英伟达、AMD、Intel 三家显卡如何选择?
过去两年,人工智能产业进入高速发展阶段,从大模型训练,到企业私有化部署,再到生成式AI应用落地,行业竞争的核心曾经是:“谁的模型更大,谁的算力更强”。
但进入AI规模化应用阶段,一个更现实的问题正在浮现:模型能跑起来,不代表业务能稳定运行。
尤其是在AI客服、智能助手、知识库问答、内容生成等实际场景中,企业需要的是一套能够长期稳定运行、持续承载业务需求的AI基础设施。
而在这个阶段,显存容量、带宽能力以及专业级稳定性,正在成为企业选择GPU的重要指标。这也是NVIDIA RTX PRO 5000的72GB最近受到关注的原因。
01 PRO 5000 72GB显存
解决企业AI部署的新瓶颈
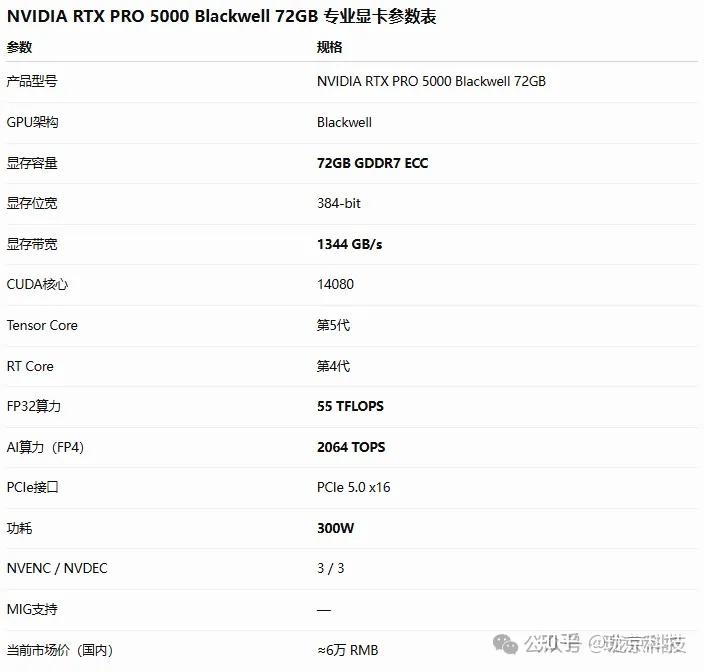
基于NVIDIA Blackwell架构打造的RTX PRO 5000,提供48GB与72GB两种显存版本,我们今天先聊聊72GB版本的。
72GB版本最大的价值,并不是单纯增加参数,而是为企业级AI应用提供更充足的运行空间。
在大模型推理场景中,显存承担的不只是模型权重加载。
它还需要承载:
- KV Cache缓存;
- 长上下文数据;
- 多用户并发请求;
- 多模态输入输出;
- 推理过程中的中间计算。
当模型越来越大、上下文越来越长时,显存不足往往会直接限制业务能力。
72GB大显存可以让模型拥有更大的运行余量,在长文本、高并发、多任务场景下减少频繁压缩和调度压力,让整体推理更加稳定。
尤其对于复杂MoE模型、多模态模型以及企业生产级AI服务,大显存带来的优势更加明显。
02 RTX PRO 5000:
不追求极限,而是追求长期价值
相比消费级旗舰显卡,例如RTX5090,RTX PRO5000的定位更加明确。
它并不是为了追求单一场景下的最高峰值性能,而是在:显存容量、稳定性、部署密度、功耗控制和长期运行成本之间寻找平衡。
RTX PRO 5000拥有:
72GB ECC专业显存;
300W级功耗设计;
面向企业环境优化的稳定性;
更灵活的工作站与服务器部署能力。
对于企业来说,真正重要的问题是,它能不能每天稳定运行?能不能支撑业务增长?能不能降低长期运维成本?
这正是RTX PRO系列与消费级GPU最大的区别。

03
从训练走向推理,AI产业正在改变
过去,AI竞争更多围绕训练展开。
企业关注:模型规模;训练速度;参数数量。
但现在,随着大模型进入真实业务场景,推理正在成为新的核心。
客服机器人、智能助手、知识库问答、内容生成、工业AI、数字员工……
这些应用都有一个共同特点:
需要长期运行,需要稳定响应,需要承载真实用户请求。
因此,企业需要的不只是“更快的GPU”,而是一套能够持续工作的AI基础设施。
RTX PRO 5000 Blackwell 72GB,正是针对这一趋势设计。
近期,珑京科技已经帮助数十家企业完成了双卡四卡八卡的RTX Pro5000服务器方案配置及交付落地。
04
适合哪些企业级AI场景?
AI推理平台
支持 DeepSeek、Qwen、LLaMA 等大模型本地部署。
结合 vLLM、TensorRT-LLM 等推理框架,可以构建企业级AI服务平台。
生成式AI与多模态创作
面对 Stable Diffusion、FLUX、ComfyUI,以及视频生成、4K/8K内容生产等任务,更大的显存意味着更复杂工作流的运行空间。
工业仿真与数字孪生
在 Omniverse数字孪生、自动驾驶仿真、CAE工程计算等领域,专业级GPU能够提供更稳定的计算支持。
高校科研与实验平台
包括分子动力学、CFD流体仿真、FEA工程分析以及AI实验环境,都需要兼顾计算能力和持续运行能力。

05
珑京科技整机方案与交付能力
未来几年,大模型不会停止增长,上下文会越来越长,模型结构会越来越复杂,企业AI应用会越来越深入。
而AI算力落地不仅需要一张高性能GPU,更需要成熟的整机方案与稳定的交付能力。基于持续测试验证与实际部署经验,珑京科技可针对RTX PRO 5000在不同AI应用场景中的性能表现进行优化评估,为客户提供从硬件选型、系统配置到部署实施的一站式支持,帮助企业更充分释放GPU算力价值。
目前,珑京科技作为算力应用方案与实施专家,可根据企业模型规模、业务需求、预算规划及部署周期,提供定制化AI工作站、推理服务器及本地化部署方案。
同时结合专业技术支持与完善交付流程,协助客户快速搭建稳定、高效、可持续扩展的AI算力基础设施。为大模型训练、推理服务、多模态应用及行业智能化场景提供可靠算力支撑,推动企业AI业务从“能运行”走向“稳定运行、高效创造价值”。