
“西瓜书”+“南瓜书”笔记:第16章 强化学习
第16章 强化学习
16.1 任务与奖赏
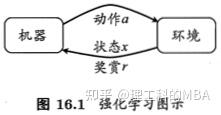
强化学习任务通常用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述:机器处于环境E中,状态空间为X,其中每个状态是机器感知到的环境的描述;机器能采取的动作构成了动作空间A。若某个动作
作用在当前状态x上,则潜在的转移函数P将使得环境从当前状态按某种概率转移到另一个状态;在转移到另一个状态的同时,环境会根据潜在的“奖赏”(reward)函数R反馈给机器一个奖赏。总和起来,强化学习任务对应了四元组
,其中
指定了状态转移概率,
指定了奖赏;在有的应用中,奖赏函数可能仅与状态转移有关,即
。
需注意”机器“与”环境“的界限。总之,在环境中状态的转移、奖赏的返回是不受机器控制的,机器只能通过选择要执行的动作来影响环境,也只能通过观察转移后的状态和返回的奖赏来感知环境。
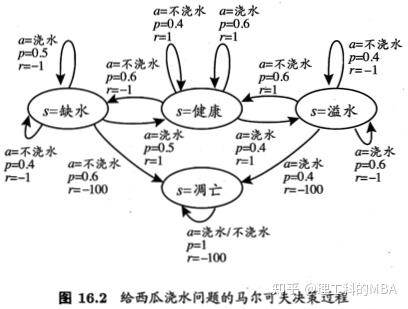
机器要做的是通过在环境中不断地尝试而学得一个”策略“(policy),根据这个策略,在状态x下就能得知要执行的动作
。策略有两种表示方法:一种是将策略表示为函数
,确定性策略常用这种表示;另一种是概率表示
,随机性策略常用这种表示,
为状态x下选择动作a的概率,这里必须有
。
策略的优劣取决与长期执行这一策略后得到的累积奖赏。在强化学习中,学习的目的就是要找到能使长期累积奖赏最大化的策略。长期累积奖赏有多种计算方式,常用的有”T步累积奖赏“和”
累积奖赏”
,其中
表示第t步获得的奖赏值,
表示对所有随机变量求期望。
在强化学习中并没有监督学习中的有标记样本(即“示例-标记”对),换言之,没有人直接告诉机器在什么状态下应该做什么动作,只有等到最终结果揭晓,才能通过“反思”之前的动作是否正确来进行学习。因此,强化学习在某种意义上可看作具有“延迟标记信息”的监督学习问题。
16.2 K-摇臂赌博机
16.2.1 探索与利用
与一般监督学习不同,强化学习任务的最终奖赏是在多步动作之后才能观察到,这里我们不妨先考虑比较简单的情形:最大化单步奖赏,即仅考虑一步操作。需注意的是,即便在这样的简化情形下,强化学习仍与监督学习有显著不同,因为机器需要通过尝试来发现各个动作产生的结果,而没有训练数据告诉机器应当做哪个动作。
欲最大化单步奖赏需考虑两个方面:一是需知道每个动作带来的奖赏,二是要执行奖赏最大的动作。若每个动作对应的奖赏是一个确定值,那么尝试一遍所有的动作便能找出奖赏最大的动作。然而,更一般的情形是,一个动作的奖赏值是来自于一个概率分布,仅通过一次尝试并不能确切地获得平均奖赏值。
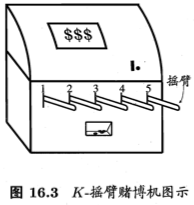
实际上,单步强化学习任务对应了一个理论模型,即“K-摇臂赌博机”(K-armed bandit)。K-摇臂赌博机有K个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。
若仅为获知每个摇臂的期望奖赏,则可采用“仅探索”(exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为奖赏期望的近似估计。若仅为执行奖赏最大的动作,则可采用“仅利用”(explotiation-only)法:按下目前最优的(即到目前为止平均奖赏最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个。显然,“仅探索”法能很好地估计每个摇臂的奖赏,却会失去很多选择最优摇臂的机会;“仅利用”法则相反,它没有很好地估计摇臂期望奖赏,很可能经常选不到最优摇臂。因此,这两种方法都难以使最终的累积奖赏最大化。
事实上,“探索”(即估计摇臂的优劣)和“利用”(即选择当前最优摇臂)这两者是矛盾的,因为尝试次数(即总投币数)有限,加强了一方则会自然削弱另一方,这就是强化学习所面临的“探索-利用窘境”(Exploration-Exploitation dilemma)。显然,欲累积奖赏最大,则必须在探索与利用之间达成较好的折中。
16.2.2 ![\epsilon]() -贪心
-贪心
-贪心法基于一个概率来对探索和利用进行折中:每次尝试时,以
的概率进行探索,即以均匀概率随机选取一个摇臂:以
的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个)。
令记录摇臂k的平均奖赏。若摇臂k被尝试了n次,得到的奖赏为
,则平均奖赏为
若直接根据式(16.1)计算平均奖赏,则需记录n个奖赏值。显然,更高效的做法是对均值进行增量式计算,即每次尝试一次就立即更新。不妨用下标来表示尝试的次数,初始时
。对于任意的
,若第n-1次尝试后的平均奖赏为
,则在经过第n次尝试获得奖赏
后,平均奖赏应更新为
这样,无论摇臂被尝试多少次都仅需记录两个值:已尝试次数n-1和最近平均奖赏。

若摇臂奖赏的不确定性较大,例如概率分布较宽时,则需更多的探索,此时需要较大的值;通常令
取一个较小的常数,如0.1或0.01。然而,若尝试次数非常大,那么在一段时间后,摇臂的奖赏都能很好地近似出来,不再需要探索,这种情形下可让
随着尝试次数的增加而逐渐减小,例如令
。
16.2.3 Softmax
Softmax算法基于当前已知的摇臂平均奖赏来对探索和利用进行折中。若各摇臂的平均奖赏相当,则选取各摇臂的概率也相当;若某些摇臂的平均奖赏明显高于其他摇臂,则它们被选取的概率也明显更高。
Softmax算法中摇臂概率的分配是基于Boltzmann分布
其中,记录当前摇臂的平均奖赏;
称为“温度”,
越小则平均奖赏高的摇臂被选取的概率越高。
趋于0时Softmax将趋于“仅利用”,
趋于无穷大时Softmax则将趋于“仅探索”。

-贪心算法与Softmax算法孰优孰劣,主要取决于具体应用。
对于离散状态空间、离散动作空间上的多步强化学习任务,一种直接的办法是将每个状态上动作的选择看作一个K-摇臂赌博机问题,用强化学习任务的累积奖赏来代替K-摇臂赌博机算法中的奖赏函数,即可将赌博机算法用于每个状态:对每个状态分别记录各动作的尝试次数、当前平均累积奖赏等信息,基于赌博机算法选择要尝试的动作。然而这样的做法有很多局限,因为它没有考虑强化学习任务马尔可夫决策过程的机结构。
16.3 有模型学习
考虑多步强化学习任务,暂且先假定任务对应的马尔可夫决策过程四元组均为已知,这样的情形称为“模型已知”,即机器已对环境进行了建模,能在机器内部模拟出与环境相同或近似的状况。在已知模型的环境中学习称为“有模型学习”(model-based learning)。此时,对于任意状态x,x'和动作a,在x状态下执行动作a转移到x‘状态的概率
是已知的,该转移所带来的奖赏
也是已知的。为了便于讨论,不妨假设状态空间X和动作空间A均为有限。
16.3.1 策略评估
在模型已知时,对任意策略能估计出该策略带来的期望累积奖赏。令函数
表示从状态x出发,使用策略
所带来的累积奖赏;函数
表示从状态x出发,执行动作a后再使用策略
带来的累积奖赏。这里的
称为“状态值函数”(state value function),
称为“状态-动作值函数”(state-action value function),分别表示制定“状态”上以及指定“状态-动作”上的累积奖赏。
由累积奖赏的定义,有状态值函数
为叙述简洁,后面在涉及上述两种累积累积奖赏时,就不再说明奖赏类别,读者从上下文应能容易地判知。令表示表示其实状态,
表示其实状态上采取的第一个动作;对于T步累积奖赏,用下标t表示后续执行的步数。我们有状态-动作值函数
由于MDP具有马尔可夫性,即系统下一时刻的转态仅由当前时刻的状态决定,不依赖于以往任何状态,于是值函数有很简单的递归形式。对于T步累积奖赏有
类似的,对折扣累积奖赏有
需注意的是,正是由于P和R已知,才可以进行全概率展开。

读者可能已发现,用上面的递归等式来计算值函数,实际上就是一种动态规划算法。对于,可设想递归一直进行下去,直到最初的起点;换言之,从值函数的初始值
出发,通过一次迭代能计算出每个状态的但不奖赏
,进而从单步奖赏出发,通过一次迭代计算出两步累积奖赏
,······对于T步累积奖赏,只需迭代T轮就能精确地求出值函数。
对于,由于
在t很大时趋于0,因此也能使用类似的算法,只需将图16.7算法的第3行根据式(16.8)进行替换。此外,由于算法可能会迭代很多次,因此需设置一个停止准则。常见的是设置一个阈值
,若在执行一次迭代后值函数的改变小于
则算法停止;相应的,图16.7算法第4行中的
需替换为
有了状态值函数V,就能直接计算出状态-动作值函数
16.3.2 策略改进
对于某个策略的累积奖赏进行评估后,若发现它并非最优策略,则当然希望对其进行改进。理想的策略应能最大化累积奖赏
一个强化学习任务可能有多个最优策略,最优策略所对应的值函数称为最优值函数,即
注意,当策略空间无约束时式(16.12)的才是最优策略对应的值函数,例如对离散状态空间和离散动作空间,策略空间是所有状态上所有动作的组合,共有$|A|^{|X|$种不同的策略。若策略空间有约束,则违背约束的策略是“不合法”的,即便其值函数所取得的累积奖赏值最大,也不能作为最优值函数。
由于最优值函数的累积奖赏已达最大,因此可对前面的Bellman等式(16.7)和(16.8)做一个改动,即将对动作的求和改为最优:
换言之,
代入式(16.10)可得最优状态-动作值函数
上述关于最优值函数的等式,称为最优Bellman等式,其唯一解是最优值函数。
最优Bellman等式揭示了非最优策略的改进方式:将策略选择的动作改变为当前最优的动作。显然,这样的改变能使策略更好。不妨令动作改变后对应的策略为,改变动作的条件为
,以
折扣累积奖赏为例,由式(16.10)可计算出递推不等式
值函数对于策略的没一点改进都是单调递增的,因此对于当前策略,可放心地将其改进为
直到与
一致、不再发生变化,此时就满足了最优Bellman等式,即找到了最优策略。
16.3.3 策略迭代与值迭代
由前两小节我们知道了如何评估一个策略的值函数,以及在策略评估后如何改进至获得最优策略。显然,将这两者结合起来即可得到求解最优解的方法:从一个初始策略(通常是随机策略)出发,先进行策略评估,然后改进策略,评估改进的策略,再进一步改进策略,······不断迭代进行策略评估和改进,直到策略收敛、不再改变为止。这样的做法称为“策略迭代”(policy iteration)。

由式(16.16)可知策略改进与值函数改进是一致的,因此可将策略改进视为值函数改进,即由式(16.13)可得
于是可得到值迭代(vaalue iteration)算法。

若采用折扣累积奖赏,只需将图16.9算法中第3行替换为
从上面的算法可看出,在模型已知时强化学习任务能归结为基于动态规划的寻优问题。与监督学习不同,这里并未涉及到泛化能力,而是为每一个状态找到最好的动作。
16.4 免模型学习
若学习算法不依赖于环境建模,则称为“免模型学习”(model-free learning)。
16.4.1 蒙特卡罗强化学习
在免模型情形下,策略迭代算法首先遇到的问题是策略无法评估,这是由与模型未知而导致无法做全概率展开。此时,只能通过在环境中执行选择的动作,来观察转移的状态和得到的奖赏。受K摇臂赌博机的启发,一种直接的策略评估替代方法是多次“采样”,然后求取平均累积奖赏来作为期望累积奖赏的近似,这称为蒙特卡罗强化学习。由于采样必须为有限次数,因此该方法更适合使用T步累积奖赏的强化学习任务。
另一方面,策略迭代算法估计的是状态值函数V,而最终的策略是通过转态-动作值函数Q来获得。当模型已知时,从V到Q有很简单的转换方法,而当模型未知时,这也会出现困难。于是,我们将估计对象从V转变为Q,即估计每一对“状态-动作”的值函数。
此外,在模型未知的情形下,机器只能是从一个起始转态(或起始状态集合)开始探索环境,而策略迭代算法由于需对每个状态分别进行估计,因此在这种情形下无法实现。因此,我们只能在探索的过程中逐渐发现各个状态并估计各状态-动作对的值函数。
综合起来,在模型未知的情形下,我们从起始状态出发,使用某种策略进行采样,执行该策略T步并获得轨迹
$$ $$
然后,对轨迹中出现的每一对状态-动作,记录其后的奖赏之和,作为该状态-动作对的一次累积奖赏采样值。多次采样得到多条轨迹后,将每个状态-动作对的累积奖赏采样值进行平均,即得到状态-动作值函数的估计。
可以看出,欲较好地获得值函数的估计,就需要多条不同的采样轨迹。然而,我们的策略有可能是确定性的,即对于某个状态只会输出一个动作,若使用这样的策略进行采样,则只能得到多条相同的轨迹。这与K摇臂赌博机的“仅利用”法面临相同的问题,因此可借鉴探索与利用折中的办法,例如使用-贪心法,以
的概率从所有动作中均匀随机选取一个,以
的概率选取当前最优动作。我们将确定性的策略
称为“原始策略”,在原始策略上使用
-贪心法的策略记为
对于最大化值函数的原始策略,其中
-贪心策略
中,当前最优动作被选中的概率是
,而每个非最优动作被选中的概率是
。于是,每个动作都有可能被选取,而多次采样将会产生不同的采样轨迹。
与策略迭代算法类似,使用蒙特卡洛法进行策略评估后,同样要对策略进行改进。前面在讨论策略改进时利用了式(16.16)揭示的单调性,通过换入当前最优动作来改进策略。对于任意原始策略,其
-贪心策略
仅是将
的概率均匀分配给所有动作,因此对于最大化值函数的原始策略
,同样有
,于是式(16.16)仍成立,即可以使用同样的方法来进行策略改进。

这里被评估与被改进的是同一个策略,因此称为“同策略”(on-policy)蒙特卡洛强化学习算法。算法中奖赏均值采用增量计算,每次采样出一条轨迹,就根据该轨迹涉及的所有“状态-动作”对来对值函数进行更新。
同策略蒙特卡罗强化学习算法最终产生的是-贪心算法。然而,引入
贪心是为了便于策略评估,在使用策略时并不需要
贪心;实际上我们希望改进的是原始(非
-贪心)策略。那么,能否仅在策略评估时引入
-贪心,而在策略改进时却改进原始策略呢?
这其实是可行的。不妨用两个不同的策略和
来产生采样轨迹,两者的区别在于每个“状态-动作对”被采样的概率不同。一般的,函数f在概率分布p下的期望可表达为
可通过从概率分布p上的采样来估计f的期望,即
若引入另一个分布q,则函数f在概率分布p下的期望也可等价地写为
上式可看作在分布q下的期望,因此通过在q上的采样
可估计为
回到我们的问题上来,使用策略的采样轨迹来评估策略
,实际上就是对累积奖赏估计期望
若改用策略的采样轨迹来评估策略
,则仅需对累积奖赏加权,即
其中和
分别表示两个策略产生第i条轨迹的概率。对于给定的一条轨迹
,策略
产生该轨迹的概率为
虽然这里用到了环境的转移概率,但式(16.24)中实际只需两个策略概率的比值
若为确定性策略而
是
的
-贪心策略,则
始终为1,
为
或
,于是就能对策略
进行评估了。

16.4.2 时序差分学习
时序差分(Temporal Difference,简称TD)学习则结合了动态规划与蒙特卡罗方法的思想,能做到更高效的免模型学习。
蒙特卡罗强化学习算法的本质,是通过多次尝试后求平均来作为期望累积奖赏的近似,但它在求平均时是“批处理式”进行的,即在一个完整的采样轨迹完成后再对所有的状态-动作对进行更新。实际上这个更新过程能增量式进行。对于状态-动作对,不妨假定基于t个采样已估计出值函数
,则在得到第t+1个采样
时,类似式(16.3),有
显然,只需给加上增量
即可。更一般的,将
替换为系数
,则可将增量项写作
。在实践中通常令
为一个较小的正数值
,若将
展开为每步累积奖赏之和,则可看出系数之和为1,即令
不会影响
是累积奖赏之和这一性质。更新步长
越大,则越靠后的累积奖赏越重要。
以折扣累积奖赏为例,利用动态规划方法且考虑到模型未知时使用状态-动作值函数更方便,由式(16.10)有
其中是前一次在状态x执行动作a后转移到的状态,
是策略
在
上选择的动作。
使用式(16.31),每执行一步策略就更新一次值函数估计,于是得到图16.12的算法。该算法由于每次更新值函数需知道前一步的状态(state)、前一步的动作(active)、奖赏值(reward)、当前状态(state)、将要执行的动作(action),由此得名为Sarsa算法。显然,Sarsa是一个同策略算法,算法中评估(第6行)、执行(第5行)的均为-贪心策略。
将Sarsa修改为异策略算法,则得到图16.13描述的Q-学习(Q-learning)算法,该算法评估(第6行)的是-贪心策略,而执行(第5行)的是原始策略。


16.5 值函数近似
前面我们一致假定强化学习任务是在有限状态空间上进行,每个状态可用一个编号来指代;值函数则是关于有限状态的“表格值函数”(tabular value function),即值函数能表示为一个数组,输入i对应的函数值就是数组元素i的值,且更改一个状态上的值不会影响其他状态上的值。然而,现实强化学习任务所面临的状态空间往往是连续的,有无穷多个状态。
一个直接的想法是对状态空间进行离散化,将连续状态空间转化为有限离散状态空间,然后就能使用前面介绍的方法求解。遗憾的是,如何有效地对状态空间进行离散化是一个难题,尤其是在对状态空间进行探索之前。
实际上,我们不妨直接对连续状态空间的值函数进行学习。假定状态空间为n维实数空间,此时显然无法用表格值函数来记录状态值。先考虑简单情形,即值函数能表达为状态的线性函数
其中为状态向量,
为参数向量。由于此时的值函数难以像有限状态那样精确记录每个状态的值,因此这样值函数的求解被称为值函数近似(value function approximation)。
我们希望通过式(16.32)学得的值函数尽可能近似真实值函数,近似程度常用最小二乘误差来衡量:
其中表示由策略
所采样而得的状态上的期望。
为了使误差最小化,采用梯度下降法,对误差求负导数
于是可得到对于单个样本的更新规则
我们并不知道策略的真实值函数,但可借助时序差分学习,基于
用当前估计的值函数代替真实值函数,即
其中是下一时刻的状态。
需要注意的是,在时序差分学习中需要状态-动作值函数以便获取策略。这里一种简单的做法是令作用于表示状态和动作的联合向量上,例如给状态向量增加一维用于存放动作编号,即将式(16.32)中的
替换为
;另一种做法是用0/1对动作选择进行编码得到向量
,其中“1”表示该动作被选择,再将状态向量与其合并得到
,用于替换式(16.32)中的
。这样就使得线性近似的对象为状态-动作值函数。
基于线性值函数近似来替代Sarsa算法中的值函数,即可得到图16.14的线性值函数近似Sarsa算法。类似地可得到线性值函数近似Q-学习算法。显然,可以容易地用其他学习方法来代替式(16.32)中的线性学习器,例如通过引入核方法实现非线性函数近似。

16.6 模仿学习
在强化学习的经典任务设置中,机器所能获得的反馈信息仅有多步决策后的累积奖赏,但在现实任务中,往往能得到人类专家的决策过程范例,例如在种瓜任务上能得到农业专家的种植过程的范例。从这样的范例中学习,称为“模仿学习”(imitation learning)。
16.6.1 直接模仿学习
强化学习任务中多步决策的搜索空间巨大,基于累积奖赏来学习多步之前的合适决策非常困难,而直接模仿人类专家的“状态-动作对”可显著缓解这一困难,我们称其为“直接模仿学习”。
假定我们获得了一批人类专家的决策轨迹数据,每条轨迹包含状态和动作序列
其中为第i条轨迹中的转移次数。
有了这样的数据,就相当于告诉机器在什么状态下应选择什么动作,于是可利用监督学习来学得符合人类专家决策轨迹数据的策略。
我们可以将所有轨迹上的所有“状态-动作对”抽取出来,构造出一个新的数据集合
即把状态作为特征,动作作为标记;然后,对这个新构造出的数据集合D使用分类(对与离散动作)或回归(对于连续动作)算法即可学得策略模型。学得的这个策略模型可作为机器进行强化学习的初始策略,再通过强化学习方法基于环境反馈进行改进,从而获得更好的策略。
16.6.2 逆强化学习
在很多任务中,设计奖赏函数往往相当困难,从人类专家提供的范例数据中反推出奖赏函数有助于解决该问题,这就是逆强化学习(inverse reinforcement learning)。
在逆强化学习中,我们知道状态空间X、动作空间A,并且与直接模仿学习类似,有一个决策轨迹数据。逆强化学习的基本思想是:欲使机器做出与范例一致的行为,等价于在某个奖赏函数的环境中求解最优策略,该最优策略所产生的轨迹与范例数据一致。换言之,我们要寻找某种奖赏函数使得范例数据是最优的,然后即可使用这个奖赏函数来训练强化学习策略。
不妨假设奖赏函数能表达为状态特征的线性函数,即,于是,策略
的累积奖赏可写为
即状态向量加权和的期望与系数的内积。
将状态向量的期望简写为
。注意到获得
需求取期望。我们可使用蒙特卡罗方法通过采样来近似期望,而范例轨迹数据集恰可看作最优策略的一个采样,于是,可将每条范例轨迹上的状态加权求和再平均,记为
。对于最优奖赏函数
和任意其他策略产生的
,有
若能对所有策略计算出,即可解出
显然,我们难以获得所有策略,一个较好的办法是从随机策略开始,迭代地求解更好的奖赏函数,基于奖赏函数获得更好的策略,直至最终获得最符合范例轨迹数据集的奖赏函数和策略。注意在求解更好的奖赏函数时,需将式(16.39)中对所有策略求最小改为对之前学得的策略求最小。