装,将ARM架构的Grace CPU die与Blackwell GPU die封装在同一基板上,实现极低延迟的片间互连。GPU部分内置6144个CUDA核心,数量与消费级的GeForce RTX 5070一致,但由于Blackwell架构中新一代Tensor Core对FP4、FP8等低精度格式的专门优化,其在FP4精度下的AI算力可达1000 AI TOPS,能够流畅运行2000亿参数级别的模型。这一性能密度在传统桌面PC中非常罕见,通常只有机架式服务器才能提供。

技嘉AI TOP ATOM工作站的另一大亮点是内存架构。128GB LPDDR5X统一内存,CPU和GPU共享池子,省去了传统架构里数据来回拷贝的步骤。NVLink-C2C连接的双向带宽是PCIe 5.0的5倍,两者直接访问对方内存空间,彻底打破显存墙。实测跑GLM-4.5-Air 106B NVFP4模型,显存占用约68-69GB,只用了一半内存,运行流畅。CPU部分则是为20个Arm v9.2核心,10个Cortex-X925加10个Cortex-A725,共享32MB L3缓存。实测单核频率接近4.0GHz,Geekbench多核破万,数据预处理和逻辑控制能力不输中高端x86处理器,功耗更低,更适合紧凑机身散热。
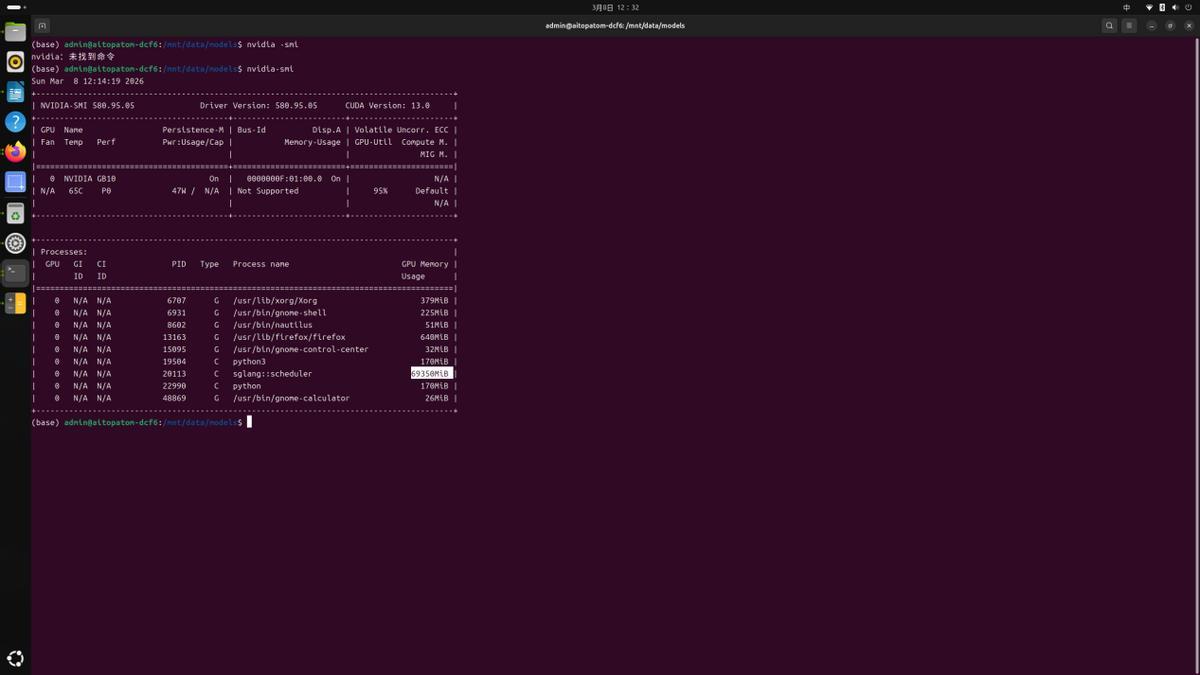
软件生态方面,技嘉与趋境科技合作,预集成了趋境智问系统,开机即用,免去复杂部署。内置智谱GLM-4.5-Air 106B大模型和“以存换算”推理引擎。操作系统基于Ubuntu改进,全图形化操作,Linux小白也能快速上手,浏览器登录即可查看GPU/CPU负载、显存占用、Tokens消耗等动态图表,支持按用户或应用查看资源排行榜,快速定位瓶颈。平台内置多款主流LLM和VLM模型,开箱即用,同时包含Embedding、Rerank、Parser、Audio等辅助模型。用户也可自行下载模型放入指定目录后导入,实测导入了Qwen 2.5 7B并成功运行。平台支持同时启动对话、Embedding和Rerank三个实例,系统自动分配资源互不干扰,单台设备就能跑通完整的检索增强生成链路。
性能方面,GLM-4.5-Air 106B NVFP4模型下,100字提示词输出22.58 Tokens/s,300字21.11 Tokens/s,500字20.61 Tokens/s。并发不超过4时,推理速度稳定在10 Tokens/s以上。更高并发需求可通过ConnectX-7接口组建集群扩展。同时支持自行部署Stable Diffusion、ComfyUI等热门应用,满足图像生成私有化需求。
技嘉AI TOP ATOM工作站直接把数据中心级的大模型能力搬到了桌面上。图形化操作界面让本地部署变得极其简单,几分钟就能跑起来,数据全程不上云,隐私安全彻底放心。成本比传统云服务器或大型工作站低出一大截。对于AI开发者、科研人员、小型工作室,或者任何需要私有化大模型的个人用户,这台小机器就是目前最值得入手的高效解决方案。非专业人士也能轻松上手,性能和扩展性都够硬,桌面级私有AI基础设施的首选。