你为什么放弃了搜狗输入法?是因为什么,大家用什么输入法?
1 象码基础
声笔象码,简称象码,是一款结合了猛码、飞系和简拼优势的新型延迟顶功方案,是继猛码后声笔新系的又一新成员。相比猛码,象码不用数字编码因而操作更为方便,不用乱序因而更易学,同时又具有相似的大编码空间。与飞单一样,象码是二码起顶的声形码,但是拥有大得多的字词编码空间,重码率大大降低,而且没有了声笔字和前后取码的烦恼。与飞讯类似,象码又通过延迟来支持巨型词库。通过大写,也能获得类似飞码那样的词组输入体验。与简拼相似,象码还能不断补码来快速筛选重码。
象码的编码元素为声母、笔画和字根。声母和笔画(不含作为字根的笔画)与简拼和飞系完全一样。字根以米十五笔为基础来修改,改变了个别键位,增加了少量字根,具体如下:
- 顺折中的「竖钩」由折类调为竖类,以符合国标,如「小」的首笔;
- 调整字根键位:将「长」调整到 c 上,与「镸」放在一起;
- 增加简体字根:莫 k、奖无大 k、辛和辨旁 l、亡 w、食和饣u、⺗ x、矢g,以减少重码;
- 增加繁体字根:門、貝、車、馬、長、糹、飠、釒,以支持GBK字集。

上面的字根图有些归并字根没有列出,但在下面的字根表中列出了,请结合起来使用。

下面引述米+五笔字根表内含的五种记忆规则,以方便用户理解记忆。请注意将象码的字根调整加入其中。
- 笔画部件的分布:米字型+双折。
- 米字型规则的具体解释是:一横、二横、三横按米字横的走向设置在SDF横线上;一竖、二竖、三竖按竖的走向设置在EDC竖线上;一撇、二撇、三撇按撇的走向设置在RDX斜线上;一点(含捺)、二点、三点按捺的走向设置在WDV斜线上,从而构成“米”字型。
- “十”居于核心之中(下面跟随10个“十”,算是十字大荟萃)。“左折”代表任意的顺时针折,设置在 J 键上,其“形象代言字”为“”;“右折”代表任意的逆时针折,设置在 L 键上,其“形象代言字”为“乚”。
- 左手输入区域,米字型归纳了四种笔画部件,D键是其核心,“米”居于核心之中; 右手输入区域,双折归纳了第五种笔画“折”的两种类型,K键是其核心。就整个输入键盘而言,以上制定的规则,形成了"左米右十"的格局。如果将整个字根表视为一座城市,那么左手管辖的15键可视为主城区(米为中心环岛),右手管辖的11键可视为副城区(十为中心路口)。
- 部件与所在键位字母形托。如“口”在O键上,“丁”在 J 键上,“乚”在 L 键上,“阝”在 B 键上,“乂”在 X 键上,“尸”在 P 键 上,“匚”在 C 键上,“之”在 Z 键上,人”在 A 键上,“彐巾山”在 E 键上(如视力表),“丬”在 K 键上(不同角度旋转)。
- 部件与所在键位字母音托。如“木”在 M 键上,“石”在 S 键上,“亻”在 R 键上,“五”在 W 键上,“立”在 L 键上,“土田”在 T 键上,“九斤”在 J 键上,“西心”在 X 键上,“女乃”在 N 键上,“火禾”在 H 键上,“巴勹”在 B 键上,“广弓古”在 G 键上,“气 犭”在 Q 键上,“言也鱼 衤”在 Y 键上,“川镸寸虫”在 C 键上,“竹舟豸之”在 Z 键上。
- 形近、形似的字根聚集在同一键位上。如下表:

- 部件与所在键位字母意联,如:
- “金”处于A键位,因为金的化学符号是Au,且金的上部与A形同;
- “矢”与弓形影不离,随弓位于G上;
- “K”是老K管理的飞机场,飞机停在K位上,“十”为机头,“艹”为机身,“”为尾翼,“”为左翼,“廿”为右翼,“又”为起落架,“丬”为老K面壁思过,“䒑”为老K仰卧休息;
- “F”是王三服装店,

是衣架,目

是箱柜;
- “P”意味着停车场,“车”当然要停在P上;P键处于键盘的尾部,“尖尾”这一特征词共包含有“小大尸毛”4个字根;
- “U”是弯弯的月亮,有着口朝太空祈求福运的含义,“月”与两个小姐妹蜗居此处,修文习武,也算找到了安稳的归处;
凡此种种,均是从意联上考虑安置的,习练者也可用自己的思维方式来更好地锚定键位与字根的关联,增强记忆,这里权当抛砖引玉。
2 学习要点
在将输入方法之前,请用户务必注意以下学习要点,以便取得事半功倍的效果。
- 注意简码:在输入声母后,提示的内容除了首选字外,个别时候还有一个无理字母选择的字。在输入声母和首根后,除了提示首选字外,还会有两个无理标点字词和最多五个取末根首笔的字。这些字大都是高频的或常用的,不特别熟悉或注意的话,很容易打过头。虽然打过头后,仍然可以用全码打出,且在全码的时候还会提示简码,但是码长太长。初学的时候往往拆字也是最困难的,应该尽量减少拆分的压力。所以,在初学的时候,输入简码后,需要注意观察候选,只有在没出现所需字时,再输入后续编码,尽量有简就打简。当然,最好的办法是,对常用字词进行集中强化训练,达到一见到它们就知道是简码的程度,能够形成条件反射就更好了。
- 判断末根:象码的三简字和全码字都可能要用到末根的笔画。对于多根字来说,常常会有跳根的情况。这时,若顺序逐根去找末根,那么可能会非常困难。正确的做法是,不论几根字,都直接从尾部找末根,并养成这种习惯。
- 明确根数:象码的单字需要根据字根的多少来确定使用字母笔画还是符号笔画。在实际操作中,初学者可能会忽视了字根数而用错字母或符号,从而打不出想要的字,这时应该立刻意识到此问题,并及时加以纠正。
- 利用提示:为了减轻初学者的学习负担,象码进行了逐码提示。除了第一点中讲的简码提示外,在输入三码后,还提示了可能的四码字词和四码无理的单字。第四码无理的字只有49个,而且是很少使用的字,大不了输入有理的第四码后再选重就是了。再加上第二码无理的五个常用字,象码在字频前5000字内一共只有54个无理字。
3 输入方法
编码表示方法:s为声母,g为字根,b为字母笔画,f为符号笔画。
s = bpmfdtnlgkhjqxzcsrywv。声母的编码s取拼音的首字母,但若首字母为a e o,则改为v。这样,s的取值恰好为21个辅音字母。g = [a-z]。字根的编码使用了26个英文字母,字根的具体分布见本文第一节的字根图。注意,作为字根的笔画分为六类,因为折被细分成了顺折和逆折。但是,顺折中的竖左钩按国家标准归在了竖类。b = aeuio。字母笔画b采用了五个元音字母来表示横竖撇捺折,用于单根字和双根字的第三、四码,也用于选择重码和词组的扩展编码。不过,在选择重码时,排列的顺序为字母表序,即aeuio,且与笔画无关。f = ',/;.。符号笔画f仅用于第三码为非aeuio的多字根字的第四码,在编码中的加权使用率不足2%。n = 23789。数字笔画n仅用于词组的第四码。注意,在23789用于选重时并不表示笔画。
象码采用的单字拆分规则以照优先顺序有六条:结构完整、连续笔顺、根少优先、能连不交、能散不连、取大优先。
3.1 单字
3.1.1 全码
- 单根字:
sgbb,即声母 + 字根 + 首笔 + 次笔(只有一笔时,次笔为重复笔画)。例如,在「马 mqaa」中,首码m为声母,第二码q为字根「马」,第三码a为「马」的首笔「乛」,第四码a为「马」的次笔「乛」。 - 双根字:
sg¹b⁰b⁰,即声母 + 首根 + 末根首笔 + 末根次笔(只有一笔时,次笔为重复笔画)。例如,在「们mroi 」中,首码m为声母,第二码r首根「亻」,第三码o为末根「门」的首笔「丶」,第四码i为末根「门」的次笔「丨」。 - 多根字:
sg¹g²[b⁰|f⁰],即声母 + 首根 + 次根 + 末根首笔。 - 当第三码即次根g²的编码为
aeuio时,第四码末根首笔也必须用字母笔画aeuio来编码。例如,在「输 spai」中,首码s为声母,第二码p为首根「车」,第三码a为次根「人」,末码i为末根「刂」的首笔「丨」。 - 当第三码即次根g²的编码不为
aeuio时,第四码末根首笔则必须用符号笔画,;/.'来编码。
如果全码中单字是在重码位置,就用23789来选择,此时它们并不表示笔画,仅仅是无理选重。

当前页没出现的重码字,可用Tab和Shift+Tab前后翻页来查找。

3.1.2 简码
象码采用了出简让全的策略,所有的简码字都不是必须使用的,均可用全码输入,但是码长会大大增加。所以,建议用户在有能力时,尽量使用简码。在本文第6节中,列出了象码的所有简码字,以便用户进行集中查阅和练习。
- 一简字:21个,全码的首码加空格,例如「在z zxee」「人r rauo」「他t trai」「不b bsio」「一y ysee」「到d dsy;」。在没延迟时,
;',./可以顶一简字上屏,但延迟到第四码时则不能顶。 - 二简字:一般通过延迟顶上屏而省略空格,当然也可空格上屏。
- 有理字:541个,全码的前两码,例如「有yx yxia」「 面ms msf,」「 打dj djei」「来ls lsou」「耕gf gfp/」。
- 无理字:5个,首码为声母,次码无理,首码后有提示。这5个字是「款kb ktd/」「 怒nz nnk.」「仁rx rree 」「哦vh vov.」「五wz wwei」。
- 三简字:后接声母和标点时可以即时顶屏,当然也可空格上屏。但是,后接数字时不能顶屏,因为它们被作为多根字的第四码了。
- 有理字:1883个,全码的前两码加末根首笔的字母编码,例如「军jie jiea」「石sse sseu」「极jmo jmn.」「住zre zrw,」「资zdi zdui」。
- 标点字:797个,全码的首码加无理的标点,两码后有提示,例如「双sk; skao」「甚sk' skf'」「德dp; dpk.」「夺dp' dpei」「议yw; yww/」「育yw' ywy;」。

输入全码后,会在字的后码提示简码,以便用户逐步熟习和使用简码字,如下所示。


3.2 词组
3.2.1 全码
象码的全码词有100多万个,分为三种编码类型,支持自动调频和自动造词。
3.2.1.1 sgsn型
此型编码中的n为数字笔画,可以为23789,分别表示折横撇竖捺。数字笔画也可用符号笔画来代替,两者之间的对应关系为:2' 3, 7/ 8; 9.。符号笔画在电脑上更好操作,但是可能与单字产生冲突而成为重码。数字笔画在不会与单字冲突,而且在手机上可能更好操作。用户可以根据情况灵活使用这两种笔画编码方式。
- 二字词:22万多个,编码格式为
s¹g¹s⁰[n⁰|f⁰]b¹b¹b⁰b⁰b⁰b⁰,即取前两字的前两码和末字首笔的数字或符号形式,可再用字母笔画补充首字的前两笔和末字的前四笔,笔画不足则重复末笔。

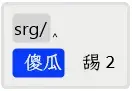
在输入「傻瓜」的时候,在上面的图1中,采用数字编码,没冲突,该词出现在首选。在图2中,采用符号编码,与单字「舓」产生冲突了。由于「舓」是字频前5000之后的生僻字,所以被挤到了次选,「傻瓜」则作为固定的简词安排在了首选。如果需要输入其它四码时重码的词,如「使馆」,则可开始补充首字的笔画。

在能记住「傻瓜」是简词的情况下,用户可以直接用srg7来输入其它重码的词,就能节约用键了。
如果重码词排在了当页的后面,也可用数字选择上屏。若在当页没有出现,那么可以继续补充笔画,最多可补笔画到码长为10为止。当然也可用Tab和Shift+Tab前后翻页来查找,但是效率低下,通常只在不清楚后续笔画时才使用。
- 三字词:30万多个,编码格式为
s¹s²s⁰[n⁰|f⁰]b¹b¹b²b²b⁰b⁰,即取前三字的首码和末字首笔的数字或符号形式,可再用字母笔画补充各字的前两笔。

在此例中,由于第四码时与单字没有冲突,所以不论用数字还是符号来输入第四码都没有区别,符号会直接被转换为数字显示。如果需要的是其它词,可继续追加字母笔画进行快速筛选,如下所示。



- 多字词:53万多个,编码格式为
s¹s²s³[n⁰|f⁰]b¹b¹b²b²b³b³,即取前三字的首码和末字首笔的数字或符号形式,可再用字母笔画补充前三字的前两笔。


3.2.1.1 sxSg型
在sxSg型编码中,又要区分二字词和三字词,不过它们共享同一编码空间。
- 二字词:编码格式为
s¹g¹S⁰g⁰b¹b¹b⁰b⁰b⁰b⁰,即取各字的前两码,但要大写第三码,可再用字母笔画补充首字的前两笔和末字的前四笔。


- 三字词:编码格式为
s¹s²S⁰s⁰b¹b¹b²b²b⁰b⁰,即取两字的首码和末字的前两码,但要大写第三码,可再用字母笔画补充各字的前两笔。


3.2.1.1 sssS型
多字词专用的编码为sssS型,其编码格式为s¹s²s³S⁰b¹b¹b²b²b³b³,即取前三字和末的首码,但要大写第四码,可再用字母笔画补充前三字的前两笔。以下是一个重码很多的极端例子,用足了10码。






由于已经用完了10码,若此时还要输入后面的重码词,那么就不能再用笔画过滤了,而必须用数字选择重码,或者移动光标来定位所要的重码词。
3.2.2 简码
象码的简码词是静态的,其编码固定不变,记住后是可以盲打的。
(1) 三码词:三码的简词只需要三键就可以输入,都是高频的二字词和三字词,共有1130个。对于前两码,两字词取首字前两码,三字词和多字词取前两字的声母。第三码取末字首笔的字母编码或者标点;',如下图中的「房间里」「扶着」「扶贫」。熟练的用户应该充分利用这种简词来提高输入效率。

(2) 四码词:四码的简词可用四键输入,一般是次高频的二、三、四字词,共有52000多个。四码简词的编码方式为全码的前四码,并规定第四码为符号笔画,如下例中的五个候选词。注意,四码简词没有收录由两个一、二简字构成的二字词,比如「一场」「目的」「连接」「学习」等,因为这类词打单字也只需要四键。

3.2.3 过滤
由于象码是单字二码起顶的输入方案,有大量的常用单字仅用两三键就可以输入,而且全码词至少需要五码,所以为了避免低效的词组输入,默认对词组进行了过滤。过滤强度可以设置的值有3、4、5或6。默认的过滤强度filter_strength设置为4,只有码长组合为22的二字词会被过滤掉。如果设置为3,那么就不会进行过滤,因为二字词的总码长不可能小于四。如果过滤强度设置为5,二字词的组成字码长为22、23、32这三种组合时就会被过滤掉。如果过滤强度设置为6,码长组合为33(但不含24和42)的二字词和码长组合为222的三字词都会被过滤掉。
3.3 编码空间
3.3.1 单字
- 单字全码:
21*26*26*5 = 70980,单字的空码位可用于输入常规词组。 - 单字简码:
21+21*26+21*26*5+21*26*2 = 4389,分配给一简字、二简字、标点字和三简字,其中的三码空间与简词共享。
3.3.2 词组
- 词组全码
- sxsn型:
21*26*21*5^7 = 895,781,250,所有常规词组共享。 - sxSx型:
21*26*21*26*5^6 = 4,658,062,500,二字词和三字词共享。 - sssS型:
21^4*5^6 = 3,038,765,625,单独分配给多字词。 - 词组简码:
- sx[b|f]型:
21*26*5+21*26*2 = 3822,分配给二字和三字简词,与简码字共享。 - sxsf型:
21*26*21*5 = 57330,分配给二、三、四字简词,全码字共享。
4 编码反查
在使用象码时,特别是在学习象码之初,有时会遇到不会打的字。怎么办呢?程序提供了丰富的反查手段,可以通过笔画和拼音来反查编码,还可以采用字海两分来反查和输入非 GBK 汉字。另外,还通过反查提供了临时拼音输入法。
4.1 拼音反查
在知道拼音而不知道字形时用 a 引导拼音反查,注意零声母要用 v 充当。
例如,要反查「常」字的编码,就在输入 a之后再输入它的拼音 chang,所以实际的输入为 achang,结果如下图所示。反查出「常」字的编码为 ce ceii,其中ce是简码,而ceii为全码。如果是多音字,那么就会有多个编码,如下图中的「长」字c和z两个声母。

对于零声母字,如「案」字,在反查时除了用 a 引导还需要在正常拼音的前面加 v,因为 an 是零声母音,所以实际的输入为 avan。在图中提示出的案v, viau,表示「案」字的简码为v,,而全码为viau。

4.2 笔画反查
在完全不知道读音的时候,直接用 aeuio 按顺序输入笔画进行反查,无需引导。
在下面的笔画反查的例子中,不用引导而直接输入 uuao 后,出现了以这四个笔画开头的字。第一项是反fh fhao,表示「反」字的编码为 fhao,而且有简码fh。

4.3 两分反查
通过 i 引导的拼音还支持用字海两分法来进行反查, 支持查找八万多汉字,一般用于反查难读而易于两分的字或者输入 GBK 以外的字。GBK 以外的字,声笔简码不提供正常编码,不能按正常方式输入,只能在两分查找到后选择输入。引导字母i可以理解为英文inquire(询问)的首字母,以便记忆。
下面是字海两分法查找的例子。第一个例子是反查「龖」字的编码,在输入到第二部分拼音的第一码时就出来了。第二个例子是通过输入「尸」和「水」的拼音来反查「尿」的编码,输入了两部分完整的拼音。
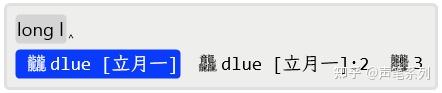

非 GBK 字集里的字是没有编码的,只能用两分法来输入,如上图中的「𮁆」字。
4.4 临时拼音
在一时半会想不起某个词中某个字的笔画,而这个字因为不常见又不方便用单字进行反查时,可以用 a 引导临时拼音来变相地输入词组或者查到该字的写法。
例如,「饕餮」可以用 ataotie 来查找和输入,而「耄耋」可以用 amaodie 来查找和输入。注意,用于引导的字母a是不会显示的。


5 编码变换
象码可以通过编码变换,将一简字组合起来输入,从而节约用键。编码变换通过Tab键来触发。
(1) 两个一简字的组合
例如,「个人」一词,虽然可以用g_r_来输入,其中下划线表示空格,然而更好的方式则是采用编码变换,用gr+Tab来输入,可以节约一次用键。
(2) 三个一简字的组合
例如,「一个人」虽然可以用y_g_r_来输入,但若用编码变换则可用ygr+Tab来输入,能够节约两个键。
6 简码字词列表
(省略)