
业界最快:Rambus推出新HBM4E内存控制器,4.1TB/s IC速度,大增60%
狂飙!
最先进的技术正在全力供应这些AI巨兽,半导体 IP 巨头 Rambus 今日宣布,正式推出行业领先的HBM4E 内存控制器 IP,旨在为下一代 AI 加速器提供史无前例的数据带宽。
根据 Rambus 公布的规格,HBM4E 标准相比于目前的 HBM4 实现了质的飞跃,其单引脚速率,从HBM4 的 10 Gbps 提升至16 Gbps;单个IC带宽达到了4.1TB/s,对比HBM4的2.56TB/s,增幅高达60%——一片采用8颗HBM4E芯片的AI加速器,其总带宽将来到惊人的32TB/s。
Rambus 明确表示,这款新型控制器将主要用于应对大语言模型(LLM)和高性能计算(HPC)的严苛需求。目前,Rambus 已开放 HBM4E 控制器 IP 的授权,早期开发客户已经可以介入设计。
HBM4E 将成为 NVIDIA Rubin Ultra GPU 以及 AMD MI500 系列加速器的“核心标配”。考虑到 2026 年显存供应的结构性短缺,这种更高效率、更高密度的存储技术,将成为巨头们拉开代差的关键。
虽然 2026 年的消费级硬件市场在挤牙膏和涨价中挣扎,但半导体上游公司正在紧锣密鼓地筹备 2027 年的爆发。届时,随着 HBM4E 技术的实装,AI 的推理速度和处理复杂任务的能力预计将再次迎来量变到质变的突破。
HBM4E意味着什么?像 Llama 3 这样的大模型,推理速度几乎直接受限于带宽,换上 HBM4E 后,在同样GPU性能的情况下,生成速度可能会直接翻倍甚至翻三到五倍。
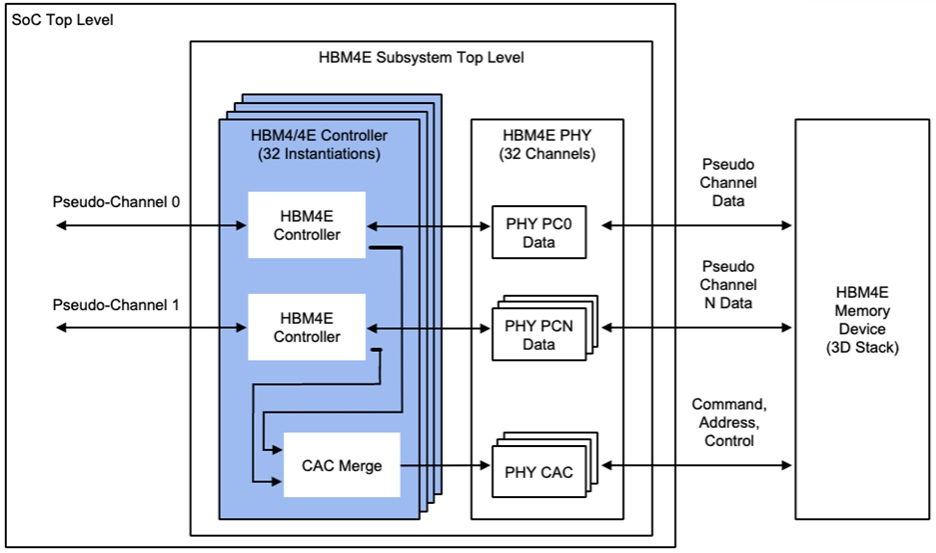
此外,HBM4E的堆叠层数更多,单堆栈容量可达 24GB-36GB,如果是安插在我们前不久还讨论过的H100 SXM5上,6颗HBM4E堆栈可以达到24.6TB/s,以及超大144~192GB大显存,这意味着至少可以放下一个8bit量化精度的120B大模型,一张卡就能顶住一个中小企业的需求。
往期阅读:微星 RTX 5090D v2 LIGHTNING 显卡曝光,难道还是要忍不住收割一手?